 1040
1040 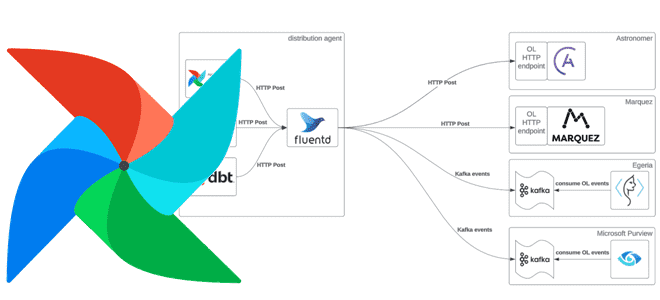
Как Apache AirFlow отслеживает происхождение данных, какова структура спецификации OpenLineage, чем она схожа с OpenAPI, какие инструменты позволяют сформировать эту документацию и чем она полезна.
Что такое OpenLineage
В области инженерии данных и управления конвейерами их обработки очень важно понятие происхождения данных (Data Lineage). Это концепция отслеживания и визуализации данных от их источника до места, куда они передаются и где потребляются. Происхождение данных полезно дата-инженеру во многих аспектах, от понимания источников данных до устранения сбоев в работе, управления личными данными и обеспечения соблюдения требований к данным. Поскольку Apache AirFlow активно используется в качестве универсального оркестратора для проектирования конвейеров обработки данных, вполне логично, что мониторинг их происхождения весьма актуален для ETL-заданий.
Напомним, с версии 2.7 фреймворк поддерживает спецификацию OpenLineage – открытую платформу для сбора и анализа метаданных о происхождении данных, включая метаданные о наборах данных, заданиях и запусках. В основе OpenLineage лежит стандартный API для захвата событий происхождения данных. Компоненты конвейера, такие как планировщики, хранилища, инструменты анализа и механизмы SQL, могут использовать этот API для отправки данных о запусках, заданиях и наборах данных в совместимый OpenLineage с бэкэнд для дальнейшего исследования.
OpenLineage содержит открытый стандарт для сбора данных о происхождении, эталонную реализацию хранилища метаданных (Marquez), библиотеки для распространенных языков и интеграцию с инструментами конвейера данных.
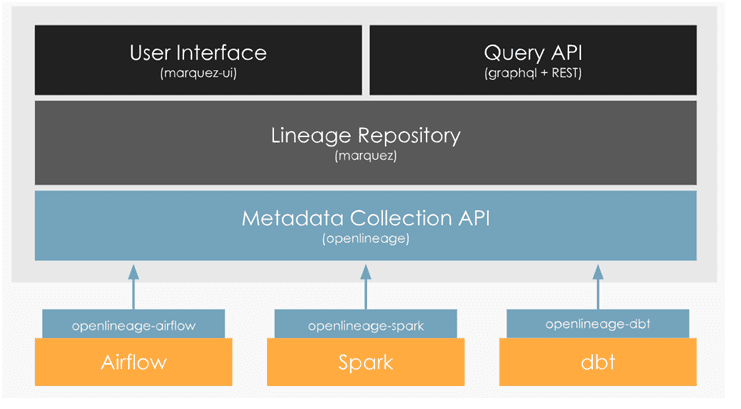
Фактически спецификация OpenLineage представляет собой YAML или JSON-файл, основанный на стандарте описания REST API под названием OpenAPI, который описывает не только HTTP-методы запросов, коды ответов и структуры данных, но и специфичные для конвейера понятия:
- Событие выполнения(RunEvent), описывающее наблюдаемое состояние выполнения задания. Требуется отправка как минимум событий START и событий COMPLETE/FAIL/ABORT. Дополнительные события не являются обязательными.
- Задание(Job) – определение процесса, который потребляет и создает наборы данных, определяемые как входные и выходные данные. Оно идентифицируется уникальным именем в пространстве имен, которое назначается планировщику, запускающему задания. Задание изменяется с течением времени, и эти изменения фиксируются при его запуске.
