
Почему генеративный ИИ основан на потоковой обработке данных и EDA-архитектуре, для чего оценивать качество LLM-модели и как построить такую систему мониторинга: подходы и технологии.
О важности потоковой обработки данных и EDA-архитектуры для LLM-систем
Все больше современных бизнес-приложений включают в себя большие языковые модели (LLM, Large Language Model), чтобы автоматизировать поддержку клиентов, анализ пользовательского поведения и работу с документацией. При этом технологической основой LLM-систем является потоковая, а не пакетная парадигма обработки данных, поскольку в генеративном искусственном интеллекте (ИИ) применяются повторно используемые базовые модели. Первичное обучение базовых моделей на разных доменах дополняется специфическим контекстом при онлайн-запросе, что почти невозможно в пакетной обработке. В отличие от традиционного ML, где модель обучается на данных, специфичных для приложения, LLM обучаются на общей информации. Использование специфичных данных, происходит во время оперативной сборки, а не при создании модели.
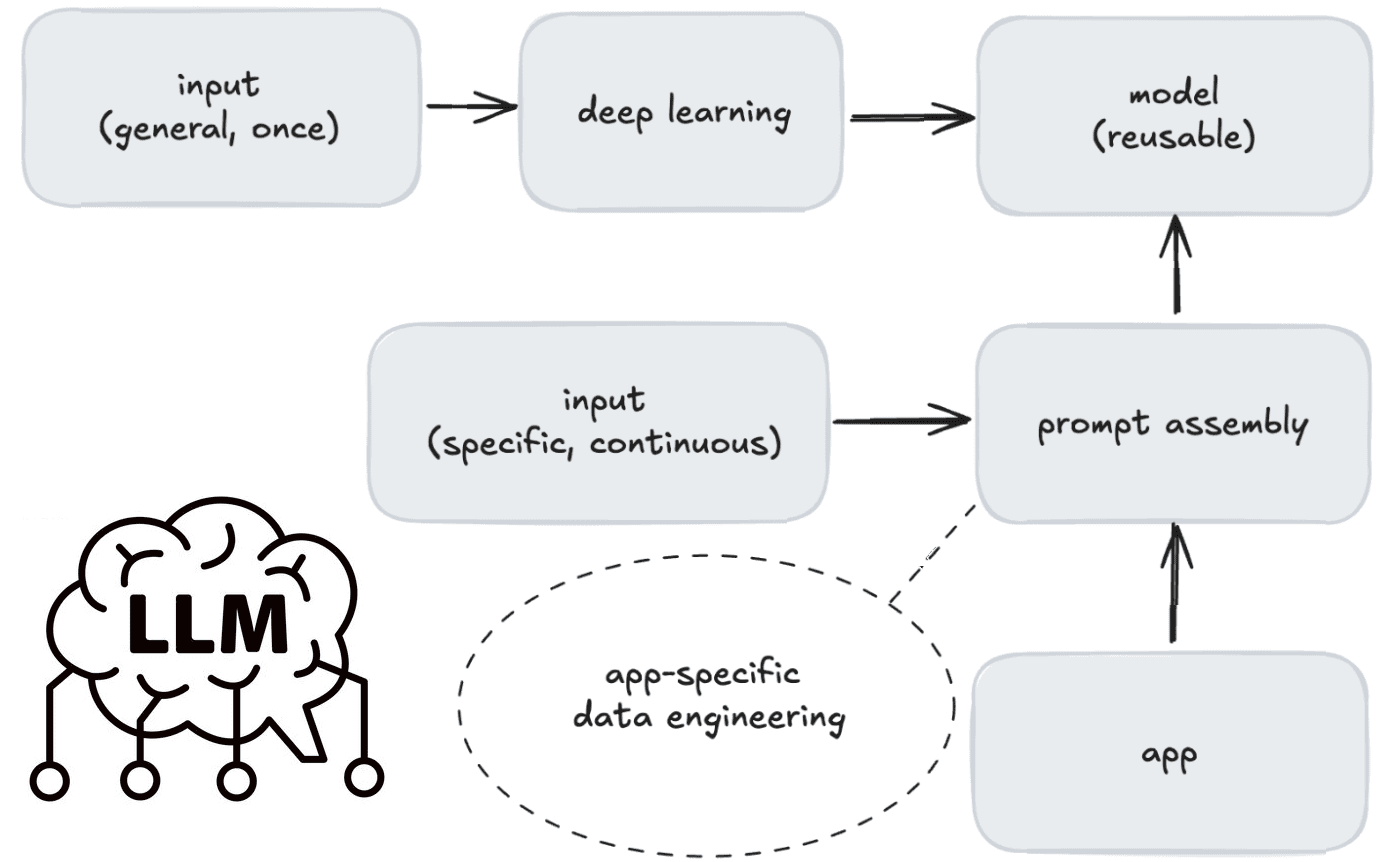
Поэтому не стоит рассматривать LLM как некую базу знаний – реактивный инструмент, который ждет входных данных и отвечает на конкретные запросы. Большинство практических вариантов использования генеративного ИИ основаны на контекстных данных в реальном времени. Платформы потоковой обработки дополняют эти модели, решая критические проблемы пакетной парадигмы: дополнение контекста в реальном времени, динамическое принятие решений и масштабируемые развязанные архитектуры. В конвейере потоковой обработки данных каждый компонент может работать независимо и может быть заменен на альтернативный. Это повышает гибкость всей системы и позволяет эффективно масштабировать приложения ИИ.
