 745
745 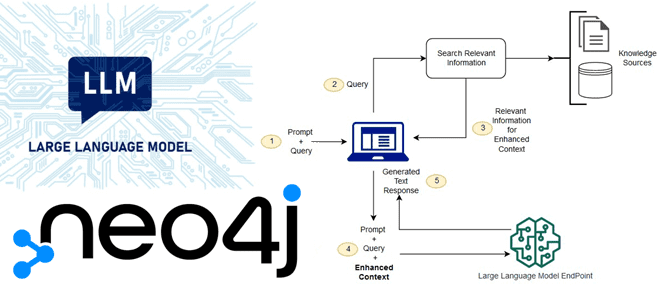
Что не так с большими языковыми моделями, как RAG-приложения расширяют возможности LLM и зачем в графовой СУБД Neo4j добавлена поддержка векторного индекса.
Зачем нужны RAG-приложения: ограничения базовых LLM-сетей
С появлением ChatGPT и других генеративных нейросетей, большие языковые модели (LLM, Large Language Models) стали активно применяться для решения множества бизнес-задач, связанных с контентом. Однако, базовые LLM, такие как Llama-2-70b, gpt-4 и пр. «знают» только ту информацию, которой они были обучены, поскольку обучаются в автономном режиме и становятся нечувствительными к данным, созданным после обучения. Кроме того, базовые модели обучаются на очень общих корпусах предметных областей, что делает их менее эффективными для задач, специфичных для предметной области.
Устранить эти ограничения базовых LLM позволяют приложения расширенной поисковой генерации (RAG, Retrieval Augmented Generation), которые позволяют извлекать данные за пределами базовой модели и добавлять их в контекст, дообучая нейросеть.
При использовании RAG внешние данные, используемые для дополнения пользовательских запросов-подсказок (prompt), могут поступать из нескольких источников данных, таких как репозитории документов, базы данных или API. Первым шагом является преобразование этих данных в совместимый формат для выполнения поиска по релевантности. Чтобы сделать форматы совместимыми, коллекция документов или библиотека знаний, а также отправленные пользователем prompt-запросы преобразуются в числовые представления с использованием встраиваемых языковых моделей. Встраивание (embedding) — это процесс, посредством которого тексту присваивается числовое представление в векторном пространстве. Архитектура модели RAG сравнивает встраивание пользовательских запросов в вектор библиотеки знаний. Затем к исходному запросу пользователя добавляется соответствующий контекст из аналогичных документов в библиотеке знаний, что потом отправляется в базовую модель. Обновлять библиотеки знаний и их соответствующие встраивания можно асинхронно.
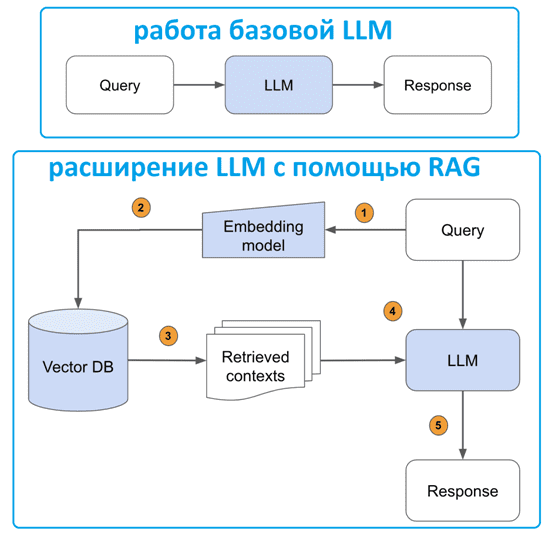
Таким образом, RAG-приложения расширяют возможности LLM через последовательность шагов:
- пользовательский запрос передается модели встраивания, чтобы семантически представить его как встраиваемый вектор;
- этот встраиваемый вектор запроса передается в векторную базу данных;
- в ответ возвращается набор релевантных контекстов, измеряемых расстоянием между встраиванием запроса и всеми встраиваемыми частями в векторной базе знаний;
- текст запроса и полученный текст контекста передается в LLM;
- LLM генерирует ответ, используя предоставленный контент.
