
Как использовать DataStream API в Apache Flink: пишем потребителя из Kafka и запускаем скрипт в Google Colab. StreamExecutionEnvironment и методы коллекций потока данных в PyFlink. DataStream API в Apache Flink: PyFlink в Google Colab для работы с Kafka Apache Flink предоставляет множество возможностей разработчикам на Scala и Java, а также...
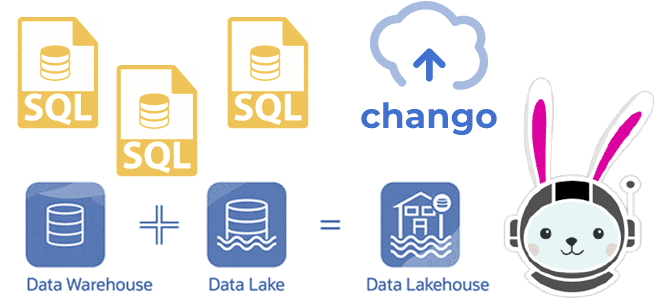
Как реализовать гибридную архитектуру данных Lakehouse на новой платформе Chango с движком обработки распределенных запросов Trino без дополнительного развертывания кластера Kafka и разработки Spark-приложений потоковой передачи событий. Что такое Trino: принципы работы распределенного SQL-движка О том, что представляет собой новая гибридная архитектура данных под названием Lakehouse, мы подробно писали здесь,...
Проблемы анализа данных временных рядов и способы их решения: какие статистические методы и алгоритмы глубокого обучения лучше подходят для прогнозирования. Особенности прогнозирования временных рядов Напомним, временным рядом считается набор данных, каждая точка которого привязана ко времени (час, минуты, дни, месяцы, годы и прочие периоды). Эти данные имеют динамический характер и...

Где создать граф знаний и попробовать графовые алгоритмы для решения бизнес-задач: смотрим варианты запуска графовой СУБД на примере Neo4j. 4 варианта запуска Neo4j Neo4j является ярким представителем нереляционных СУБД и относится к категории графовых баз. Она поддерживает специализированные алгоритмы работы с графами, включая поиск путей, выявление сообществ, анализ связей и...
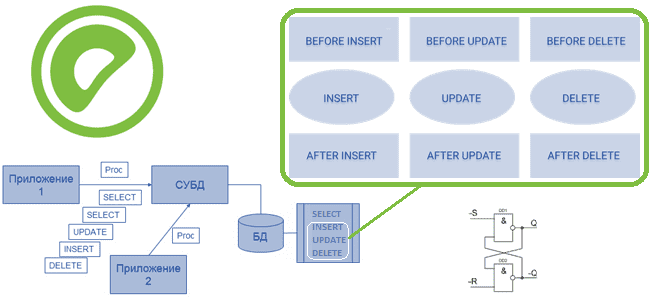
Где и как используются триггеры, чем они отличаются от хранимых процедур, как это реализуется в Greenplum. Создание, изменение и удаление триггеров и ограничения их применения в Greenplum. Что такое хранимые процедуры и триггеры Напомним, хранимые процедуры представляют собой именованные блоки SQL-команд, которые заранее откомпилированы и хранятся на сервере, чтобы ускорить...

Как обеспечить безопасное подключение процессора InvokeHTTP к внешнему API, настроив SSL-службу контекста в Apache NiFi. Краткий ликбез по SSL-соединению и реализации API службы контроллера SSLContextService в Apache NiFi для дата-инженера. Безопасность работы с внешним API с SSL-соединением Apache NiFi включает множество процессоров – обработчиков, которые выполняют определенные действия с потоковыми...

Недавно мы разбирали, как дата-инженеру написать собственный оператор Apache AirFlow и использовать его в DAG. Сегодня посмотрим, каким образом с этой задачей справляется модный ИИ под названием ChatGPT. GPT-генерация пользовательского оператора AirFlow Хотя Apache AirFow предоставляет множество операторов для выполнения самых разных задач, иногда дата-инженеру приходится писать свои собственные Python-классы,...

