Что такое код верхнего уровня в Apache AirFlow, почему его следует избегать и как это сделать: шаблонные переменные, динамическое сопоставление задач, Python-функции и библиотеки для кэширования. А также 3 нативных способа создания перекрестных зависимостей между DAG для их запуска: TriggerDagRunOperator, ExternalTaskSensor и SimpleHttpOperator. Что такое код верхнего уровня в Apache...

В этой статье для дата-инженеров и разработчиков распределенных приложений рассмотрим, какие механизмы обеспечения информационной безопасности поддерживает Apache Spark и как организовать безопасное взаимодействие Spark-приложения с хранилищами данных в экосистеме Hadoop. Безопасная работа Spark-приложений с сервисами Hadoop Многие технологии Big Data изначально оптимизированы для хранения и аналитики больших объемов данных с...
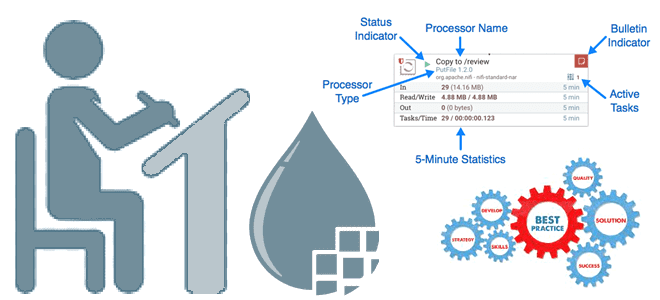
Поскольку Apache NiFi позволяет не только использовать готовые процессоры, но и разработать свой собственный, дата-инженеру полезно знать лучшие практики проектирования таких обработчиков Flow File. Принцип единой ответственности при проектировании процессора Apache NiFi В Apache NiFi есть более 300 готовых процессоров, которые выполняют определенные действия с потоковыми файлами в рамках конвейера...
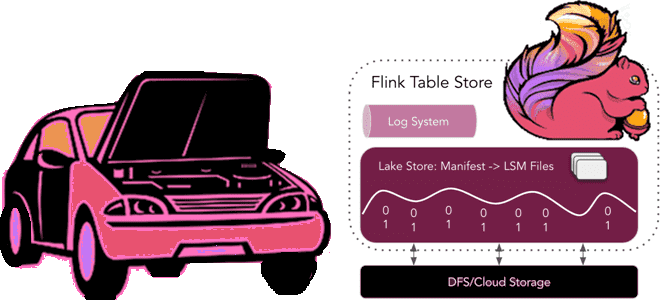
Год назад мы уже писали, как в Apache Flink появились табличные хранилища и зачем они нужны. Сегодня заглянем под капот Flink Table Store, познакомившись со структурой файлов и каталогов. Архитектура и принципы работы Flink Table Store Поскольку Apache Flink объединяет пакетную обработку данных с потоковой, для работы этого универсального stateful-механизма...
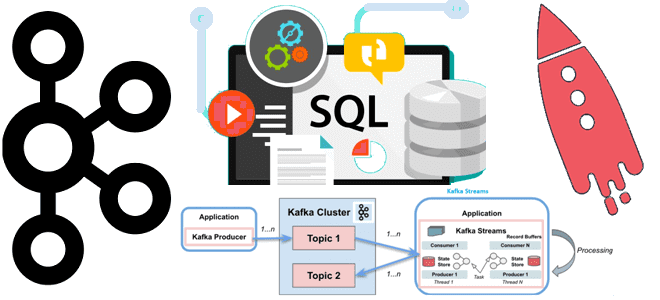
Недавно мы писали, чем Kafka Streams отличается от Consumer API. Сегодня рассмотрим, в чем разница между Kafka Streams и ksqlDB, а также разберем, почему использовать этот компонент экосистемы Apache Kafka не так просто. Как работает ksqlDB: практический пример Apache Kafka является полноценной экосистемой потоковой передачи, вокруг которой существует множество полезных...
