Почему MCP-серверы с технологиями потоковой передачи событий в LLM стали трендом: примеры обогащения ИИ-агентов контекстом из Kafka.
Внедрение MCP в Confluent Cloud для взаимодействия с Apache Kafka
Хотя MCP-протокол, позволяющий ML-модели новыми контекстными данными, что необходимо для больших языковых моделей (LLM, Large Language Model), довольно прост с технической точки зрения, он имеет большой практический потенциал. Это дает огромные возможности создавать мощные системы агентского ИИ. ИИ-агенты – это системы, в которых LLM динамически управляют собственными процессами и использованием инструментов, сохраняя контроль над тем, как они выполняют задачи.
В отличие от рабочих процессов с использованием LLM, что мы разбирали на примере новых операторов AirFlow, ИИ-агенты хорошо подходят для открытых задач, где трудно или невозможно предсказать необходимое количество шагов и где нельзя жестко определить фиксированный путь решения. Автономность ИИ-агентов делает их идеальными инструментами для масштабирования задач в доверенных средах. Однако, автономная природа агентов означает более высокие затраты и болезненные последствия ошибок.
Текстовый протокол MCP (Model Context Protocol) предоставляет стандартизированный способ подключения LLM к необходимому контексту, позволяя создавать безопасные двусторонние соединения между источниками данных и AI-инструментами. Чтобы выполнять это взаимодействие в режиме потоковой передачи, что крайне важно для LLM, разработчики платформы Confluent реализовали MCP-сервер, который позволяет ИИ-инструментам взаимодействовать с API Confluent Kafka и Confluent Cloud REST: управлять топиками, коннекторами и операторами Flink SQL через формулировки на естественном языке.
Поскольку Confluent уже предоставляет более 120 готовых коннекторов, ИИ-агенты могут взаимодействовать с источниками данных и потоками событий без дополнительной разработки. MCP-сервер позволяет сосредоточиться на бизнес-логике, упрощая процессы инженерии данных за счет их мгновенной доступности через общий интерфейс.