Как разработчику выбрать подходящий режим развертывания для своего Spark-приложения, достоинства и недостатки клиентского и кластерного режимов, а также особенности запуска под управлением YARN. Архитектура и режимы развертывания Spark-приложения Будучи фреймворком для создания приложений быстрой обработки Big Data, Apache Spark имеет несколько режимов развертывания, которые зависят от варианта запуска Spark-приложения: на...
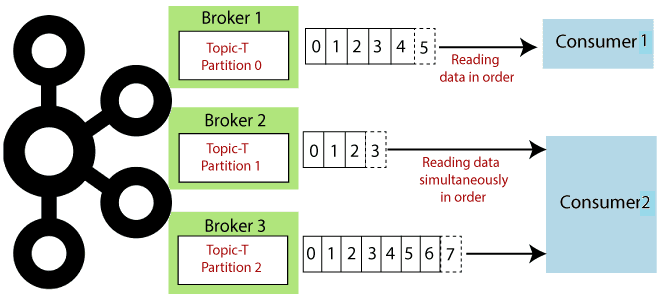
Что общего у Kafka Streams и Consumer API, чем они отличаются и что выбирать для практического использования: краткое руководство для разработчика приложений потоковой обработки событий. Возможности и ограничения Kafka Streams и Consumer API Поскольку Apache Kafka как огромная экосистема со множеством компонентов для потоковой передачи событий, обилие и разнообразие этих...
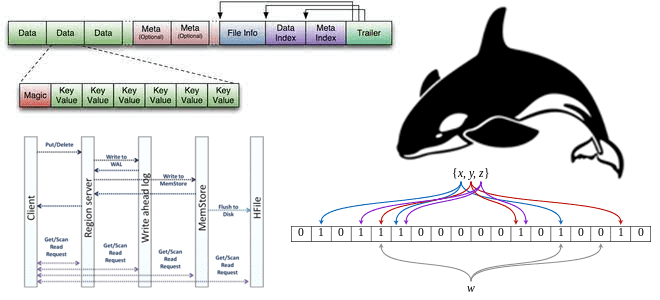
Что такое HFile, как появился этот низкоуровневый файловый формат, каковы его главные принципы работы, как Apache HBase использует его для хранения и быстрой аналитики больших данных, и при чем здесь фильтр Блума. Роль HFile в Apache HBase Apache HBase реализует возможности Google BigTable для Hadoop. Эта NoSQL-СУБД типа «семейство колонок»...

Мы уже упоминали, что в Apache NiFi 1.20 устранена уязвимость CVE-2023-22832, связанная с неправильным ограничением ссылок на внешние объекты XML в процессоре ExtractCCDAAttributes. Сегодня более подробно поговорим про проблемы обработки XML-документов в Apache NiFi и способы их решения. Чем опасны внешние сущности в XML Обработка внешних сущностей XML считается довольно проблемной...

Как не запутаться в многообразии коннекторов к Kafka, доступных во Flink Table API, и выбрать наиболее подходящий для своего сценария применения. Разница между Append Mode и Upsert-режимом коннектора Flink SQL к Kafka. 2 режима работы коннектора Kafka в Apache Flink Apache Flink поставляется с универсальным соединителем Kafka, который поддерживает последнюю...

