 1062
1062 
Содержание
Что не так с классическими ETL/ELT-конвейерами транзакционных и аналитических систем в гибридное хранилище LakeHouse, и как дата-инженеры платформы Confluent хотят решить эти проблемы с помощью Tableflow, передавая события из Kafka в таблицы Iceberg.
Очередная попытка унификации пакетной и потоковой парадигмы
Чтобы обеспечивать потребности современного бизнеса в пакетной и потоковой аналитике, типовые архитектуры данных постоянно развиваются. В частности, HTAP-хранилища данных становятся все более распространенными. При этом в качестве основного уровня хранения для облачных систем все чаще используются объектные хранилища, а потоковая передача представляется как обобщение пакетной парадигмы. Неограниченные данные — это надмножество ограниченных данных: пакетные и потоковые задания имеют временные окна обработки, хотя на практике исторические данные и события в реальном времени поступают из разных систем.
Чтобы потоковая обработка стала действительно эффективной, она должна охватывать набор возможностей пакетной: способность управлять большими таблицами состояний и повторно обрабатывать большие исторические данные по мере изменения бизнес-логики. При этом надо объединить два разных режима обработки данных без резкого переключения с одного на другой. Поэтому в начале 2020 года появилась гибридная архитектура LakeHouse, которая сочетает достоинства классических хранилищ данных (DWH) с гибкостью озер данных (Data Lake). Подробно об этой архитектуре данных мы писали здесь. Одним из наиболее популярных форматов хранения данных в LakeHouse стал Apache Iceberg,оптимизированный