Недавно мы писали про спецификацию OpenLineage, которая позволяет обеспечить мониторинг происхождения данных в Apache AirFlow. Сегодня рассмотрим, в чем разница Data Lineage и Data Provenance, а также, как потоковый маршрутизатор Apache NiFi организует отслеживание событий генерации и изменения данных.
Data Lineage vs Data Provenance
Сначала рассмотрим, чем отличается Data Provenance от Data Lineage. Хотя на русский оба этих выражения переводятся одинаково, они имеют разный смысл. Data Lineage показывает, откуда взялись данные и как они развивались на протяжении своего жизненного цикла. А Data Provenance больше ориентировано на историческую запись данных, фиксируя историю происхождения продукта данных, начиная с его изначальных источников.
Data Lineage прослеживается до источников, из которых они были получены, и этапов трансформации, которые они прошли. Это относится к жизненному циклу данных, включая их происхождение и то, куда они перемещаются с течением времени. Data Lineage обеспечивает наглядность аналитического конвейера и предоставляет схему для понимания того, как данные доставляются от источника к конечному пользователю. Сюда входят процессы, через которые проходят данные, такие как преобразования, агрегации и другие манипуляции. Эту информацию можно использовать для анализа первопричин, отслеживания ошибок, улучшения качества данных и обеспечения соответствия нормативным требованиям. Data Lineage отвечает на следующие вопросы о данных:
- Откуда взялись данные?
- Какие преобразования они претерпели?
- Куда они движутся дальше?
- Кто их использует и с какой целью?
Data Provenance больше ориентировано на историческую запись данных, фиксируя историю происхождения продукта данных, начиная с его первоначальных источников. Это включает в себя такие сведения, как кто создал данные, когда они были созданы, какие изменения были внесены в них и кем. Можно сказать, что Data Lineage обеспечивает высокоуровневое представление о пути данных, а Data Provenance глубже погружается в особенности их истории, подлинность и целостность данных. Data Provenance отвечает на следующие вопросы о данных:
- Кто создал данные и когда?
- Какие изменения были внесены в данные и кем?
- Каково качество и надежность данных?
- Каков первоначальный источник данных?
Таким образом, оба термина направлены на понимание истории данных, но отличаются по глубине и направленности. Data Lineage ориентировано на перемещение и преобразование данных, тогда как Data Provenance больше связано с историей и подлинностью данных. Для комплексного управления данными и стратегии управления данными необходимо поддерживать и использовать обе концепции. Будучи потоковым маршрутизатором, Apache NiFi поддерживает именно Data Provenance. Как именно, рассмотрим далее.
Как отследить создание и изменение данных в Apache NiFi
При мониторинге потока данных пользователям часто требуется способ определить, что произошло с конкретным объектом данных (FlowFile). В Apache NiFi эта информация представлена на странице происхождения данных Data Provenance. Поскольку NiFi записывает и индексирует детали происхождения данных по мере прохождения объектов через систему, пользователи могут выполнять поиск, устранять неполадки и оценивать такие вещи, как соответствие и оптимизация потока данных, в режиме реального времени. По умолчанию NiFi обновляет эту информацию каждые пять минут, но это можно настроить.
Данные о происхождении потока в NiFi позволяют воспроизводить потоковый конвейер. Пока данные о происхождении не устарели и указанный контент все еще доступен в репозитории контента, любой FlowFile можно воспроизвести из любой точки потока. Это значительно сокращает жизненный цикл разработки потокового конвейера, экономя время дата-инженера.
Все сведения по происхождению данных в Apache NiFi отображаются в GUI на вкладке с названием Data Provinance. Это диалоговое окно позволяет просмотреть самую последнюю доступную информацию о происхождении данных, выполнить поиск информации для конкретных элементов и отфильтровать результаты поиска. Также можно открыть дополнительные диалоговые окна, чтобы просмотреть подробную информацию о событии, воспроизвести данные в любой точке потока данных и просмотреть графическое представление происхождения данных или пути в потоке.
Когда авторизация включена, для доступа к информации о происхождении данных требуется глобальная политика запрос происхождения, а также политика компонента просмотр происхождения для компонента, который сгенерировал событие. Кроме того, для доступа к сведениям о событии, которые включают атрибуты и содержимое FlowFile, требуется политика компонента просмотр данных для компонента, сгенерировавшего событие.
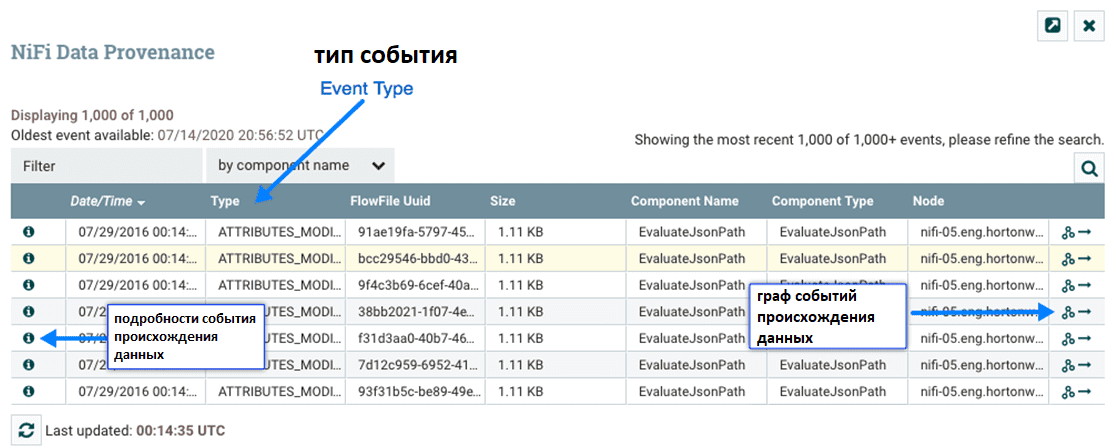
Каждая точка потока данных, где FlowFile каким-либо образом обрабатывается, считается событием происхождения. В зависимости от структуры потока данных происходят различные типы событий происхождения. Например, когда данные вводятся в поток, возникает событие RECEIVE, а когда данные отправляются из потока, возникает событие SEND. Могут возникать другие типы событий обработки, например, если данные клонируются (событие CLONE), маршрутизируются (событие ROUTE), изменяются (событие CONTENT_MODIFIED или ATTRIBUTES_MODIFIED), разделяются (событие FORK), объединяются с другими объектами данных (событие JOIN), и в конечном итоге удаляется из потока (событие DROP).