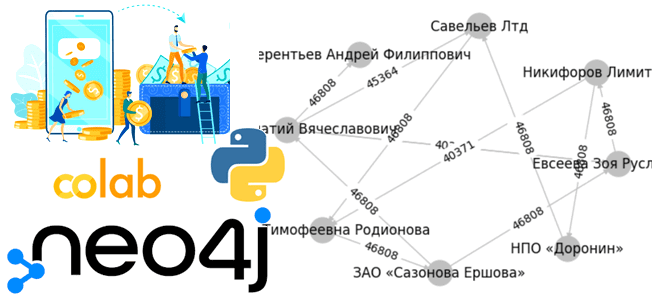
Чтобы показать еще один вариант использования графовой базы данных Neo4j, сегодня реализуем небольшое Python-приложение, которое генерирует граф знаний в облачной платформе Aura DB. Ищем финансовые переводы между компаниями и физическими лицами, считаем общую сумму и визуализируем найденные транзакции с помощью библиотеки Networkx. Python-приложение для работы с Neo4j в AuraDB Как...
Чтобы сделать наши курсы для специалистов по Data Science и ML-инженеров еще более полезными, сегодня познакомимся с очень мощным инструментом MLOps – open-source платформой ClearML. Что это такое, как работает, насколько упрощает разработку продуктов Machine Learning, а также зачем бизнесу ClearGPT. Что такое ClearML и как это поможет MLOps-инженеру Концепция...
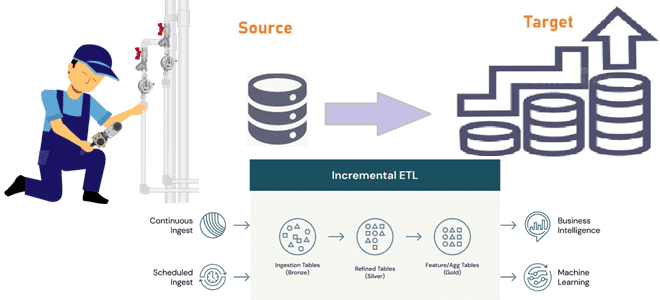
Инкрементные конвейеры загрузки больших объемов данных в корпоративное хранилище или озеро как самый экономичный способ масштабирования архитектуры данных. Разбираемся, как дата-инженеру эффективно организовать такие ETL-конвейеры. 2 способа организации конвейеров инкрементной загрузки данных Инкрементный ETL (Extract, Transform and Load) для классического DWH стал обычным явлением с источниками CDC (сбор данных об...
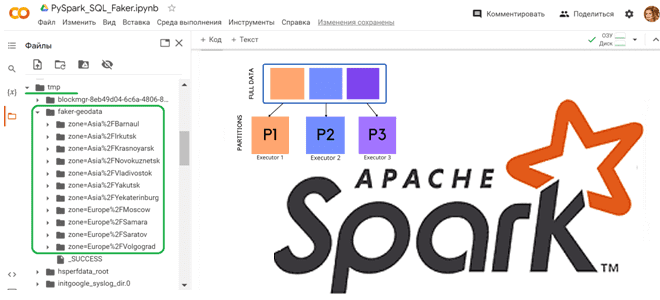
Как сгенерировать набор тестовых данных с Python-библиотекой Faker и разделить данные по разделам, используя функцию partitionBy() в PySpark. Работаем с Apache Spark в Google Colab. Как работает partitionBy() в Apache Spark Чтобы записать на диск один большой датафрейм, разделив его на несколько более мелких файлов, в Python API фреймворка Apache...