для высокопроизводительного чтения огромных аналитических таблиц, включая функции сериализуемой изоляции, перемещения во времени на основе моментальных снимков и предсказуемой эволюции схемы. Чтобы в реальном времени передавать данные из транзакционных и аналитических систем в LakeHouse, приходится выполнять множество ETL/ELT-операций. Это снижает производительность и увеличивает задержку.
Например, передача операционных данных из Kafka в корпоративные хранилища и озера данных в формате Apache Iceberg — довольно сложный, дорогостоящий и подверженный ошибкам процесс, требующий создания пользовательских конвейеров данных. В этих пользовательских конвейерах данных необходимо передавать данные, используя sink-коннекторы, очищать их, управлять схемой, материализовать CDC-потоки, преобразовывать и сжимать данные, а также сохранять их в форматах таблиц Parquet и Iceberg. Этот сложный рабочий процесс требует значительных усилий и опыта для обеспечения согласованности данных и соответствия требованиям по качеству и производительности.
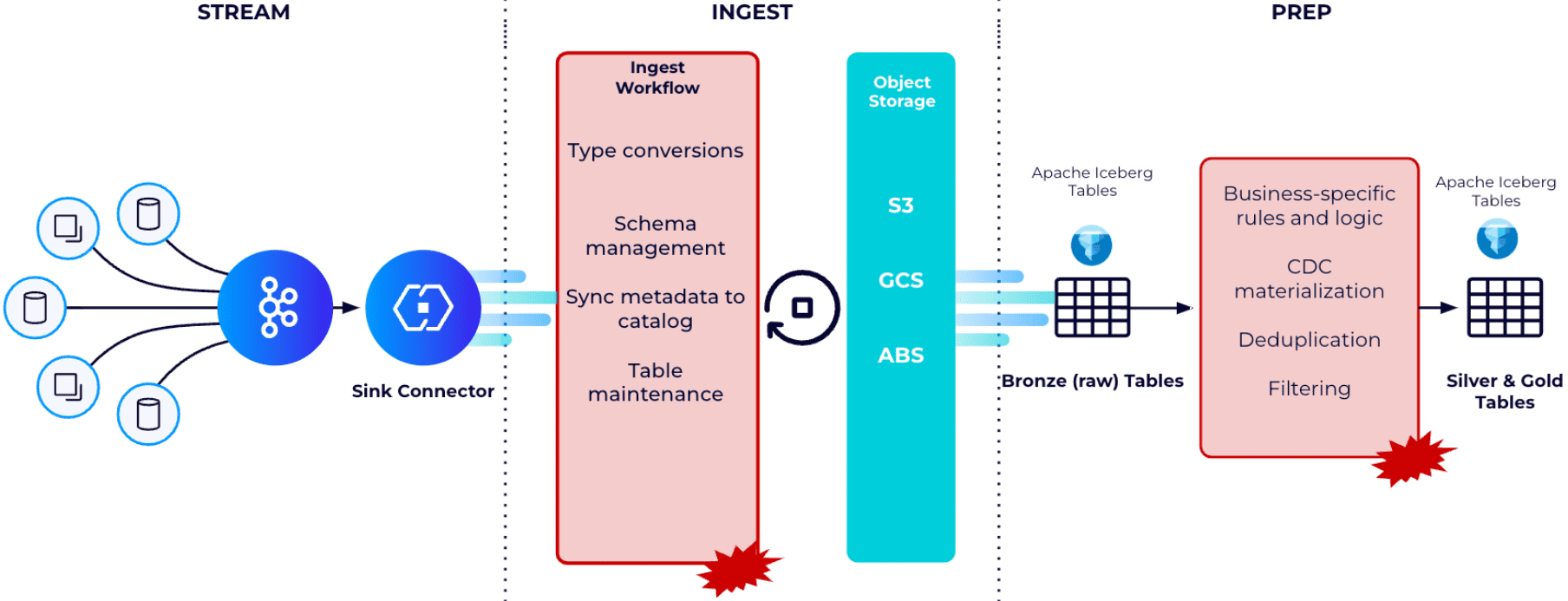
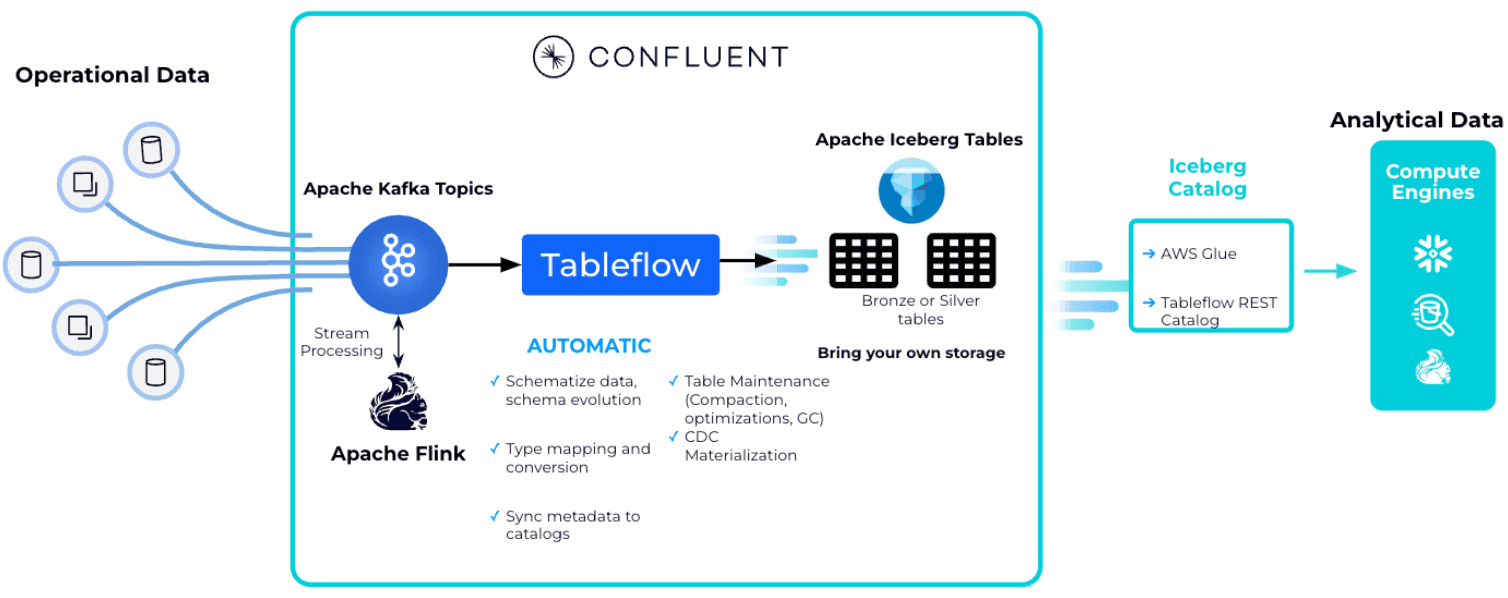
Поэтому, чтобы оперативно передавать данные из топиков Kafka в таблицы Apache Iceberg, разработчики платформы Confluent выпустили TableFlow — инструмент непрерывной оптимизации производительности чтения с помощью сжатия файлов, поддержания эффективного хранения и извлечения данных путем изменения размера файлов и управления потоком данных. Он позволяет пользователям материализовать топики Kafka и связанные схемы в таблицу Apache Iceberg. Как это устроено, рассмотрим далее.
