 554
554 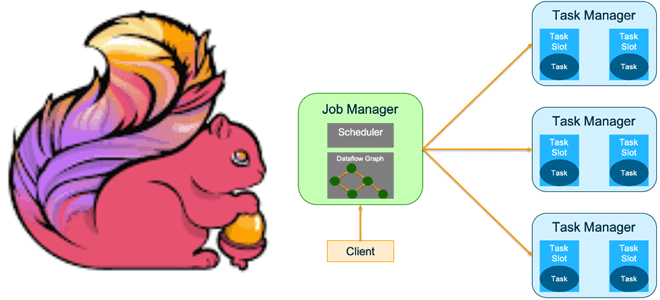
Содержание
Какие режимы развертывания заданий поддерживает Apache Flink и чем они отличаются. Достоинства и недостатки режима сеанса и режима приложения, а также варианты использования.
Особенности развертывания приложения Apache Flink
Режим развертывания определяет, с каким уровнем изоляции ресурсов задание Flink будет выполняться в кластере. Напомним, выполнение задания Apache Flink включает 3 объекта: Клиент, менеджер заданий (JobManager) и менеджер задач (TaskManagers). Клиент отвечает за отправку задания в кластер, JobManager обеспечивает контроль во время выполнения, а диспетчеры задач выполняют фактические вычисления. Подробнее про архитектуру фреймворка читайте в нашей новой статье.
Выполнение задания Flink состоит из двух этапов: предварительного main(), когда вызывается пользовательский метод; и runtime, который запускается, как только вызывается пользовательский код execute(). Метод main() создает пользовательскую программу, используя какой-либо API Flink (DataStream, Table или DataSet). Когда метод main() вызывается env.execute(), определяемый пользователем конвейер преобразуется в форму, понятную среде выполнения Flink, называемую графом заданий, и отправляется в кластер. Сегодня фреймворк поддерживает развертывание задания в режиме сеанса и в режиме приложения. Различия между режимами связаны с жизненным циклом кластера и гарантиями изоляции ресурсов, которые они обеспечивают. Далее рассмотрим их более подробно.
Режим сеанса
В режиме сеанса метод задания main(), т.е. предварительная фаза, выполняется на стороне клиента. В большинстве случаев это не проблема для пользователей, которые уже имеют все зависимости своих заданий локально и затем отправляют свои приложения через работающий клиент. Но в случае отправки через удаленный объект необходимо сперва загрузить локальные зависимости и лишь потом отправить их вместе с графом заданий в кластер. Это делает Клиента интенсивным потребителем ресурсов сети для загрузки зависимостей и отправки двоичных файлов в кластер. Также клиентское задание потребляет циклы ЦП для выполнения метода main(), что особенно заметно, если несколько пользователей используют один и тот же Клиент.
Таким образом, режим сеанса предполагает наличие уже работающего кластера и использует ресурсы этого кластера для выполнения любого отправленного приложения. Задания, выполняемые в одном и том же (сеансовом) кластере, используют одни и те же ресурсы и конкурируют за них. Преимущество этого режима в том, что не придется платить за ресурсы, связанные с развертыванием полного кластера для каждого отправленного задания. Но если одно из заданий ведет себя некорректно или приводит к сбою диспетчера задач, то сбой затронет все задания, выполняемые в этом диспетчере. Помимо негативного воздействия на задание, вызвавшее сбой, это подразумевает потенциальный масштабный процесс восстановления, при котором все задания перезапуска одновременно обращаются к файловой системе и делают ее недоступной для других служб. Кроме того, наличие одного кластера, выполняющего несколько заданий, подразумевает большую нагрузку на JobManager, который отвечает за учет всех рабочих процессов в кластере. Поэтому режим сеанса идеально подходит для коротких заданий, где задержка при запуске имеет большое значение, например интерактивные запросы, когда жизненный цикл кластера не зависит от выполняемых заданий, и все задания, выполняемые в кластере, совместно используют его ресурсы. Для всех заданий в кластере имеется один диспетчер задач, а задачи назначаются диспетчерам случайным образом.
Режим приложения
Развертывание в режиме приложения создает кластер для каждого отправленного задания, но на этот раз метод main() выполняется в диспетчере заданий. Создание кластера для каждого задания можно рассматривать как создание кластера сеансов, совместно используемого только заданиями конкретного приложения и удаляемого после завершения работы приложения. Благодаря этой архитектуре режим приложения обеспечивает высокие гарантии изоляции ресурсов и балансировки нагрузки, но с степенью детализации всего приложения. Ожидается, что задания, принадлежащие одному и тому же приложению, будут коррелировать между собой и рассматриваться как единое целое. Выполнение метода main() в диспетчере заданий позволяет сэкономить циклы ЦП, необходимые для извлечения графа задания, а также полосу пропускания сети, необходимую клиенту для локальной загрузки зависимостей и отправки графа задания и его зависимостей в кластер. Кроме того, нагрузка на сеть распределяется более равномерно, поскольку на каждое приложение приходится только один диспетчер заданий.
В режиме приложения метод main() выполняется на кластере, а не на клиенте, как в других режимах. Поэтому все пути, которые разработчик Flink-приложения регистрирует в своей среде с помощью RegisterCachedFile(), должны быть доступны через диспетчер заданий. Режим приложений позволяет отправлять в кластер приложения, состоящие из нескольких заданий. На порядок выполнения задания влияет не режим развертывания, а вызов, используемый для запуска задания. Использование метода блокировки execute() устанавливает порядок и приводит к отложению выполнения следующего задания до завершения предыдущего. Напротив, неблокирующий асинхронный executeAsync() метод немедленно продолжит отправку следующего задания, как только будет отправлено текущее задание. За счет выполнения метода приложения main() в JobManager режим приложения позволяет сэкономить много ресурсов, которые ранее требовались при отправке задания.