- Набор данных(Dataset) – абстрактное представление данных с уникальным именем в пространстве имен источника данных, полученным из его физического местоположения, например, host.database.schema.table. Обычно набор данных изменяется после завершения задания записи данных в него. Подобно различию между заданием и выполнением, метаданные, которые становятся более статичными от запуска к запуску, фиксируются в DatasetFacet, например, схема, которая не меняется при каждом запуске. Но то, что меняется при каждом запуске, фиксируется как InputFacet или OutputFacet, показывая, какое подмножество набора данных было прочитано или записано, например, временной раздел.
- Выполнение (Run) – экземпляр выполняемого задания с указанием времени начала и завершения или сбоя. Запуск идентифицируется глобально уникальным идентификатором (UUID) относительно его определения задания.
- Фасет(Facet) – часть метаданных, прикрепленная к одному из объектов, определенных выше. Этот атомарный фрагмент метаданных, идентифицируемый по его имени, определяется как объект JSON, который может быть либо частью спецификации, либо пользовательскими фасетами, определенными в другом проекте. Создание нового фасета с тем же именем для той же сущности полностью заменяет предыдущий экземпляр фасета для этой сущности. Пользовательские фасеты должны использовать отдельный префикс, названный в честь определяющего их проекта, чтобы избежать конфликта со стандартными фасетами, определенными в спецификации OpenLineage.
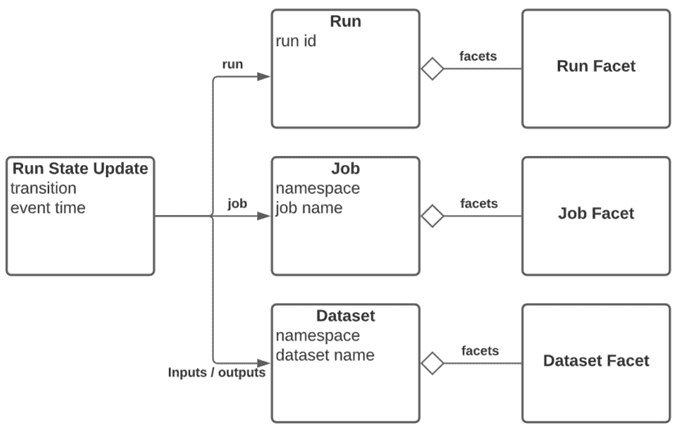
JSON-схема спецификации OpenLineage выглядит так:
{
"$schema": "https://json-schema.org/draft/2020-12/schema",
"$id": "https://openlineage.io/spec/2-0-2/OpenLineage.json",
"$defs": {
"BaseEvent": {
"type": "object",
"properties": {
"eventTime": {
"description": "the time the event occurred at",
"type": "string",
"format": "date-time"
},
"producer": {
"description": "URI identifying the producer of this metadata. For example this could be a git url with a given tag or sha",
"type": "string",
"format": "uri",
"example": "https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client"
},
"schemaURL": {
"description": "The JSON Pointer (https://tools.ietf.org/html/rfc6901) URL to the corresponding version of the schema definition for this RunEvent",
"type": "string",
"format": "uri",
"example": "https://openlineage.io/spec/0-0-1/OpenLineage.json"
}
},
"required": ["eventTime", "producer", "schemaURL"]
},
"RunEvent": {
"allOf": [
{ "$ref": "#/$defs/BaseEvent" },
{
"type": "object",
"properties": {
"eventType": {
"description": "the current transition of the run state. It is required to issue 1 START event and 1 of [ COMPLETE, ABORT, FAIL ] event per run. Additional events with OTHER eventType can be added to the same run. For example to send additional metadata after the run is complete",
"type": "string",
"enum": ["START", "RUNNING", "COMPLETE", "ABORT", "FAIL", "OTHER"],
"example": "START|RUNNING|COMPLETE|ABORT|FAIL|OTHER"
},
"run": {
"$ref": "#/$defs/Run"
},
"job": {
"$ref": "#/$defs/Job"
},
"inputs": {
"description": "The set of **input** datasets.",
"type": "array",
"items": {
"$ref": "#/$defs/InputDataset"
}
},
"outputs": {
"description": "The set of **output** datasets.",
"type": "array",
"items": {
"$ref": "#/$defs/OutputDataset"
}
}
},
"required": ["run", "job"]
}
]
},
