
12 апреля 2023 года вышел очередной релиз Apache Spark. Разбираемся с самыми главными новинками этого выпуска, которые порадуют аналитиков, разработчиков, инженеров данных и специалистов по Data Science. Расширенная поддержка Python, улучшения Spark SQL и Structured Streaming. Обновления Spark SQL и новинки для пользователей Python Apache Spark 3.4.0 — это пятый...
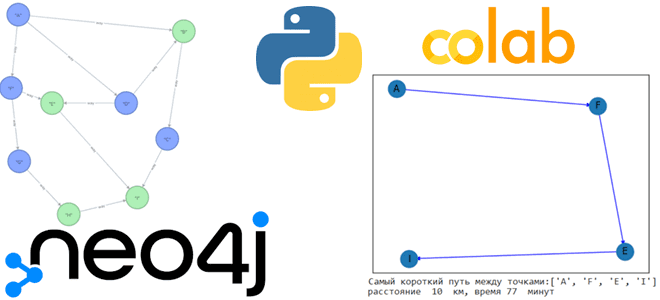
Сегодня решим логистическую задачу поиска кратчайшего пути, создав граф знаний в Neo4j, развернутой в облачной платформе Aura DB и визуализируем найденный путь с помощью Python-библиотеки Networkx. Работа с Neo4j в AuraDB В прошлой статье мы упоминали, что для работы с популярной графовой СУБД Neo4j совсем необязательно устанавливать ее локально. Можно...
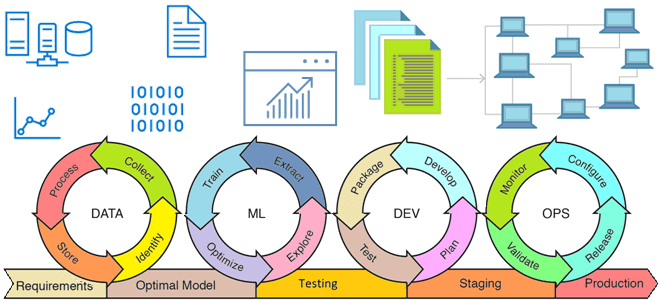
Из каких компонентов состоит архитектура MLOps, что такое инфраструктура как код, как управлять ею с помощью скриптов и почему это нужно на каждом этапе жизненного цикла моделей Machine Learning. Жизненный цикл ML-модели и MLOps MLOps – это набор методов и техник машинного обучения вместе с лучшими практиками разработки, развертывания и...
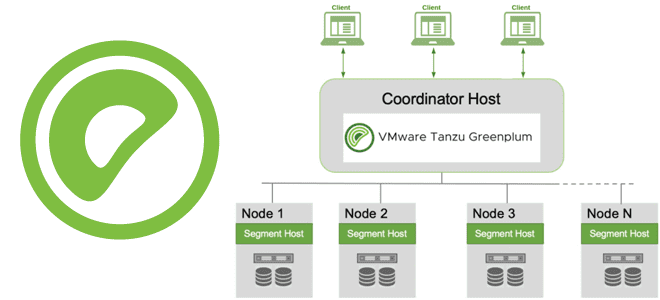
Через какие интерфейсы пользователи и клиентские приложения могут подключиться к базе данных Greenplum, как происходит подключение, какие параметры и конфигурации надо задать при этом, а также почему для этого так важна библиотека libpq. Параметры подключения к Greenplum Пользователи могут подключаться к базе данных Greenplum с помощью клиентской программы, совместимой с...

Как сделать Apache NiFi еще эффективнее, избежав трех самых популярных ошибок дата-инженера. Разбираемся с автоматизацией операций развертывания, скриптовыми процессорами, а также шаблонами и реестром NiFi для развертывания потоков данных. Ошибка №1: ручное развертывание Хотя Apache NiFi имеет мощный пользовательский интерфейс для проектирования конвейеров потоковой обработки данных, его не стоит рассматривать...