Что такое потоковая аналитика больших данных, какие бывают СУБД потоковой передачи, когда и зачем их использовать, а также что влияет на выбор этих инструментов хранения и аналитической обработки Big Data. Что такое потоковые базы данных и как они работают Мы уже упоминали, что аналитика данных в реальном времени может быть...
Чего не хватает в PL/Python и зачем нужна еще одна библиотека для создания Python-скриптов обработки данных в Greenplum. Возможности API GreenplumPython и сравнение с pandas. Что такое PL/Python и как это работает в Greenplum Мы уже писали, что Greenplum изначально поддерживает Python, предоставляя PL/Python – загружаемый процедурный язык, который позволяет...
В Apache Spark есть 3 структуры данных, каждая из которых имеет собственный API со своими достоинствами и недостатками. Сегодня разберем плюсы и минусы Dataset API, а также рассмотрим особенности JOIN-операций в нем. Почему Dataset API в Apache Spark работает только со Scala и Java Напомним, структура данных Dataset впервые появилась...
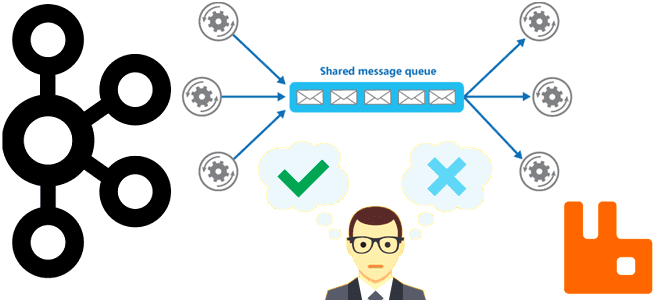
Какие проблемы характерны для распределенных очередей сообщений, почему они случаются и как с ними справиться. Разбираемся со сбоями, ошибками и перегрузками на примере Apache Kafka и RabbitMQ. Проблемы с распределенными очередями и главные причины их появления Хотя Apache Kafka — это целая экосистема со множеством компонентов для потоковой передачи событий,...
Как написать пользовательский оператор Apache AirFlow и использовать его в DAG. А также чем хороши функции обратного вызова вместо XCom, и когда их не следует применять. Создаем свой оператор AirFlow и используем его в DAG Однажды мы уже разбирали, как создать свой оператор Apache AirFlow на примере сенсора – оператора...
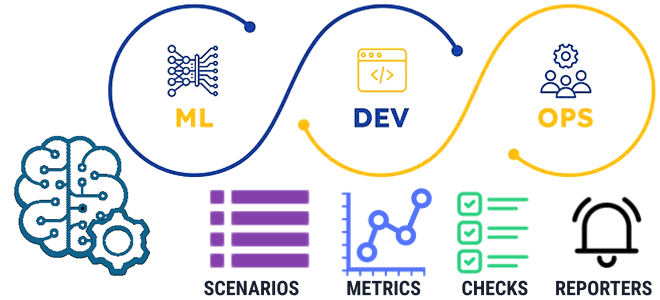
Сегодня посмотрим на MLOps с точки зрения организационного и технического управления, решив вопрос о подходе к разработке ML-системы, а также рассмотрим метрики ее оценки перед развертыванием в production. Управленческий MLOps: 2 подхода к разработке системы Machine Learning Модели машинного обучения могут показывать высокую точность работы своих алгоритмов даже на производственных...
Недавно мы писали про резидентную графовую СУБД Memgraph, которая хранит данные в оперативной памяти. Сегодня рассмотрим, как выгрузить граф знаний из Memgraph на диск с помощью библиотеки GQLAlchemy, а также поговорим про персистентность другого популярного NoSQL-хранилища Redis, которое также является резидентным, но относится к семейству key-value. Как сохранить данные из...
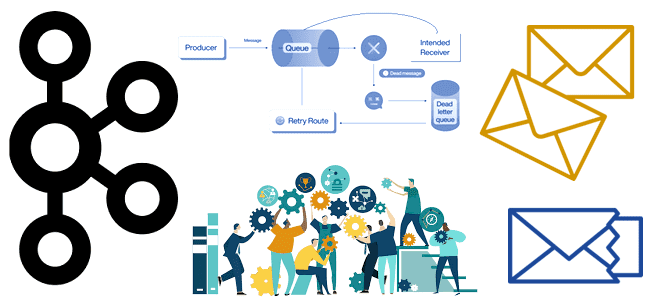
Недавно мы писали про очереди недоставленных сообщений в Apache Kafka и RabbitMQ. Сегодня поговорим про стратегии обработки ошибок, связанные с DLQ-очередями в Kafka, а также рассмотрим, какие сообщения НЕ надо помещать в Dead Letter Queue. 4 стратегии работы с DLQ-топиками в Apache Kafka Напомним, в Apache Kafka в очереди недоставленных...