Собрав и запустив MCP-сервер, надо подключить к нему клиента, указав сокет, т.е. хост и порт. После запуска MCP-клиента он будет отправлять запросы на MCP-сервер, который затем будет взаимодействовать с Confluent Cloud.
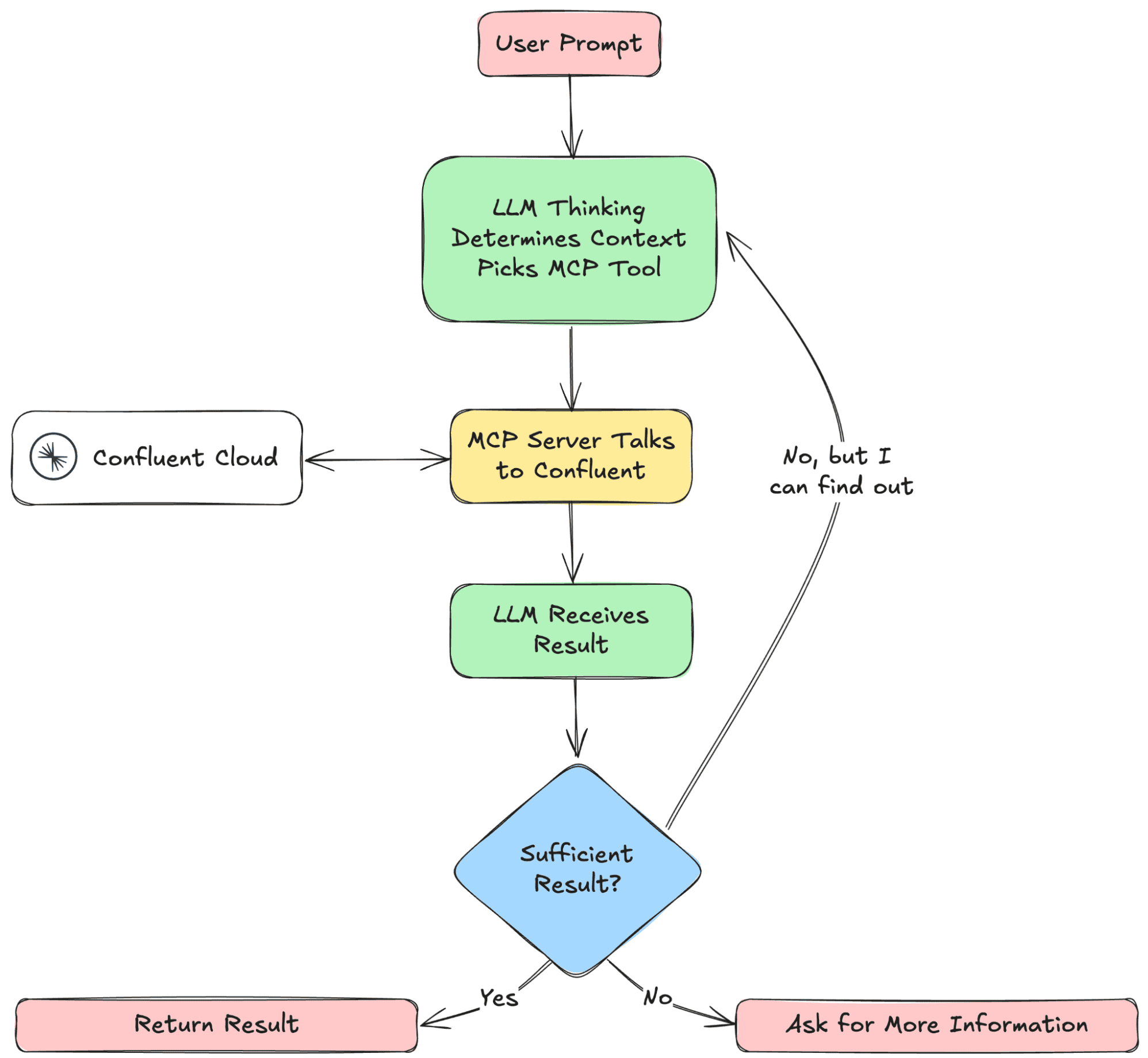
Стандартизированный способ подключения ИИ-агентов к потокам данных в реальном времени, структурированным наборам данных и внешним инструментам устраняет необходимость в индивидуальных одноразовых интеграциях. ИИ-агенты могут извлекать данные из Kafka в реальном времени, выполнять действия и принимать решения на основе последней доступной информации, без необходимости разрабатывать клиентов для каждого источника данных.
А Tableflow позволяет пользователям материализовать топики Kafka и связанные схемы в таблицу Apache Iceberg, объединив данные в реальном времени с множеством исторической информации. Как мы уже писали здесь, Tableflow упрощает наполнение LakeHouse благодаря автоматической генерации метаданных Apache Iceberg на основании реестра схем Confluent и преобразования типов. Также Tableflow экономит потребление дискового пространства за счет непрерывного сжатия небольших Parquet-файлов, обеспечивая хорошую производительность чтения. ETL-процессы с данными в платформе Confluent выполняет интегрированный в нее Apache Flink.
Благодаря этому стеку технологии ИИ-агенты могут выполнять федеративный поиск по векторным хранилищам, базам и озерам данных, запрашивая их в реальном времени из одного интерфейса. LLM-системы могут реагировать на текущие события, сопоставлять их с сохраненными знаниями и генерировать актуальные результаты с непрерывным обновлением контекста.
Потоковое обогащение LLM-инструментов с помощью MCP: пример от Scalytics
Впрочем, потоковое обогащение LLM-инструментов с помощью MCP реализуется не только в платформе Confluent. Например, компания Scalytics использует MCP для безопасной разработки ИИ, сочетая распределенную структуру данных с федеративным обучением, чтобы поддерживать объяснимость и производительность в реальном времени. Многоагентная архитектура LLM управляет кросс-платформенной интеграцией.