Сравнение режимов развертывания: что и когда выбирать
Познакомившись с режимами развертывания задания Flink, сравним их по следующим критериям:
- особенности развертывания;
- жизненный цикл кластера;
- использование ресурсов;
- преимущества;
- недостатки;
- варианты использования.
Визуализируем сходства и отличия по этим критериям в таблице.
|
Критерий |
Режим сеанса |
Режим приложения |
|
Особенности развертывания |
Не нужно развертывать весь кластер Flink, достаточно создать и развернуть JAR-архив с исправлениями или улучшениями кода. Для остановки и отправки задания можно использовать REST API или shell-скрипт.
|
Необходимо развертывать образ Flink каждый раз, когда задание помещается в папку lib. По сути, задание Flink представляет собой большой JAR-архив, содержащий логику и зависимости. В режиме приложения кластер Flink, выполняющий задание, специально создан для выполнения только отправленного задания. При исправлении или изменении задания придется создать новый образ Flink, содержащий обновленный JAR-файл задания, а затем обновить свой кластер. |
|
Жизненный цикл кластера |
Развертывание задания будет выполнено в кластере сеансов Flink, который может использоваться совместно с другими развертываниями. Жизненный цикл кластера Flink не зависит от жизненного цикла развертывания. |
Развертывание каждого задания будет выполнено в отдельном кластере Flink. Жизненный цикл кластера Flink привязан к жизненному циклу развертывания. |
|
Использование ресурсов |
Один и тот же кластер повторно используется более чем одним заданием. |
Нет никакого совместного использования ресурсов с другими заданиями. Все ресурсы кластера, выделенные для задания, предназначены только для него и используются лишь им. |
|
Преимущества |
Упрощение отладки — необходимо исправить только задание Flink в JAR-архиве, остановив существующее задание и отправив в кластер новое. |
Высокая безопасность за счет абсолютной изолированности. |
|
Недостатки |
Менее безопасно, поскольку в каждом кластере выполняется несколько заданий. Совместное использование ресурсов требует больше вычислений на узел для удовлетворения требований al__cpLocation к ресурсу задания. Если по какой-либо причине кластер Flink выйдет из строя, это повлияет на выполнение всех заданий. |
Для обновления придется обновлять кластер Flink каждый раз, включая удаление с последующей установкой или обновление с помощью Helm-диаграммы для Kubernetes. В обоих случаях придется повторно запустить кластер, обнулив ранее сформированные контрольные точки (checkpoints). |
|
Варианты использования |
В целом совместное использование кластера Flink в нескольких развертываниях более эффективно с точки зрения ресурсов, но может привести к конкуренции за ЦП и память между выполняемыми заданиями Flink и корреляции сбоев заданий Flink. Этот режим подходит для коротких заданий, где задержка при запуске имеет большое значение, например интерактивные запросы, когда жизненный цикл кластера не зависит от выполняемых заданий, и все задания, выполняемые в кластере, совместно используют его ресурсы. |
Этот режим хорош, когда нужно запустить несколько длительных заданий, каждое из которых должно выполняться совершенно автономно, независимо от других, в своем собственном кластере Flink. |
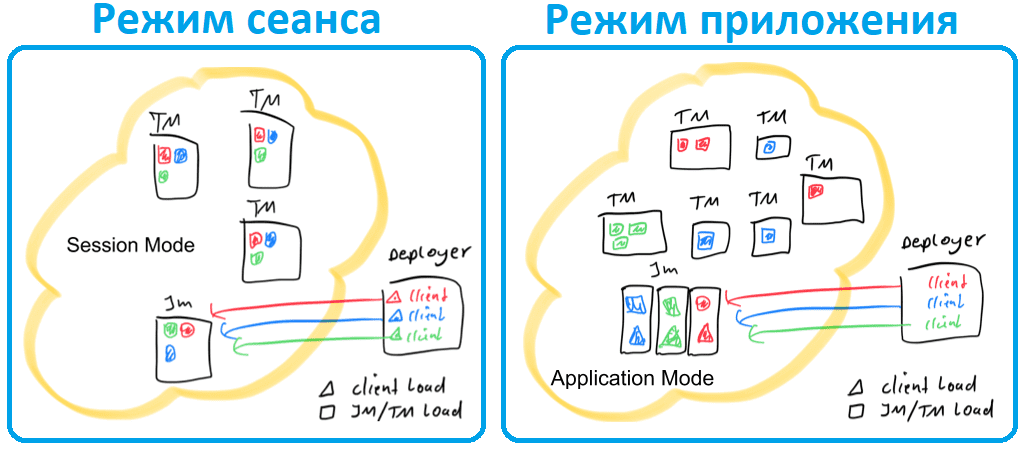
Таким образом, в режиме сеанса можно быстрее начать разработку, но в производственном развертывании все равно придется переходить в режим приложения.
Читайте в нашей новой статье про особенности разработки и развертывания Flink-приложений, созданных с использованием API Stateful Functions, который упрощает создание распределенных приложений с отслеживанием состояния с помощью среды выполнения, созданной для бессерверных архитектур. А здесь вы узнаете, как настроить потоковый конвейер Flink-приложений в зависимости от сценария нагрузки.
Освойте возможности Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