"DatasetEvent": {
"allOf": [
{ "$ref": "#/$defs/BaseEvent" },
{
"type": "object",
"properties": {
"dataset": {
"$ref": "#/$defs/StaticDataset"
}
},
"required": ["dataset"],
"not": { "required": ["job", "run"] }
}
]
},
"JobEvent": {
"allOf": [
{ "$ref": "#/$defs/BaseEvent" },
{
"type": "object",
"properties": {
"job": {
"$ref": "#/$defs/Job"
},
"inputs": {
"description": "The set of **input** datasets.",
"type": "array",
"items": {
"$ref": "#/$defs/InputDataset"
}
},
"outputs": {
"description": "The set of **output** datasets.",
"type": "array",
"items": {
"$ref": "#/$defs/OutputDataset"
}
}
},
"required": ["job"],
"not": { "required": ["run"] }
}
]
},
"Run": {
"type": "object",
"properties": {
"runId": {
"description": "The globally unique ID of the run associated with the job.",
"type": "string",
"format": "uuid"
},
"facets": {
"description": "The run facets.",
"type": "object",
"anyOf": [
{
"type": "object",
"additionalProperties": { "$ref": "#/$defs/RunFacet" }
}
]
}
},
"required": ["runId"]
},
"RunFacet": {
"description": "A Run Facet",
"type": "object",
"allOf": [{ "$ref": "#/$defs/BaseFacet" }]
},
"Job": {
"type": "object",
"properties": {
"namespace": {
"description": "The namespace containing that job",
"type": "string",
"example": "my-scheduler-namespace"
},
"name": {
"description": "The unique name for that job within that namespace",
"type": "string",
"example": "myjob.mytask"
},
"facets": {
"description": "The job facets.",
"type": "object",
"anyOf": [
{
"type": "object",
"additionalProperties": { "$ref": "#/$defs/JobFacet" }
}
]
}
},
"required": ["namespace", "name"]
},
"JobFacet": {
"description": "A Job Facet",
"type": "object",
"allOf": [
{ "$ref": "#/$defs/BaseFacet" },
{
"type": "object",
"properties": {
"_deleted": {
"description": "set to true to delete a facet",
"type": "boolean"
}
}
}
]
},
"InputDataset": {
"description": "An input dataset",
"type": "object",
"allOf": [
{ "$ref": "#/$defs/Dataset" },
{
"type": "object",
"properties": {
"inputFacets": {
"description": "The input facets for this dataset.",
"type": "object",
"anyOf": [
{
"type": "object",
"additionalProperties": {
"$ref": "#/$defs/InputDatasetFacet"
}
}
]
}
}
}
]
},
"InputDatasetFacet": {
"description": "An Input Dataset Facet",
"type": "object",
"allOf": [{ "$ref": "#/$defs/BaseFacet" }]
},
"OutputDataset": {
"description": "An output dataset",
"type": "object",
"allOf": [
{ "$ref": "#/$defs/Dataset" },
{
"type": "object",
"properties": {
"outputFacets": {
"description": "The output facets for this dataset",
"type": "object",
"anyOf": [
{
"type": "object",
"additionalProperties": {
"$ref": "#/$defs/OutputDatasetFacet"
}
}
]
}
}
}
]
},
"OutputDatasetFacet": {
"description": "An Output Dataset Facet",
"type": "object",
"allOf": [{ "$ref": "#/$defs/BaseFacet" }]
},
"Dataset": {
"type": "object",
"properties": {
"namespace": {
"description": "The namespace containing that dataset",
"type": "string",
"example": "my-datasource-namespace"
},
"name": {
"description": "The unique name for that dataset within that namespace",
"type": "string",
"example": "instance.schema.table"
},
"facets": {
"description": "The facets for this dataset",
"type": "object",
"anyOf": [
{
"type": "object",
"additionalProperties": { "$ref": "#/$defs/DatasetFacet" }
}
]
}
},
"required": ["namespace", "name"]
},
"StaticDataset": {