Кроме того, с учетом тренда на популярность агентского ИИ, где ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без прямого вмешательства человека, потребность в потоковой обработке данных увеличивается. Типичный агент ИИ можно рассматривать как автоматизированный процесс, который анализирует данные о среде и проактивно предпринимает действия для достижения некоторых определенных целей. При этом может потребоваться извлекать данные из нескольких источников, оперативно обрабатывать их, а также напрямую взаимодействовать с различными инструментами для выполнения детерминированных и стохастических рабочих процессов.
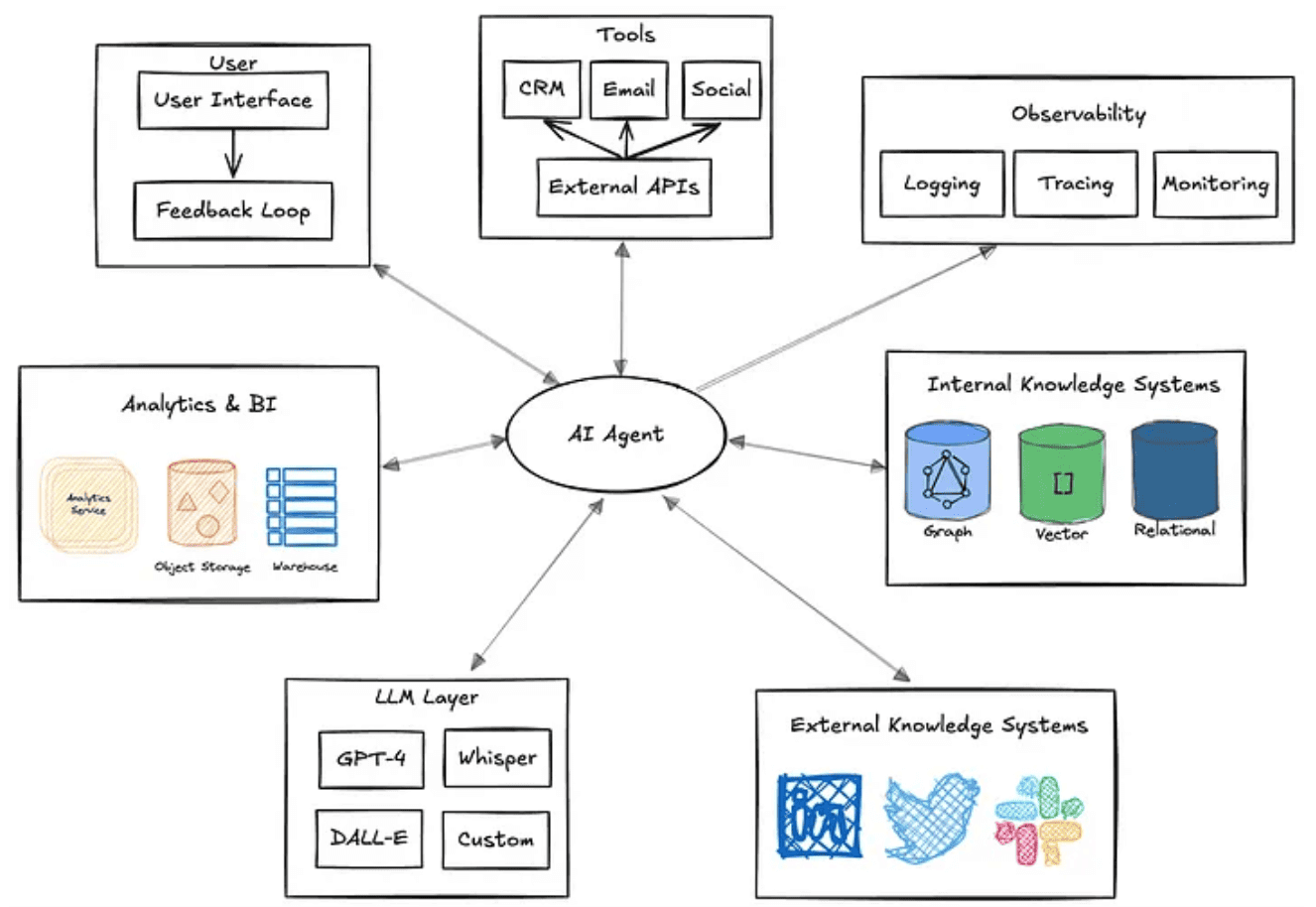
Архитектура системы агентского ИИ заключается в разделении рабочих процессов, где агенты, инфраструктура и другие компоненты гибко взаимодействуют без жестких зависимостей. Такая гибкая масштабируемая интеграция требует эффективных технологий обмена данными и надежной архитектуры, управляемой событиями (EDA, Event Driven Architecture). Организуя приложения вокруг событий, агенты могут работать в высокопроизводительной разделенной системе с малой задержкой, где каждая часть выполняет свою работу независимо.
Кроме того, EDA-архитектура, подобно микросервисному подходу, позволяет сократить срок вывода продукта на рынок (TTM, Time To Market) благодаря автономности каждой команды, принимающей участие в разработке. Обычно разные команды работают с разным техстеком: MLOps-специалисты и дата-инженеры управляют конвейером поисково-дополненной генерации (RAG, Retrieval Augmented Generation), специалисты по Data Science создают ML-модели, а разработчики приложений отвечают за интерфейс и бэкенд. Тесные зависимости между всеми этими командами замедляют доставку и затрудняют масштабирование. Однако, если развязать эти уровни, разработка приложений может просто потреблять