Архитектура LLM-платформы Scalytics для анализа конфиденциальных данных с MCP и Kafka
В архитектуре платформы Scalytics для анализа конфиденциальных данных используется MCP-сервер на Python для взаимодействия с различными наборами данных. Внутренний уровень обработки обрабатывает промежуточные результаты с помощью структурированного механизма промптов. Это гарантирует, что конфиденциальные данные остаются в безопасности и обрабатываются строго в определенных границах. Он функционирует как контролируемая среда, в которой необработанные данные преобразуются в рабочие идеи.
За сервером MCP находится специализированный модуль генерации ответов с учетом дополнительно найденной релевантной информации (RAG, Retrieval-Augmented Generation). Этот компонент фильтрует, отслеживает и защищает выходные данные в соответствии с правилами, определенными клиентом. Он обеспечивает соответствие, гарантируя, что никакие конфиденциальные данные не покинут безопасную зону, разрешая только проверенные ответы на запросы.
Kafka действует как высокопроизводительный, отказоустойчивый брокер сообщений для промежуточных результатов. Обеспечивая надежный поток данных в реальном времени, Kafka обеспечивает бесперебойную связь между этапами обработки и гарантирует, что система легко масштабируется при возрастающих нагрузках.
Унифицированный фреймворк обработки данных Apache Wayang обеспечивает абстракцию между пользовательскими приложениями и базовыми платформами обработки данных, гарантируя бесшовную интеграцию и оптимизацию. Подобно Apache Beam, Wayang предоставляет единый интерфейс, позволяющий писать код один раз и запускать его на разных вычислительных движках: Flink, Spark и пр., без необходимости внесения изменений в сам код. Однако, Beam предоставляет унифицированную модель для написания конвейеров обработки данных, которые затем выполняются на одном выбранном движке, а Wayang фокусируется на интеграции нескольких движков и распределении задач между ними. Подробнее об отличиях Beam и Wayang поговорим в другой раз, а сейчас вернемся к архитектуре LLM-платформы Scalytics для анализа конфиденциальных данных с MCP и Kafka. В этой платформе Wayang выполняет аналитические задачи полностью в пределах безопасного периметра. Эти планы разработаны для обработки конфиденциальных запросов с сохранением соответствия строгим политикам управления данными. Промежуточные результаты передаются через Kafka для последующей обработки или ответа клиенту.
Одним из ключевых принципов платформы Scalytics является то, что данные остаются в источнике. Вместо перемещения конфиденциальных данных между средами система использует локальные LLM или специализированные языковые модели (SLM), которые обучаются с помощью закрытых данных. Эти модели работают в безопасной зоне, обеспечивая соответствие требованиям управления данными. Для мониторинга и ограничения поведения агентов установлены защитные ограждения, гарантирующие, что они не раскроют несанкционированные данные во время обработки. Такой подход предотвращает утечку данных и сохраняет целостность конфиденциальной информации, обеспечивая надежные аналитические возможности.
Клиент отправляет запросы или задачи на MCP-сервер, который действует как шлюз к системе. MCP-сервер извлекает данные из указанных коллекций или обрабатывает промежуточные результаты через модуль RAG. Модульная конструкция MCP-сервера поддерживает интеграцию с клиентскими системами по принципу «plug-and-play», сокращая время внедрения нового источника данных. Вся обработка данных происходит в безопасной зоне, соблюдая требования соответствия. План Wayang выполняется в безопасной зоне, а результаты передаются через Kafka для дальнейшего использования. Kafka обеспечивает отказоустойчивую связь между компонентами в режиме реального времени, сводя к минимуму задержки.
Такая архитектура подходит для сценариев, где необходимо сочетать безопасность и высокую производительность, например:
- обработка конфиденциальных финансовых данных с соблюдением строгих требований;
- обеспечение промышленного мониторинга и аналитики в режиме реального времени для повышения эффективности работы;
- поддержка анализа медицинских данных в соответствии с требованиями HIPAA для развития здравоохранения.
Таким образом, внедрение LLM-инструментов в платформы данных уже стало трендом текущего года. А MCP-протокол и технологии потоковой передачи событий позволяют реализовать его на практике. А как построить на основе локальный ИИ-агентов мультиагентную систему, читайте в нашей новой статье.
Узнайте больше про машинное обучение и ИИ на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

