 697
697 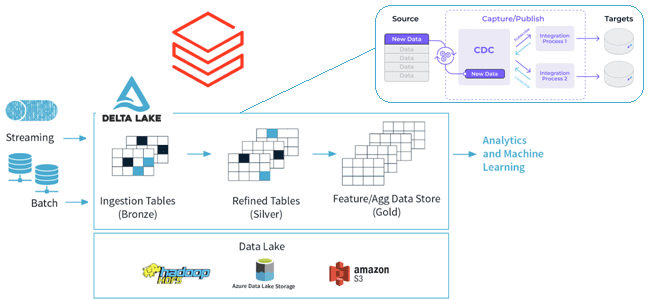
Как реализовать CDC для Delta Lake: разбираемся с функцией Change Data Feed от Databricks, которая позволяет быстро узнать обо всех изменениях строк в дельта-таблицах озера данных. Польза и принципы работы CDF для дата-инженера и архитектора данных.
CDC для Delta Lake
Идея сбора и обработки не всего объема данных, а только изменений, произошедших в системах-источниках, сегодня активно используется дата-инженерами. Это называется CDC (Change Data Capture) и применяется в управлении ETL-конвейерами для корпоративных хранилищ и озер данных. Чтобы поддерживать ACID-транзакции и масштабируемую обработку метаданных, объединяя потоковые и пакетные операции с большими данными, поверх озера данных на HDFS, S3 или Azure Data Lake Storage часто развертывается Delta Lake — коммерческая платформа Databricks, полностью совместимая со всеми API Apache Spark. Подробнее о преимуществах и принципах работы Delta Lake мы писали здесь и здесь.
Применение CDC-подхода к ETL-конвейерам Delta Lake позволяет упростить обработку измененных или добавленных данных. Но получение точных и актуальных данных для каждой таблицы в конвейерах остается довольно сложной задачей, решить которую можно с помощью функции Change Data Feed (CDF) в Delta Lake. Использование CDF упрощает реализацию конвейера, а также поддерживает операцию MERGE и управление версиями журналов Delta Lake.
Польза от включения CDF очевидна в следующих сценариях:
- создание актуальных агрегированных материализованных представлений через обновление только случившихся изменений без повторной обработки полных базовых таблиц;
- передача метаданных об изменениях в нижестоящие системы конвейера обработки ;
- журналирование потока данных об изменениях в виде дельта-таблицы для мониторинга и аудита системных событий, включая удаления и обновления данных;
- повышение производительности Delta Lake за счет ускорения и упрощения ETL/ELT-процессов благодаря обработке только изменения на уровне строк после начальных операций слияния, обновления или удаления.
Как работает эта функция, рассмотрим далее.
Принципы работы CDF-функции
CDF позволяет отслеживать изменения на уровне строк между версиями дельта-таблицы. Когда эта функция включена для дельта-таблицы, среда выполнения записывает события изменения для всех данных этой таблицы, включая данные строки и метаданные о выполненных операциях (вставка, удаление или обновление). Чтобы использовать CDF-функцию была доступна для таблицы Delta Lake, ее следует сперва включить, например, при создании таблицы:
CREATE TABLE table_name(first_col int, second_col STRING) USING delta TBLPROPERTIES (delta.enableChangeDataFeed = true)
Запросить данные об изменениях поможет функция table_changes, которая возвращает начальное и конечное представление обновленной строки, чтобы оценить различия в изменениях.
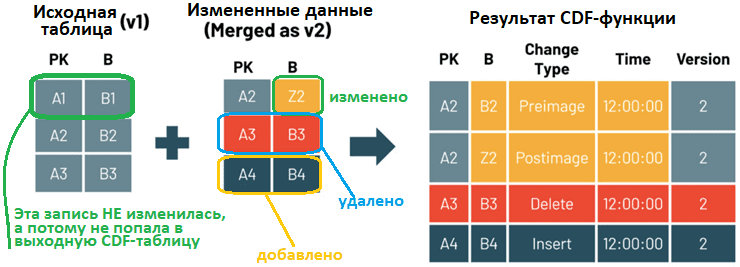
Помимо столбцов данных для CDF, данные об изменениях содержат столбцы метаданных, определяющие тип события изменения. Согласно документации Databricsk на Delta Lake, функция table_changes(table_str, start [,end]) возвращает журнал изменений в таблице Delta Lake с включенным каналом данных об изменениях. Эта функция имеет следующие параметры:
- table_str – строка (STRING) с полным именем таблицы, которое может быть уточнено указанием текущей схемы данных (current_schema). Если имя таблицы содержит пробелы или точки, надо экранировать эти символы, используя обратные кавычки внутри строки.
- start – первая версия (BIGINT) или отметка времени (TIMESTAMP) возвращаемого изменения;
- end — необязательный параметр, последняя версия (BIGINT) или отметка времени (TIMESTAMP) изменения. Если этот параметр не задан, возвращаются все изменения от запуска до текущего изменения.
Чтобы вызвать функцию table_changes(table_str, start [,end]), необходимо иметь право на использование оператора SELECT для таблицы или же быть ее владельцем или иметь административные привилегии. В результате будет возвращены все столбцы таблицы table_str, а также следующие:
- _change_type – строка (STRING НЕ NULL), которая указывает произошедшее изменение (вставка, удаление, update_preimage или update_postimage);
- _commit_version – версия фиксации таблицы (BIGINT NOT NULL), связанная с изменением;
- _commit_timestamp – отметка времени (TIMESTAMP NOT NULL), связанная с изменением.
Начальная и конечная версии дельта-таблиц, а также временные отметки начала и окончания для получения изменений включаются в запросы. Чтобы прочитать изменения из конкретной начальной версии в последнюю версию таблицы, надо указать только начальную версию или отметку времени. Например, следующий участок кода показывает, что версия фиксации изменений дельта-таблицы задана в виде целого числа, а отметка времени в виде строки в формате гггг-ММ-дд[ЧЧ:мм:сс[.SSS]].
-- version as ints or longs e.g. changes from version 0 to 10
SELECT * FROM table_changes('tableName', 0, 10)
-- timestamp as string formatted timestamps
SELECT * FROM table_changes('tableName', '2021-04-21 05:45:46', '2023-05-21 12:00:00')
-- providing only the startingVersion/timestamp
SELECT * FROM table_changes('tableName', 0)
-- database/schema names inside the string for table name, with backticks for escaping dots and special characters
SELECT * FROM table_changes('dbName.`dotted.tableName`', '2023-04-21 06:45:46' , '2021-05-21 12:00:00')
-- path based tables
SELECT * FROM table_changes_by_path('\path', '2023-04-21 05:45:46')
Таким образом, с помощью CDF-функции можно фиксировать пакетный уровень измененных данных в Delta Lakes. А подробные сведения об этих изменениях с метаданными событий для каждой измененной строки позволяют дата-инженеру точно понять, что и когда произошло.
Узнайте больше подробностей по проектированию и поддержке современных дата-архитектур в проектах аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Архитектура Данных
- Практическое применение Big Data Аналитики для решения бизнес-задач
- Потоковая обработка в Apache Spark
[elementor-template id=»13619″]
Источники