результаты машинного обучения, используя универсальные интерфейсы и форматы данных. В EDA-архитектуре приложения транслируют события, а не полагаются на цепочку команд. Это разделяет компоненты, позволяя каждой команде работать независимо и передавать данные асинхронно. Таким образом, EDA-архитектура способствует бесшовной интеграции данных, масштабируемому росту и устойчивости, что делает ее мощной основой для современных ИИ-систем.
Технически EDA-архитектура реализуется с помощью платформ потоковой передачи событий, таких как Apache Kafka и мощных фреймворков распределенной обработки потоковых данных, например, Flink. Для подключения к внешним системам с целью обогащения контекста можно использовать специфические коннекторы на чтение и запись данных (source и sink). При этом обогащение ML-модели контекстом можно выполнять, используя стандартизированный MCP-протокол, о котором мы рассказываем здесь и здесь.
Таким образом, динамический характер генеративного ИИ обусловливает приемы и технологии ее проектирования и реализации. А поскольку такие ML-системы постоянно эволюционируют, важно отслеживать их производительность и качество работы. За это отвечают инструменты мониторинга и наблюдаемости, о чем мы поговорим далее.
Мониторинг, наблюдаемость и оценка качества генеративного ИИ
Мониторинг LLM включает отслеживание производительности ИИ-приложений. Наблюдаемость LLM позволяет осуществлять такой мониторинг, включая отслеживание следующих метрик:
- показатели использования ресурсов (процессоров, памяти, дискового ввода-вывода и пр.);
- показатели производительности, включая задержку, пропускную способность и т. д.;
- метрики оценки ML-модели, включая промпт-запросы, ответы, точность и ухудшение, использование токенов, полноту ответа, релевантность, галлюцинации, соответствие, семантическое сходство и пр.