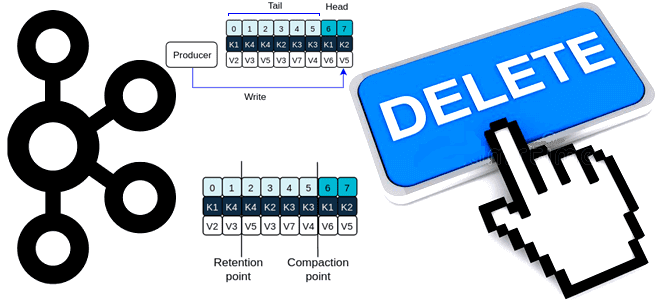
Почему в Apache Kafka нет функций очистки топика и как же все-таки удалить из него все сообщения, если очень нужно, используя конфигурации retention и другие приемы администрирования кластера. Политика очистки и конфигурации retention В отличие от брокеров сообщений, которые после отправки данных приложениям-потребителям, удаляют их из очереди, Apache Kafka хранит...
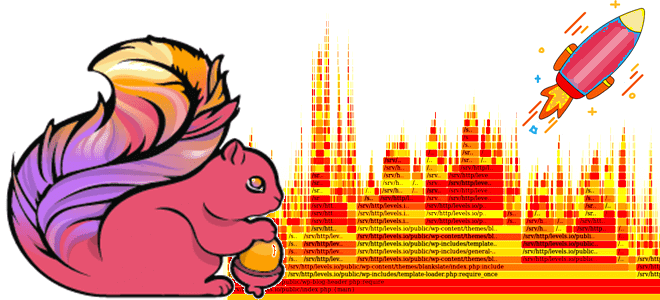
Мы уже писали о важности отслеживания системных метрик приложений Apache Flink и RocksDB, используемой этим фреймворком для хранения состояния stateful-заданий. Сегодня рассмотрим, как отследить потребление ресурсов ЦП средствами встроенной визуализации Flame Graphs. Что такое Flame Graph и зачем это нужно? Помимо мониторинга длительности выполнения задач и заданий, дата-инженерам и разработчикам...
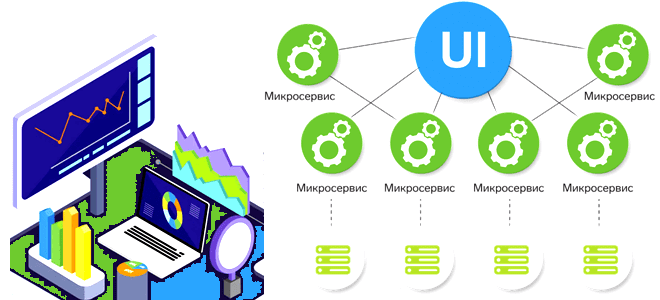
Сегодня разберем проблемы микросервисной архитектуры для платформ данных и способы их решения, а также вспомним 5 популярных шаблонов развертывания, которые могут смягчить риски от внедрения новых версий многокомпонентной системы. Проблемы микросервисной архитектуры для платформы данных и способы их решения При всех плюсах микросервисной архитектуры (автономность, гибкость, масштабируемость, простота развертывания, технологическая...

Чем тип JSONB отличается от JSON и почему это так важно для хранения и обработки данных гибкой структуры в Greenplum. Примеры SQL-запросов к JSON-данным и особенности синтаксиса JSONPath. Чем JSONB отличается от JSON и почему это так важно? Будучи основанной на PostgreSQL, Greenplum имеет множество аналогичных возможностей, включая поддержку работы...
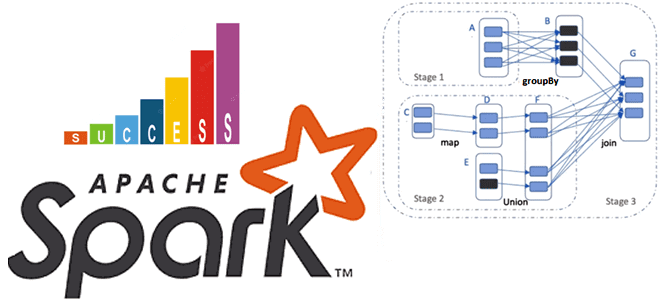
Почему на самом деле нельзя избежать shuffle-операций в Spark SQL, в чем разница перетасовки RDD и датафреймов, а также как сократить негативное влияние перемешивания данных по узлам кластера, настроив конфигурации распределенного приложения. Что такое shuffle-операции в Apache Spark SQL и зачем они нужны Распределенный характер вычислительного движка Apache Spark позволяет...