Место TableFlow в экосистеме Kafka Confluent
TableFlow использует облачный движок Kora Confluent и его уровень хранения для преобразования сегментов Kafka в другие форматы. Kora — это многопользовательский серверный движок Kafka внутри Confluent Cloud. Он был разработан для предоставления виртуальных кластеров Kafka поверх общих физических кластеров на основе модифицированной версии Apache Kafka. Архитектура Kora представляет собой один из легких прокси-слоев поверх быстрого отказоустойчивого кэша, который асинхронно выгружает данные в облачное объектное хранилище как основное место хранения данных. Этот быстрый отказоустойчивый кэш позволяет асинхронно выгружать данные большими пакетами, что соответствует экономической модели API облачного объектного хранилища (меньше крупных запросов на большее количество мелких запросов). Отказоустойчивый уровень кэширования состоит из большого количества брокеров Kora на основе Apache Kafka, которые реплицируют записи по нескольким брокерам и зонам доступности, прежде чем отправлять подтверждение клиенту. Каждый брокер Kora хранит локально последовательно согласованную копию метаданных. Это снижает нагрузку на контроллеры KRaft, поскольку перезапуски брокера не требуют от брокера повторной синхронизации всех метаданных ресурсов кластера, как это было с ZooKeeper. Будучи разработанным для многопользовательской работы, движок Kora обеспечивает мультиарендный доступ, регулируя нагрузку брокеров на основе динамических квот, назначаемых централизованной службой общих квот. Эта служба отвечает за расчет и распространение пар квот пропускной способности брокер-арендатор, которые изменяются в зависимости от распределения нагрузки и нагрузки на уровне брокера. Брокеры периодически делятся информацией о потреблении и регулировании пропускной способности на арендатора и на брокера с общей службой квот.
Однако, API Kafka не очень хорошо подходит для аналитических движков и систем, полагающихся на колоночную организацию данных, например, Trino, Spark или BigQuery. Tableflow объединяет транзакционную и аналитическую обработку, предлагая потоковую семантику, ориентированную на строки, для приложений и табличную семантику, ориентированную на столбцы, для аналитических систем. Iceberg также может выполнять потоковую передачу. Apend Only таблицы Iceberg по сути являются потоками, которые могут быть обработаны инкрементно с использованием потоковых или таблично-ориентированных API.
Использование Iceberg в качестве формата хранения данных позволяет заменить собственный формат многоуровневого хранения в Kafka файлами Parquet и метаданными Iceberg напрямую. Это создает представление хранилища с нулевым копированием потока как единого связного набора данных через брокеры Kora и хранилище объектов. Механизм хранения Kora обрабатывает это многоуровневое хранение Iceberg/Parquet, обеспечивая сжатие файлов объектного хранилища, сохранение, оптимизацию хранения и эволюцию схемы между схемами топиков Kafka и таблицами Iceberg. Потребители данных могут получать доступ к многоуровневым данным напрямую как к таблицам Iceberg или потреблять весь поток от брокеров Kora с помощью API Kafka.
Кроме того, TableFlow использует реестр схем Confluent для генерации метаданных Apache Iceberg при обработке сопоставления схем, схем, эволюции и преобразований типов. Данные могут поступать из платформы Confluent, где они обогащаются и фильтруются, непосредственно в аналитическое хранилище. Табличный способ представления данных в Apache Iceberg позволяет использовать SQL-запросы для аналитики.
Таким образом, Tableflow позволяет упростить наполнение LakeHouse благодаря автоматической генерации метаданных Apache Iceberg на основании реестра схем Confluent и преобразования типов. Кроме управления схемами, Tableflow также непрерывно сжимает небольшие Parquet-файлы, созданные постоянной потоковой передачей в более крупные файлы, чтобы поддерживать хорошую производительность чтения. Благодаря интеграции Apache Flink в платформу Confluent для очистки, обработки или обогащения данных в потоке, в Iceberg-таблицы LakeHouse будут попадать только качественные данные.
Доступ к таблицам Apache Iceberg реализуется через REST API каталога Iceberg с ключом и секретом Confluent Cloud в качестве учетных данных. Пока Tableflow хранит данные в Confluent Cloud, но в следующих версиях можно будет хранить метаданные Apache Iceberg и файлы Parquet в любом объектном хранилище.
Узнайте больше про построение сложных архитектур данных и использование Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.somerfordassociates.com/blog/what-is-confluent-tableflow/
- https://www.confluent.io/blog/introducing-tableflow/
- https://www.confluent.io/blog/unify-streaming-and-analytical-data-with-confluent-tableflow-and-amazon-sagemaker-lakehouse/
- https://jack-vanlightly.com/blog/2024/3/19/tableflow-the-stream-table-kafka-iceberg-duality