Обычно LLM-приложения недолго хранят историю запросов и ответов. Ка правило, подобные чаты хранятся в документо-ориентированных хранилищах. Мониторинг пар запрос-ответ помогает выявлять повторяющиеся проблемы пользователей или общие запросы, которые пригодятся для последующего дообучения модели. Если кодировать тексты истории во встраиваивания (embedding) и хранить в векторной базе данных, ИИ-приложение может извлекать оттуда контекстно схожие ответы, повышая релевантность выходных данных. Так можно повысить уровень персонализации и погружения в контекст без долгого хранения необработанных текстовых данных. Это также улучшает безопасность ИИ-приложения, ведь, чем меньше пользовательских данных хранится, тем меньше риск их потерять. Кроме того, использование векторных баз данных вместе с LLM обеспечивает долговременную память ML-модели. Наконец, векторные базы данных могут для оценки и измерения точности ответа, позволяя сравнивать ответы, сгенерированные LLM с ответами, одобренными людьми-экспертами. Превышение этой метрики заданного порога может указывать на деградацию ML-модели и необходимость ее переобучения.
Мониторинг использования токенов (единиц текста, которые обрабатывает LLM) помогает контролировать расходы, выявляя области интенсивного использования и потенциальной оптимизации, например, сокращая длину ответов или ограничивая ненужные запросы. Кроме того, использование токенов напрямую влияет на время ответа и задержку. Отслеживая токены с течением времени, можно определить, какие запросы или ответы излишне длинные и что именно влияет на пользовательский опыт. Также мониторинг позволяет выявить неэффективные промпты, которые приводят к чрезмерному или избыточному выводу. Использование токенов также отражает то, как пользователи взаимодействуют с моделью. Отслеживание токенов в пользовательских сеансах позволяет выявить закономерности в их поведении.
Количественно оценить производительность ML-модели можно, используя следующие метрики:
- релевантность (relevance) – насколько хорошо ответ модели соответствует вводимому промпту и контексту. Высокая релевантность указывает на то, что модель понимает и соответствующим образом отвечает на запросы пользователя.
- непредвзятость (fairness), когда ответы модели объективны и представляют различные точки зрения без маргинализации или предпочтения определенных групп. Обеспечение непредвзятости включает в себя проверку и корректировку обучающих данных, архитектуры модели и генерации ответов.
- галлюцинации (hallucinations), когда LLM генерирует информацию, которая звучит правдоподобно, но фактически неверна или вымышлена. Это частая проблема LLM, которые могут дополнять информацию, основываясь на закономерностях в обучающих данных, даже если это не соответствует действительности.
- перплексия (perplexity) – безразмерная величина, мера того, насколько хорошо распределение вероятностей предсказывает выборку. В LLM эта метрика показывает, насколько хорошо LLM предсказывает последовательность слов или токенов. Более низкое значение обычно указывает, что модель хорошо предсказывает следующее слово в последовательности. Однако, это не отражает точность или правдивость информации.
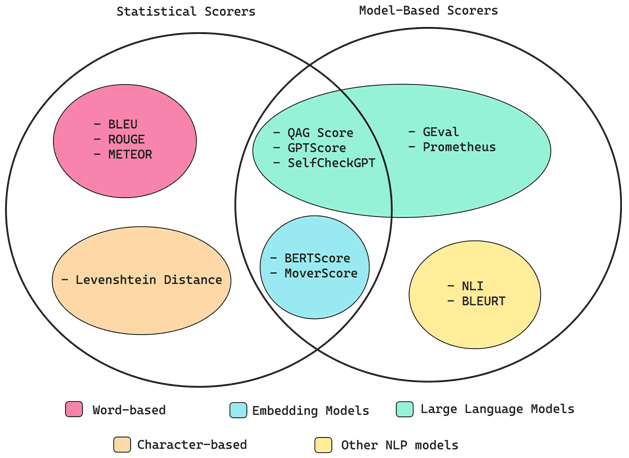
Для мониторинга и оценки качества LLM-модели можно использовать классические методы статистики и специализированные ИИ-фреймворки. Или комбинацию обоих подходов. При этом реализация системы мониторинга и оценки качества LLM-модели также требует потоковой обработки данных и EDA-архитектуры. Как это сделать, рассмотрим в другой раз.