О том, почему генеративный ИИ использует именно векторные базы данных, мы подробно рассказывали здесь. Отметим, что для небольших проектов не обязательно использовать специализированные векторные СУБД, такие как Pinecone, Milvus, Weaviate, SingleStore, Relevance AI, Qdrant, Vespa и пр., но и модули для баз данных с другой моделью Например, подобные возможности предоставляет Enterprise-редакция key-value базы Redis и расширение pgvector для реляционной PostgreSQL, которое обеспечивает поиск сходства векторов, хранит векторы вместе с остальными данными, поддерживает алгоритмы точного и приблизительного поиска ближайшего соседа, расстояние L2, внутреннее произведение и косинусное расстояние. Впрочем, подобные возможности могут быть реализованы и в графовой СУБД, что мы и рассмотрим дальше на примере Neo4j.
Векторная индексация в Neo4j
В конце августа 2023 года стало известно, что в общедоступной бета-версии Neo4j 5.11 добавлены индексы векторного поиска. Векторные индексы позволяют пользователям запрашивать векторные представления из больших наборов данных. Как уже было отмечено выше, встраивание — это числовое представление объекта данных (текст, изображение, аудио или документ). Например, каждое слово или токен в тексте обычно представляется в виде многомерного вектора, где каждое измерение представляет определенный аспект значения слова. Слова, семантически схожие или родственные, часто представляются векторами, расположенными ближе друг к другу в этом векторном пространстве. Это позволяет математическим операциям, таким как сложение и вычитание, иметь семантическое значение. Например, векторное представление «король» минус «мужчина» плюс «женщина» может быть близко к векторному представлению «королева». Таким образом, векторные представления представляют собой числовое представление конкретного объекта данных, отражающее его семантическое значение.
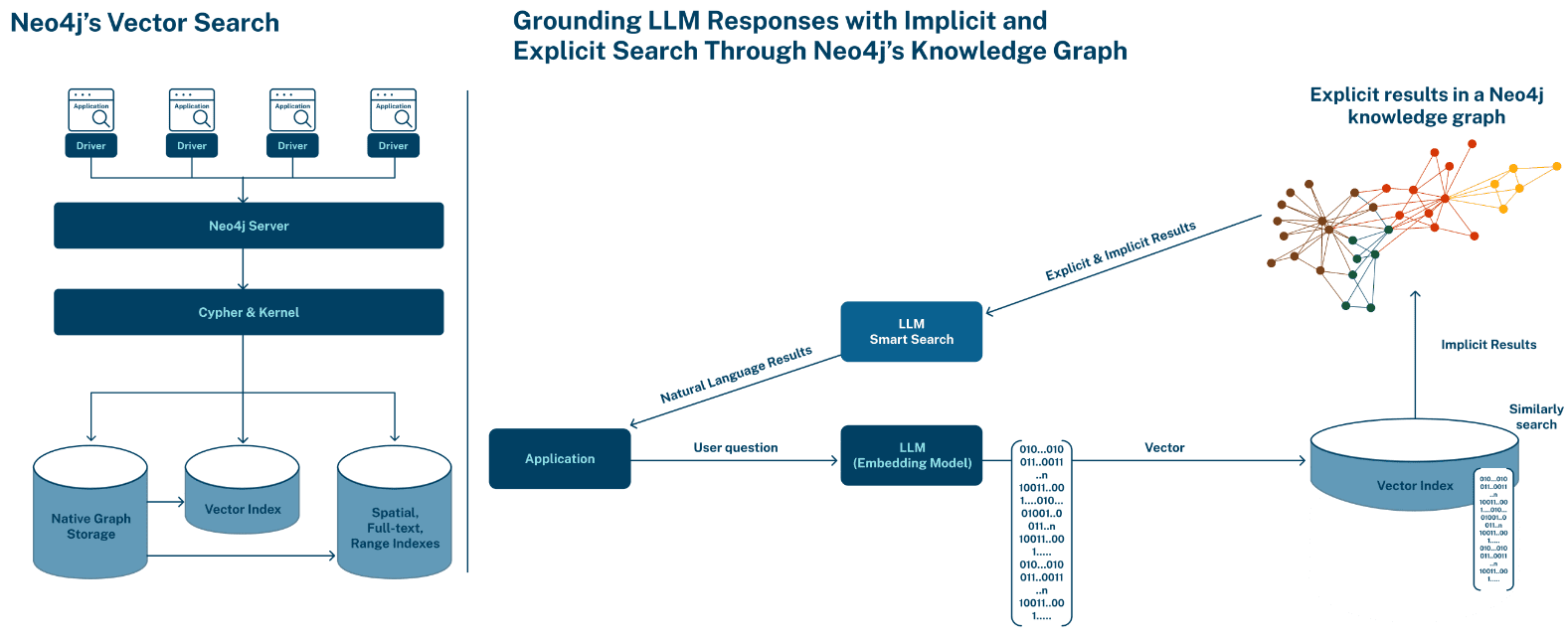
Векторные встраивания хранятся как свойства списка вещественных значений LIST<FLOAT> в узле графа, где каждый размерный компонент вектора является элементом в списке LIST. Векторный индекс Neo4j можно использовать для индексации узлов по свойствам LIST<FLOAT>, действительным для индекса. Такое векторный индекс позволяет писать запросы, соответствующие окрестностям узлов, на основе сходства свойств этих узлов и свойств, указанных в запросе. Векторные индексы Neo4j основаны на библиотеке индексирования и поиска Apache Lucene, которая реализует иерархические навигационные графы малого мира (HNSW) для выполнения запроса k приблизительных ближайших соседей (k-ANN) над векторными полями.
В Neo4j векторный индекс — это индекс с одной меткой и одним свойством для узлов. В дополнение к метке и ключу свойства, которые оба обозначаются как STRING, векторный индекс должен быть настроен как с размерностью вектора (целое число INTEGER от 1 до 2048 включительно), так и с мерой сходства между двумя векторами (строка STRING без учета регистра).
Все векторы внутри индекса должны иметь одинаковую размерность. Мера сходства определяется заданной векторной функцией сходства. Это определяет, насколько два вектора похожи друг на друга по показателю сходства, как векторы интерпретируются и какие векторы действительны для индекса. Узел индексируется, если выполняются все следующие условия:
- узел содержит настроенную метку;
- узел содержит настроенный ключ свойства;
- значение свойства имеет тип LIST<FLOAT>;
- значение размера вектора size() совпадает с настроенной размерностью;
- значение является допустимым вектором для настроенной функции сходства.
Векторный поиск, доступный всем клиентам Neo4j, обеспечивает простой подход к быстрому поиску контекстно связанной информации и помогает обнаруживать скрытые взаимосвязи. Эта мощная возможность, теперь полностью интегрированная в Neo4j AuraDB и Neo4j Graph Database , позволяет клиентам использовать векторный поиск для получения более глубокой информации из приложений генеративного ИИ за счет понимания смысла, а не сопоставления ключевых слов.
Что касается практического приложения этих возможностей, разработчики Neo4j отмечают, что в фармацевтической отрасли внедрение векторного поиска в граф знаний позволило сократить время автоматизации нормативных отчетов на 75 % за счет контекстно-зависимого связывания объектов. Для страховой компании векторный поиск и графы знаний позволили на 90% быстрее отвечать на запросы клиентов. А один международный банк повысил эффективность проверки юридических контрактов на 46%, внедрив векторный поиск по сходству для точного извлечения ключевых положений из огромных наборов документов.
Таким образом, благодаря внедрению алгоритмов машинного обучения в графы, можно взять лучшее из этих технологий для практического решения современных бизнес-задач.
Узнайте больше про использование графовых алгоритмов и приложений машинного обучения для практического применения в реальных проектах аналитики больших данных на специализированных курсах нашего лицензированного учебного центра обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