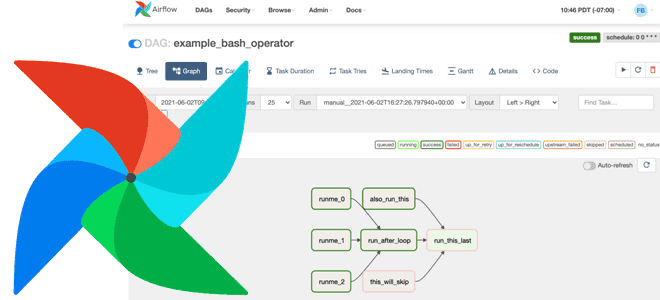
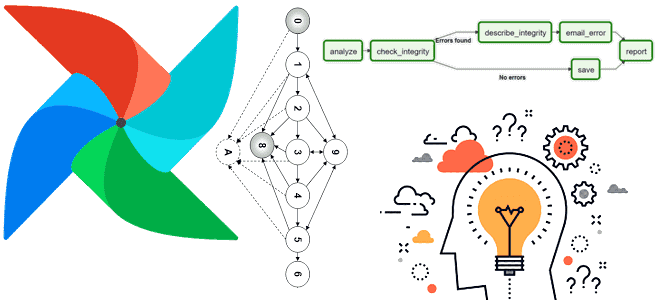
Сегодня рассмотрим, какие ошибки, связанные с DAG, отображаются в пользовательском интерфейсе Apache AirFlow и как дата-инженеру их исправить. А также рассмотрим еще несколько рекомендаций по повышению эффективности этого фреймворка. 4 ошибки с DAG в интерфейсе Apache AirFlow и как их исправить Сегодня все больше компаний, независимо от их домена и...

Мы уже писали про тестирование приложений Apache Flink, используя SQL-клиентов, Table API, тестовые наборы операторов и режим локального мини-кластера. Сегодня рассмотрим, как с помощью тестовых наборов тестировать UDF-функции, использующих состояние и таймеры. Модульное тестирование UDF-функций Flink-приложения с помощью тестовых наборов При работе с Apache Flink разработчики часто сталкиваются с проблемами при...
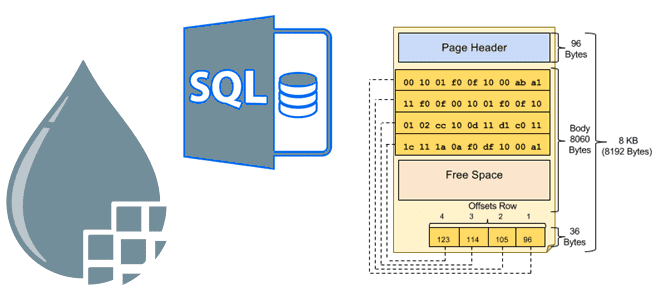
Как с помощью Apache NiFi запрашивать информацию из баз данных постранично. Разбираемся с возможностями и рисками использования процессоров NiFi для пагинации в SQL-запросах. Пагинация баз данных и процессоры Apache NiFi Apache NiFi позволяет запрашивать из баз данных целые таблицы с помощью разбиения на страницы, т.е. пагинации. Напомним, базы данных хранят...
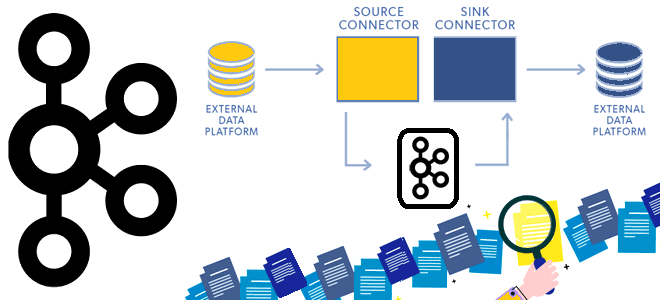
Сегодня рассмотрим принципы работы компонента экосистемы Apache Kafka под названием Connect и разберемся, как он устроен. Программная архитектура коннекторов и способы избежать дубликатов при зависании внешней системы-приемника. Архитектура и принципы работы Kafka Connect Apache Kafka не зря считается платформой потоковой передачи, а не просто брокером сообщений. Вокруг нее выстроена целая...