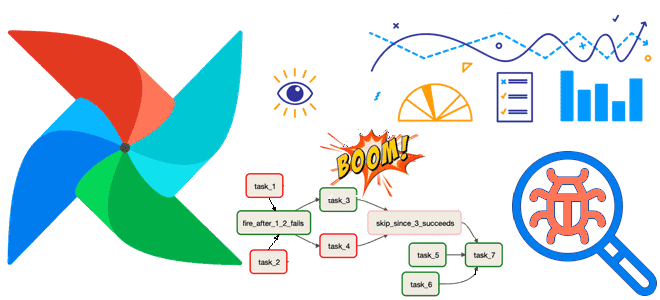
Проблемы отладки конвейеров обработки данных в Apache AirFlow и способы их решения средствами самого фреймворка. Как дата-инженеру настроить мониторинг системных событий на уровне DAG или отдельной задачи: операторы, кластерные политики и обратные вызовы. Отладка конвейеров обработки данных в Apache AirFlow: проблемы и возможности Практикующий дата-инженер знает, как бывает сложно найти...
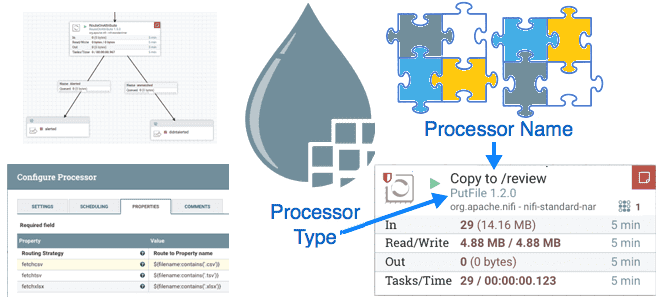
Вчера мы писали про паттерны проектирования процессоров Apache NiFi, ориентированные на данные. Сегодня рассмотрим шаблоны с фокусом на маршрутизацию потоковых файлов, которые можно применять при разработке пользовательского процессора. Маршрутизация на основе содержимого (Route Based on Content) Процессор этого типа направляет входящий FlowFile на основе его содержимого в одно или несколько...

Что пригодится дата-инженеру при разработке пользовательского процессора Apache NiFi: паттерны приема и выдачи данных, а также обогащение содержимого потокового файла. Знакомимся с принципами работы шаблонов проектирования процессоров NiFi, ориентированных на данные. Прием данных (Data Ingress) Apache NiFi предоставляет более 300 готовых процессоров – обработчиков, которые выполняют определенные действия с потоковыми...
Что не так с механизмом контрольных точек в Apache Flink, и как журнал изменений состояния справляется с ростом сквозной задержки в потоковой обработке данных средствами этого фреймворка. Проблемы контрольных точек в Apache Flink Одной из наиболее важных характеристик систем потоковой обработки данных является сквозная задержка, которая в Apache Flink зависит...
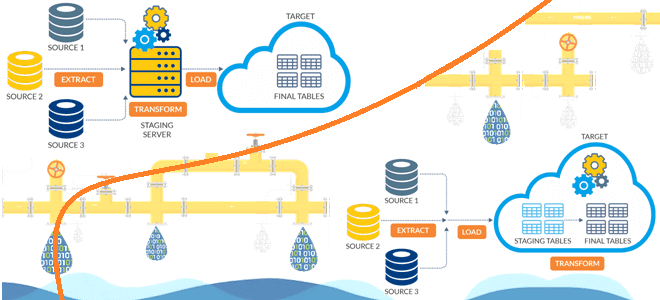
Чем динамичный ELT-подход лучше традиционного ETL, в чем разница между этими архитектурами конвейеров данных и зачем нужно профилирование данных при построении высокоэффективных дата-пайплайнов. Чем ETL отличается от ELT: ликбез для дата-инженера Аналитика больших данных невозможна без ETL/ELT-процессов, т.е. извлечения данных из разных источников (базы данных, файлы, API, прикладные системы), их...