Освойте MLOps-инструменты на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Разработка и внедрение ML-решений
- Практическое применение Big Data аналитики для решения бизнес-задач
Источники
- https://www.confluent.io/blog/stop-treating-your-llm-like-a-database/
- https://www.influxdata.com/blog/llm-monitoring-observability-influxdb/
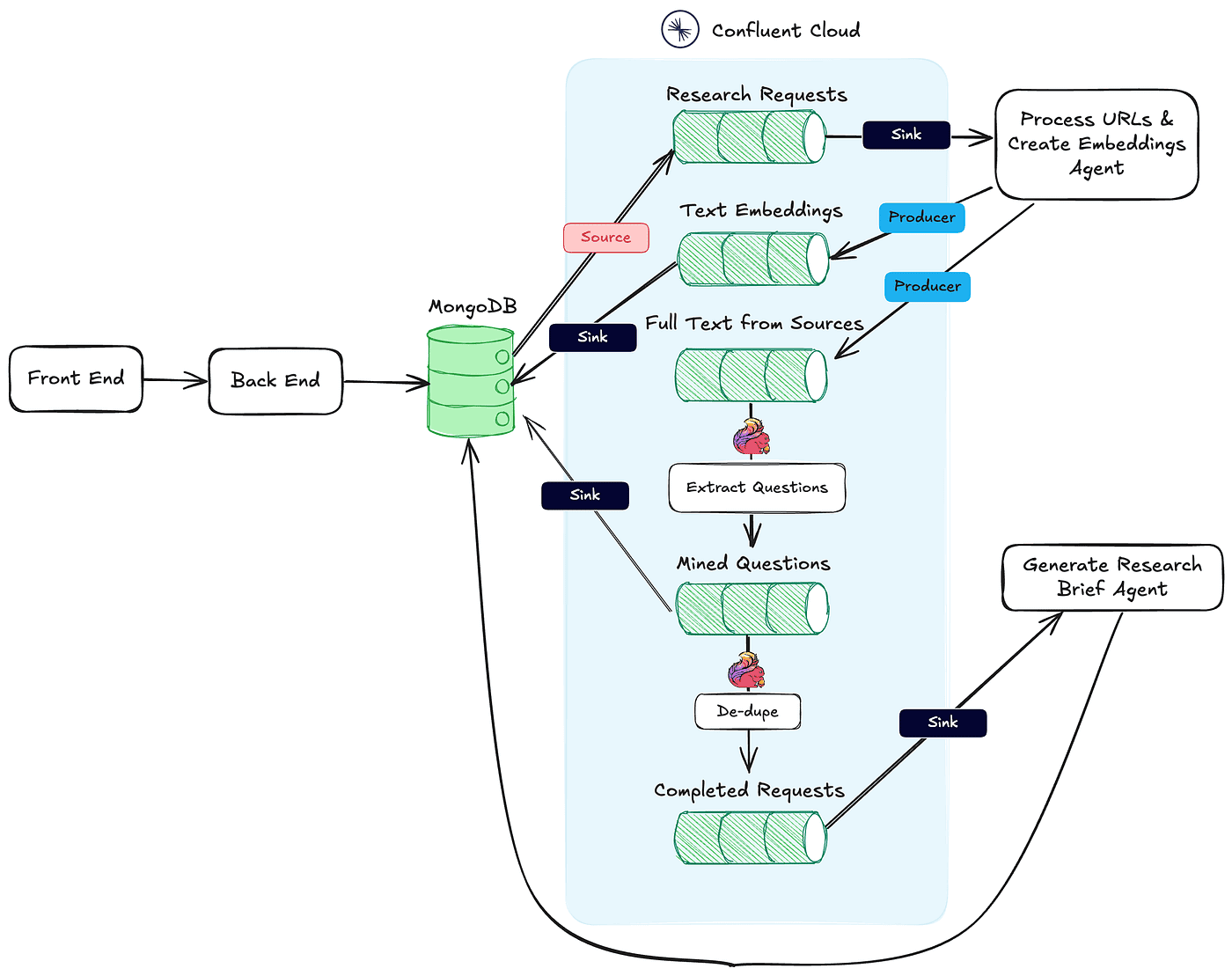
- https://www.confluent.io/blog/event-driven-ai-building-a-research-assistant-with-kafka-and-flink/
- https://www.confident-ai.com/blog/llm-evaluation-metrics-everything-you-need-for-llm-evaluation