"description": "A Dataset sent within static metadata events",
"type": "object",
"allOf": [{ "$ref": "#/$defs/Dataset" }]
},
"DatasetFacet": {
"description": "A Dataset Facet",
"type": "object",
"allOf": [
{ "$ref": "#/$defs/BaseFacet" },
{
"type": "object",
"properties": {
"_deleted": {
"description": "set to true to delete a facet",
"type": "boolean"
}
}
}
]
},
"BaseFacet": {
"description": "all fields of the base facet are prefixed with _ to avoid name conflicts in facets",
"type": "object",
"properties": {
"_producer": {
"description": "URI identifying the producer of this metadata. For example this could be a git url with a given tag or sha",
"type": "string",
"format": "uri",
"example": "https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client"
},
"_schemaURL": {
"description": "The JSON Pointer (https://tools.ietf.org/html/rfc6901) URL to the corresponding version of the schema definition for this facet",
"type": "string",
"format": "uri",
"example": "https://openlineage.io/spec/1-0-2/OpenLineage.json#/$defs/BaseFacet"
}
},
"additionalProperties": true,
"required": ["_producer", "_schemaURL"]
}
},
"oneOf": [{ "$ref": "#/$defs/RunEvent" }, { "$ref": "#/$defs/DatasetEvent" }, { "$ref": "#/$defs/JobEvent" }]
}
Визуальное отображение спецификации выглядит подобно OpenAPI в Swagger UI:

API OpenLineage определяет события для отслеживания жизненного цикла выполнения задания. Когда задание выполняется, собираются его метаданные, отправляя события запуска, когда состояние задания переходит в другое состояние. Так можно наблюдать различные аспекты выполнения задания на разных этапах, поскольку в каждом событии в течение жизненного цикла его запуска могут собираться разные метаданные. Все метаданные являются аддитивными. Например, если во время выполнения задания обнаружено больше входных или выходных данных, можно отправить дополнительные события специально для этих наборов данных без повторной отправки ранее наблюдаемых входных или выходных данных.
До версии 2.7 выпуск метаданных OpenLineage в Apache AirFlow был возможен только с помощью реализации плагина, поддерживаемого в проекте OpenLineage, который зависел от AirFlow и внутренних компонентов оператора. C августа 2023 года встроенная поддержка OpenLineage в AirFlow делает публикацию метаданных через экосистему OpenLineage более простой и надежной. Это реализовано путем перемещения пакета openlineage-AirFlow из проекта OpenLineage к провайдеру AirFlow-openlineage в базовом образе AirFlow Docker, где его можно включить с помощью конфигурации, включая логику извлечения происхождения вместе с модульными тестами, что в большинстве случаев устраняет необходимость в дополнительных экстракторах. Наличие логики извлечения в каждом провайдере обеспечивает стабильность контракта происхождения в каждом операторе и упрощает добавление покрытия происхождения к пользовательским операторам.
Таким образом, метаданные происхождения описывают пользовательские наборы данных, например, таблицу в Snowflake и задания, такие как задачи в Dag AirFlow. Бэкенд OpenLineage хранит и обрабатывает метаданные происхождения, а интерфейс позволяет просматривать эти метаданные и взаимодействовать с ними, включая график, который визуализирует задания и наборы данных, показывая связи между ними. В частности, граф происхождения данных может иметь следующий вид.