Как сделать запуск UDF-функций Python или R на узлах сегмента Greenplum более быстрым и безопасным с помощью Docker-контейнеров и расширения PL/Container. Что такое PL/Container и как это использовать в Greenplum Запуск пользовательского кода для базы данных всегда имеет риск нарушения информационной безопасности. Если речь идет о стеке Big Data, ущерб...
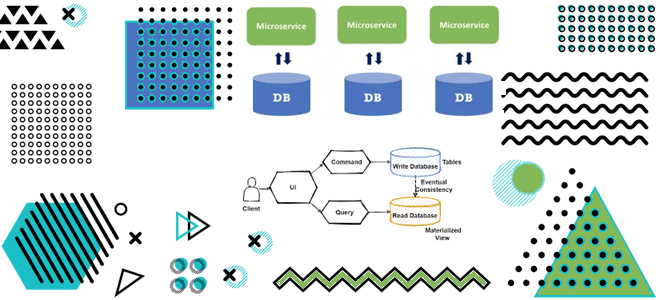
Как материализованные представления в потоковой базе данных с CDC-подходом и шаблоном CQRS позволяют реализовать масштабируемую и высокопроизводительную систему с микросервисной архитектурой для транзакций и аналитики данных в реальном времени. Разбираемся с паттернами проектирования микросервисов на примере интернет-магазина. Что не так с шаблоном композиция API и другие проблемы микросервисной архитектуры в...

Что появилось нового в мажорном релизе самой популярной Python-библиотеки pandas, чем она похожа на Rust-пакет с Python API polars и в чем между ними разница: тестирование производительности и польза для дата-инженера. Главные новинки pandas 2.0 3 апреля 2023 года вышел долгожданный релиз Python-библиотеки pandas, которая для многих дата-инженеров, аналитиков данных...
В этой статье для обучения дата-инженеров рассмотрим типы оповещений в Apache AirFlow и их отслеживание в сервисе мониторинга cron-заданий Healthchecks.io. Оповещения Apache AirFlow: какие они бывают и зачем их отслеживать Apache AirFlow позволяет создавать сложные конвейеры обработки данных, которые могут выполняться по расписанию, по событию или запускаться вручную. Для повышения...
Сегодня вспомним, какие процессоры есть в Apache NiFi для работы с HTTP-запросами, зачем их так много, чем они отличаются и в каких случаях использовать каждый из них. Разница между HandleHttpRequest, HandleHttpResponse, GetHTTP, PostHTTP, InvokeHTTP и ListenHTTP. Мы с Тамарой ходим парой: совместное использование процессоров HandleHttpRequest и HandleHttpResponse На первый взгляд...
Обогащение потока данных информацией из внешнего API без остановки вычислений: 3 способа реализовать это средствами Apache Flink на примере сервиса геолокации. Зачем обогащать потоковые данные через внешний API и как это сделать для Flink-приложения? Иногда необходимо обогатить потоки данных, т.е. дополнить потоковые данные в реальном времени, т.е. на лету, не...
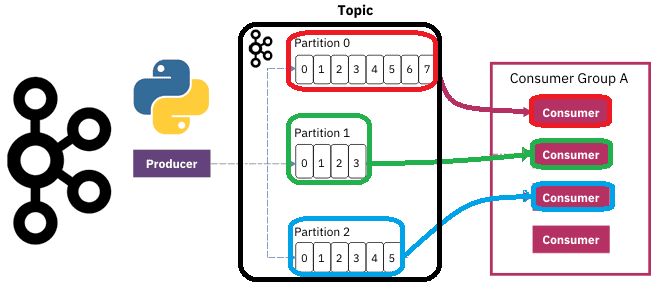
Чтобы разобраться, как на самом деле работают разделы и потребители Apache Kafka, сегодня рассмотрим небольшой демонстрационный пример, иллюстрирующий потребление сообщений. Пишем Python-скрипты публикации и потребления сообщений из разных разделов топика Kafka с занесением данных в несколько вкладок Google-таблицы. Как сообщения распределяются по разделам топика Kafka Напомним, в Apache Kafka раздел...