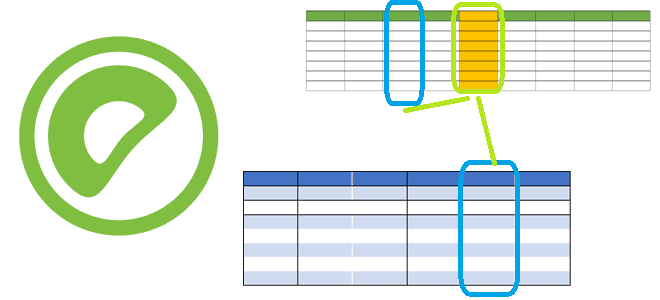
Зачем в Greenplum 7 добавлены вычисляемые (генерируемые) столбцы, как их использовать, и чем они опасны: достоинства, недостатки и ограничения этой возможности. Что такое генерируемые столбцы Поскольку Greenplum основана на PostgreSQL, эта MPP-СУБД имеет множество похожих функций. В частности, в 7-ю версию Greenplum добавлена возможность сохранения вычисляемых (генерируемых) столбцов, которые вычисляются...

Сегодня познакомимся с сервером истории Apache Spark: зачем он нужен, как работает и при чем здесь слушатели событий. Отладка и мониторинг распределенных приложений для дата-инженера в веб-GUI. Что такое сервер истории Apache Spark Каждый раз при запуске Spark-приложения его контекст SparkContext запускает веб-интерфейс по умолчанию на порту 4040. Если несколько...
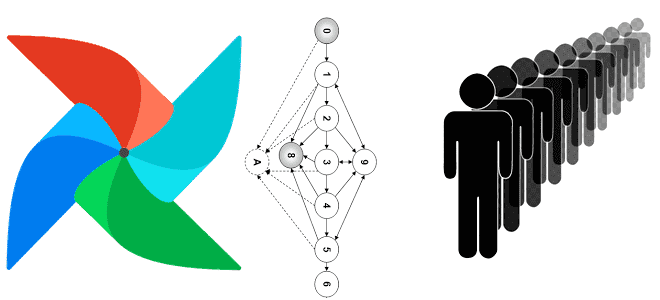
Мы уже рассказывали про задачи-зомби в Apache AirFlow и способы их устранения. Продолжая тему управления распределенными процессами, сегодня поговорим про задачи, зависшие в очереди и универсальное решение для борьбы с ними, которое будет реализовано в выпуске Apache AirFlow 2.6.0, о других новинках которого читайте здесь. Жизненный цикл задачи в Apache...
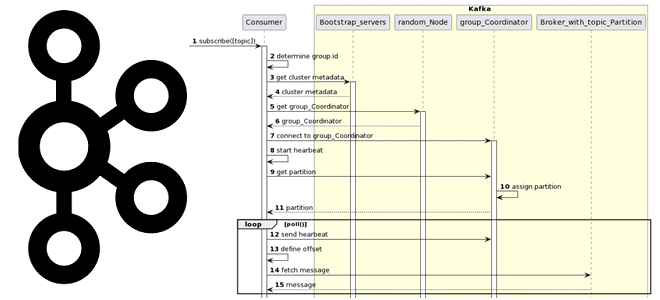
Вчера мы разбирали работу приложения-продюсера и строили UML-диаграмму последовательности. Сегодня рассмотрим, какие системные вызовы происходят при потреблении сообщений из Apache Kafka, при чем здесь группы потребителей и фиксация смещений. Как работает потребитель Kafka Аналогично разработке приложения-продюсера, при написании кода потребителя, который считывает данные из топика Apache Kafka, используются методы специальных...
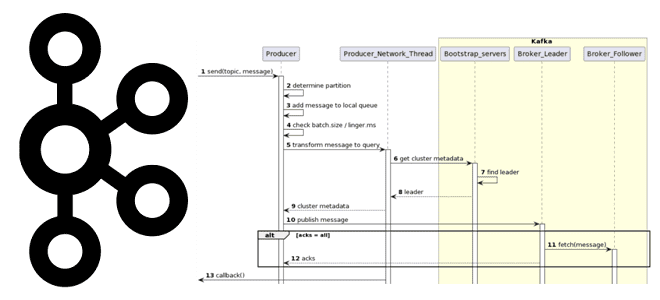
Как на самом деле работает приложение-продюсер Apache Kafka: разбираемся с конфигурациями и составляем UML-диаграмму последовательности системных вызовов при публикации сообщений в топик. Как работает продюсер Kafka Когда разработчик пишет приложение-продюсер, которое публикует сообщение в топик Apache Kafka, он использует методы специальных библиотек, таких как kafka-python и пр. Достаточно только создать...