Использование с Apache AirFlow
Разобравшись, что такое OpenLineage, рассмотрим использование этой спецификации с Apache AirFlow. Чтобы загрузить и установить последнюю версию библиотеки openlineage-airflow, следует у работающего экземпляра AiFflow обновить файл requirements.txt. До Apache AirFlow библиотеку приходилось устанавливать через менеджер пакетов pip:
pip install openlineage-airflow
Начиная с AirFlow 2.3 интеграция с OpenLineage автоматически регистрируется, если она установлена на рабочий Python-процесс AirFlow. Также необходимо настроить следующие компоненты:
- интеграция – средство сбора метаданных о происхождении из исходной системы, такой как планировщик или платформа данных. В частности, интеграция OpenLineage-AirFlow позволяет собирать метаданные о происхождении из DAG AirF Существующие интеграции автоматически собирают метаданные о происхождении из исходной системы каждый раз при запуске задания, подготавливая и передавая события OpenLineage на серверную часть. Помимо AirFlow, OpenLineage поддерживает множество интеграций с другим фреймворками.
- Экстрактор — модуль, который собирает метаданные происхождения от определенного веб-перехватчика (хука) или оператора. Например, в пакете openlineage-airflow существуют экстракторы для операторов PostgresOperator и SnowflakeOperator, обеспечивая автоматическую генерацию метаданных о происхождении данных из этих операторов при запуске DAG. Экстрактор должен существовать, чтобы конкретный оператор мог получить из него метаданные о происхождении.
- Задание — процесс, который потребляет или создает наборы данных. В контексте интеграции AirFlow задание OpenLineage соответствует задаче в DAG. Только задачи, поступающие от операторов с экстракторами, будут иметь входные и выходные метаданные, а другие задачи в DAG будут отображаться как потерянные на графике происхождения.
- Набор данных — представление набора данных в метаданных и графе вашего происхождения. Например, это может соответствовать таблице в базе данных.
- Выполнение – экземпляр задания, в котором генерируются метаданные происхождения. В контексте интеграции AirFlow запуск OpenLineage будет генерироваться при каждом запуске DAG.
- Фасет — часть метаданных о происхождении задания, набора данных или запуска, например, фасет задания.
Пока только интеграция AirFlow 2.3.0+ с OpenLineage 0.8.1+ позволяет получать метаданные о происхождении для неудачных запусков задач. Лишь некоторые операторы имеют встроенные экстракторы. Чтобы получить метаданные о происхождении от других операторов, дата-инженеру придется создать свой собственный экстрактор или использовать экстрактор по умолчанию в AirFlow 2.3+, чтобы изменить операторы AirFlow для сбора метаданных о происхождении. Чтобы получить метаданные происхождения из внешней системы, подключенной к AirFlow, например приложение Apache Spark, необходимо также настроить еще одну интеграцию OpenLineage с этим сервисом.
Также для использования OpenLineage с AirFlow следует указать, куда отправлять события происхождения данных. Проще всего для этого использовать переменную среды OPENLINEAGE_URL. Например, чтобы отправить события OpenLineage в локальный экземпляр Marquez, надо задать
OPENLINEAGE_URL=http://localhost:5000
Чтобы настроить дополнительную конфигурацию или отправлять события на цели, отличные от HTTP-сервера, например, топик Kafka, придется настроить клиент. Для AirFlow старше 2.3.0, потребуется дополнительная настройка.
Читайте в нашей новой статье, чем Data Lineage отличается от Data Provenance.
Узнайте больше про Apache AirFlow и его практическое использование в дата-инженерии и аналитике больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники
- https://docs.astronomer.io/learn/airflow-openlineage
- https://github.com/OpenLineage/OpenLineage/blob/main/spec/OpenLineage.md
- https://openlineage.github.io/
- https://openlineage.github.io/apidocs/openapi/
- https://openlineage.io/docs/integrations/airflow/
- https://pypi.org/project/openlineage-airflow/1.2.0/