Apache NiFi поддерживает следующие типы событий:
- ADDINFO — событие происхождения, когда добавляется дополнительная информация, такая как новая связь с новым URI или UUID;
- ATTRIBUTES_MODIFIED – изменение атрибутов FlowFile;
- CLONE — указывает, что FlowFile является точной копией своего родительского FlowFile;
- CONTENT_MODIFIED – изменение содержимого FlowFile;
- CREATE – создание FlowFile на основе данных, которые не были получены от удаленной системы или внешнего процесса;
- DOWNLOAD — содержимое FlowFile загружено пользователем или внешним объектом;
- DROP — завершение жизни объекта по какой-либо причине, кроме истечения срока действия объекта;
- EXPIRE — завершение срока службы объекта из-за того, что объект не был обработан своевременно;
- FETCH — содержимое FlowFile перезаписано содержимым какого-либо внешнего ресурса;
- FORK — один или несколько FlowFile были производными от родительского FlowFile;
- JOIN — один FlowFile получен в результате объединения нескольких родительских FlowFile;
- RECEIVE — получение данных из внешнего процесса;
- REMOTE_INVOCATION – регистрация удаленного вызова к внешней конечной точке;
- REPLAY — воспроизведение FlowFile;
- ROUTE – направление FlowFile к указанному отношению с приведением причины;
- SEND — отправка данных во внешний процесс;
- UNKNOWN — тип события происхождения данных неизвестен для конкретного пользователя по причине отсутствия у него прав на просмотр этой информации.
Одна из наиболее распространенных задач, выполняемых на странице Data Provenance, — это поиск заданного FlowFile, чтобы определить, что с ним произошло. Это также можно найти в GUI фреймворка. В диалоговом окне пользователь может определить для поиска, включая интересующее событие обработки, отличительные характеристики FlowFile или компонента, вызвавшего событие, временной интервал, в течение которого выполняется поиск, и размер FlowFile.
Например, чтобы определить, был ли получен конкретный FlowFile, можно найти тип события RECEIVE и включить идентификатор FlowFile, например его uuid или имя файла. Звездочку (*) можно использовать в качестве подстановочного знака для любого количества символов.
По каждому событию происхождения данных для каждого события можно просмотреть его подробности: детали, атрибуты и содержимое.
Детали отображают различные сведения о событии, например, когда оно произошло, тип события и компонент, вызвавший это событие. Также отображается информация об обработанном FlowFile с указанием его UUID, UUID любых родительских или дочерних файлов FlowFile, связанных с текущим. Атрибуты показывают атрибуты, существующие в FlowFile на данный момент в потоке. Также можно настроить отображение только тех атрибутов, которые были изменены в результате обработки.
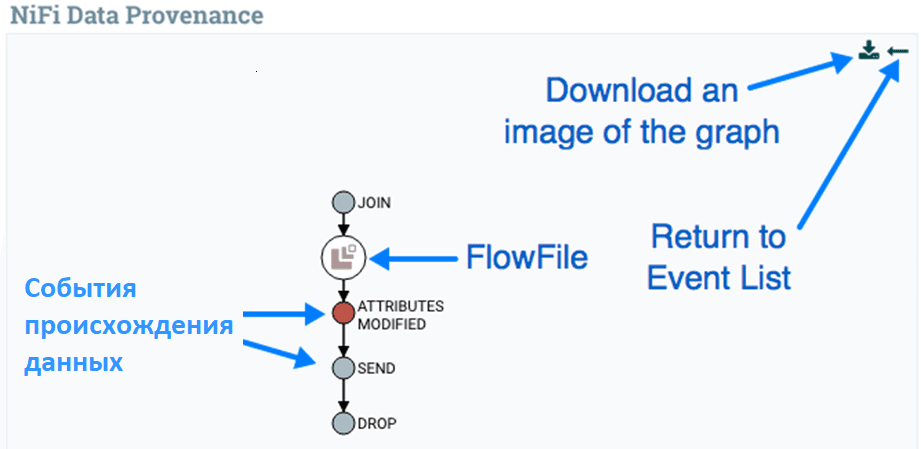
Можно увидеть графическое представление происхождения или пути, который FlowFile прошел в потоке данных на графе, который отображает его сам и различные произошедшие с ним события обработки. Также можно увидеть, как происхождение развивалось с течением времени.
Узнайте больше про администрирование и использование Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники