Из-за чего приложения Flink работают быстрее Spark: разница в моделях обработки данных, управлении памятью, методах оптимизации, дизайне API и личный опыт использования.
Apache Flink vs Spark: сходства и отличия
Apache Spark и Flink считаются наиболее популярными фреймворками разработки распределенных приложений в области Big Data. Они достаточно похожи, что мы ранее рассматривали здесь: оба имеют высокоуровневый API для пакетной и потоковой обработки, позволяя разработчикам писать сложные вычислительные конвейеры обработки. Также эти фреймворки похожи по набору встроенных модулей и библиотек, например, поддержка ANSI SQL и машинного обучения. Однако, в части производительности, Spark в большинстве случаев проигрывает Flink. Это происходит из-за отличий технологий по следующим ключевым критериям:
- модели обработки данных и структуры их представления;
- управление памятью;
- методы оптимизации;
- дизайн API;
- пользовательский опыт.
Сравним обе технологии по этим критериям более подробно.
Различия в моделях обработки данных
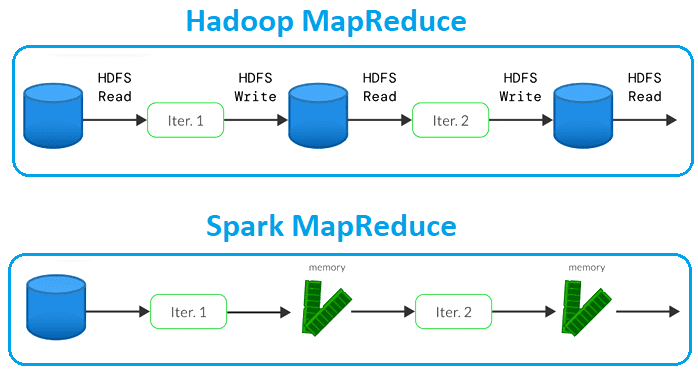
Одна из основных причин, почему производительность Spark ниже, чем у Flink, связана с их разными моделями обработки данных. Хотя оба фреймворка используют модель распределенной обработки данных, они по-разному обрабатывают распределение данных и параллелизм. Spark считается платформой обработки данных третьего поколения и изначально поддерживает пакетную и потоковую обработку. Spark использует микропакетную обработку, которая делит неограниченный поток событий на небольшие фрагменты (пакеты) и запускает вычисления. Spark повысил производительность классической модели MapReduce из Apache Hadoop, выполняя обработку в памяти вместо того, чтобы записывать каждый шаг обратно на диск.
Spark использует отказоустойчивую распределенную коллекцию данных (RDD) в качестве фундаментальной структуры. RDD представляет собой неизменяемую версию данных, доступную только для чтения, хранящуюся в распределенном кластере. Будучи отказоустойчивой структурой данных, RDD может восстанавливаться после сбоев без потери информации. Однако, такая конструкция не оптимизирована для параллелизма и не гарантирует отсутствия конфликтов рассогласования, когда несколько операций выполняются над одним и тем же RDD одновременно.
Разумеется, кроме RDD в Spark есть и другие структуры данных, которые предоставляют гибкий высокоуровневый API: Dataframe и Dataset, о чем мы писали здесь. Однако, они все равно реализуют модель микропакетных, а не потоковых вычислений, в отличие от истинно потоковой природы Flink, который уже несколько лет назад объединил API пакетной и потоковый обработки. Подробнее об универсальном API Apache Flink читайте в этом материале.
Apache.Flink является распределенным фреймворком обработки данных четвертого поколения, изначально поддерживая пакетную и потоковую обработку. Он обеспечивает непрерывную потоковую передачу, при которой вычисления событий запускаются сразу после их получения. Flink использует более гибкую распределенную модель, основанную на потоковой обработке с отслеживанием состояния. При потоковой обработке с отслеживанием состояния данные обрабатываются в непрерывном потоке и могут храниться в памяти для более быстрого доступа. Такая конструкция позволяет Flink оптимизировать параллелизм и обрабатывать большие наборы данных более эффективно, чем Spark.
Flink предлагает встроенную потоковую передачу, а Spark использует микропакеты для эмуляции потоковой передачи. Это означает, что Flink обрабатывает каждое событие в режиме реального времени и обеспечивает очень низкую задержку. Spark, используя микропакетную обработку, может обеспечить обработку только в режиме, близком к реальному времени. Для многих случаев использования Spark обеспечивает приемлемый уровень производительности. Однако, благодаря низкой задержке Flink превосходит производительность Spark даже при более высокой пропускной способности. Spark может обеспечить низкую задержку при более низкой пропускной способности, но увеличение пропускной способности также приведет к увеличению задержки. Такой компромисс означает, что пользователям Spark необходимо настроить конфигурацию для достижения приемлемой производительности, что повышает сложность разработки.
Управление памятью
Еще одна причина, по которой производительность Spark ниже, чем у Flink, связана с управлением памятью. Как упоминалось ранее, RDD являются неизменяемыми и должны храниться в памяти во время работы, что увеличивает интенсивное потребление этого ресурса и может привести к конфликтам. Кроме того, модель отложенных вычислений Spark также может стать причиной перетасовке данных с их передачей по сети, что также снижает производительность. Напротив, Flink использует более эффективную модель управления памятью, основанную на колоночном хранении и партиционировании данных. Колоночное хранилище организует данные в столбцы фиксированного размера, которые можно обрабатывать параллельно без необходимости перемешивания, т.е. shuffle-операций. Такой подход снижает потребление памяти и повышает производительность, позволяя обрабатывать данные непосредственно с диска, а не загружать их в память сразу.
Методы оптимизации
Оба фреймворка предлагают широкий набор методов оптимизации для повышения производительности, но они существенно различаются. Spark в большей степени полагается на преобразования и действия для оптимизации производительности, тогда как Flink использует более декларативную модель программирования, которая работает быстрее. В Spark разработчики могут использовать преобразования и действия для оптимизации производительности, применяя определенные оптимизации к своему коду. Например, использование соединений на этапе сопоставления (Map) или фильтрации перед группировкой может повысить производительность за счет уменьшения объема данных, которые необходимо передать по сети. Однако, эти оптимизации довольно сложны в реализации.
Декларативная модель программирования Apache Flink позволяет разработчикам выражать логику обработки данных проще и поддерживает оптимизацию производительности за счет автоматического применения лучших практик, таких как отложенные вычисления, партиционирование и кэширование. Кроме того, Flink предоставляет встроенную поддержку широковещательных переменных и аккумуляторов, что также повышает производительность.
Задания Spark должны быть оптимизированы разработчиками вручную с помощью расширяемого оптимизатора Catalyst, основанном на конструкции функционального программирования Scala. Spark упрощает создание новых оптимизаций и позволяет разработчикам расширять оптимизатор Catalyst. Spark также включает в себя механизм выполнения Tungsten, который оптимизирует физическое выполнение операций для повышения производительности.
Flink имеет оптимизатор пакетной обработки на основе затрат, который анализирует поток данных и оптимизирует задания перед выполнением на движке потоковой передачи, выбирая наиболее эффективный план выполнения на основе доступных ресурсов и характеристик данных. Оптимизатор Flink не зависит от интерфейса программирования и работает аналогично оптимизаторам реляционных баз данных, прозрачно применяя оптимизацию к потокам данных. Потоковая обработка Flink выигрывает от выполнения на основе конвейера и планирования с малой задержкой.
Дизайн API
Хотя оба фреймворка предлагают мощные высокоуровневые API, разобраться в них не так-то просто. Apache Flink имеет многоуровневые API, которые предлагают разные уровни выразительности и контроля и предназначены для разных типов использования. Тремя уровнями API являются функции процесса (также известные как API обработки потоков с отслеживанием состояния), поток данных, а также таблицы и SQL. API потоковой обработки с отслеживанием состояния требует написания подробного кода, но обеспечивает максимальный контроль над временем и состоянием, которые являются основными концепциями потоковой обработки с отслеживанием состояния. API DataStream поддерживает Java, Scala и Python и предлагает примитивы для многих распространенных операций потоковой обработки, а также баланс между подробностью кода или выразительностью и контролем. API таблиц и SQL — это реляционные API, которые обеспечивают поддержку Java, Scala, Python и SQL. Они предлагают высочайшую абстракцию и интуитивно понятный, подобный SQL, декларативный контроль над потоками данных. Flink также обеспечивает плавный переход и переключение между этими API.
Структурированная потоковая передача Apache Spark предлагает API-интерфейсы Dataset и DataFrame, которые предоставляют высокоуровневые API-интерфейсы декларативной потоковой передачи для представления статических, ограниченных данных, а также потоковых, неограниченных данных. Операции поддерживаются в Scala, Java, Python и R. Spark имеет богатый набор функций и синтаксис с простыми конструкциями для выбора, агрегирования, управления окнами, соединениями и пр. Можно использовать API потоковых таблиц для чтения таблиц как потоковых кадров данных в качестве расширения API DataFrame.
В целом можно сказать, что API-интерфейсы Spark Structured Streaming эквивалентны API-интерфейсам Flink Table и SQL.
| Возможности API | Flink | Spark |
| Построчная обработка | Да | Да |
| Пользовательские функции | Да | Да |
| Детальный доступ к состоянию | Да, через DataStream и низкоуровневые API | Нет |
| Контроль при государственном выселении | Да, через DataStream и низкоуровневые API | Нет |
| Гибкие структуры данных для хранения состояния и выполнения запросов | Да, через DataStream и низкоуровневые API | Нет |
| Таймеры для обработки и операций с отслеживанием состояния | Да, через API низкого уровня | Нет |
Spark предоставляет функции управления окнами для обработки потоковых данных в фиксированных или скользящих временных окнах. Однако, оконное управление Spark менее гибкое и эффективное по сравнению с Flink из-за микропакетной обработки. Flink имеет расширенную поддержку окон, включая окна на основе времени события и времени обработки, окна сеанса и гибкие настраиваемые оконные функции. Управление окнами Flink более эффективно и точно для потоковой обработки, поскольку оно разработано специально для непрерывных потоков данных.
Пользовательский опыт и поддержка сообщества
С точки зрения пользовательского опыта, мне лично Apache Flink показался более сложным по сравнению со Spark. В частности, из-за того, что Flink основан на потоковой модели обработки данных, чтобы использовать возможности этого фреймворка разработчик должен хорошо понимать особенности этой вычислительной парадигмы и управлять состоянием данных в реальном времени. А это на порядок сложнее пакетной и микропакетной обработки в Apache Spark.
Дополнительную сложность вносит большая зрелость и распространенность Spark по сравнению с Flink. В свою очередь, Flink отличный выбор для сложных случаев обработки событий или встроенной потоковой передачи, поскольку обеспечивает лучшую производительность, задержку и масштабируемость. Кроме того, он имеет лучшую поддержку оконных функций и управления состоянием. Наконец, он позволяет делать сложные вычисления с помощью примитивных операций, что потребует разработки специальной логики в Spark. Однако, порог входа в Apache Flink выше.
Таким образом, хотя разница в моделях обработки данных, управлении памятью, методах оптимизации и дизайне API обусловливают более высокую производительность Apache Flink По сравнению со Spark, решение о выборе технологии следует принимать с учетом компетенций команды реализации. Если разработчики лучше владеют Spark, и в ТЗ нет жестких требований к обработке данных строго в реальном времени, этот фреймворк отлично позволит реализовать распределенное отказоустойчивое приложение. Однако, если задержка должна измеряться в микросекундах, имеет смысл рассмотреть Flink с его широким набором инструментов.
Освойте возможности Apache Flink и Spark для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- https://medium.com/@acmilanellosw/why-spark-performance-is-less-than-flink-a6a02a8b62
- https://aws.amazon.com/ru/blog/big-data/a-side-by-side-comparison-of-apache-spark-and-apache-flink-for-common-streaming-use-cases
- https://www.macrometa.com/event-stream-processing/spark-vs-flink
- https://www.dataversity.net/spark-vs-flink-key-differences-and-how-to-choose/