 1328
1328 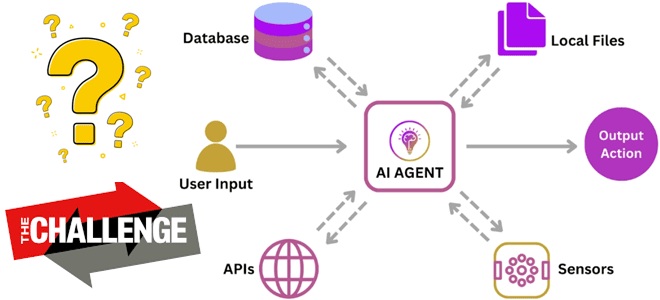
Содержание
Чем хорош агентский ИИ, какие риски и проблемы с ним связаны, и как их избежать: технические и организационные меры внедрения ML-систем в реальный бизнес.
Что сдерживает внедрение агентского ИИ
Мы уже писали об агентском ИИ, когда ML-система не просто реагирует на запросы пользователя, а работает автономно, интеллектуально решая задачи без прямого вмешательства человека. Типичный агент ИИ можно рассматривать как автоматизированный процесс, который анализирует данные о среде и проактивно предпринимает действия для достижения некоторых определенных целей, извлекая данные из нескольких источников и взаимодействуя со специализированными инструментами их обработки.
Популярность агентского ИИ растет с распространением генеративных ML-моделей: по прогнозам Gartner к 2028 году не менее 15% повседневных рабочих решений будут приниматься агентским ИИ. Однако, как и любая новая технология, агентский ИИ имеет ряд проблем, которые сдерживают его повсеместное внедрение. Одной из них является специфическая логика модели и реализация критического мышления. Один агент ИИ действует как планировщик и организует действия нескольких агентов. Модель обеспечивает критическое мышление на основе обратной связи по результатам работы планировщика и различных агентов, которые выполняют инструкции. Точность работы модели прямо пропорциональна получаемой обратной связи. Поэтому модель критического мыслителя должна быть обучена на данных, которые максимально приближены к реальности. Для обучения модели придется предоставить огромное количество информации о целях, планах, действиях и результатах, а также множество отзывов, т.е. обратной связи. Это потребует сотни тысяч итераций, прежде чем у ML-модели будет достаточно данных для критического мышления.
Другая проблема связана с надежностью и предсказуемостью: программный ИИ-агент имеет определенную степень автономии, поэтому в выходных данных может возникнуть случайность, похожая на галлюцинации LLM. Впрочем, сегодня генеративные нейросети стали показывать результаты с гораздо меньшим количество галлюцинаций благодаря тонкой настройке и обучению с помощью экспертов-людей. Необходимо приложить аналогичные усилия для улучшения качества результатов агентского ИИ, чтобы сделать их более предсказуемыми и надежными.
Следующей проблемой, сдерживающей развитие и внедрение агентского ИИ, является необходимость обеспечения конфиденциальности и безопасности данных. В частности, когда пользователь взаимодействует с LLM, каждый бит информации, предоставленной модели, встраивается в нее, включая ключи, пароли и другую конфиденциальную информацию. Нельзя вернуться назад и попросить ML-модель забыть эти секретные данные, которые могут утечь вовне из-за атак или вызовов других пользователей.
Чтобы решить эту проблему, необходимо максимально контейнеризовать данные и ML-системы, гарантируя их использование только в пределах внутреннего безопасного контура. Также крайне важно анонимизировать данные, скрыв секретную и личную информацию из промпта перед его отправкой в модель машинного обучения.
Таким образом, можно выделить следующие виды систем агентского ИИ с учетом последствий их применения в бизнесе с точки зрения информационной безопасности:
- внешний агентский ИИ — пользовательский интерфейс с внешней моделью ИИ, над которым нет никакого контроля, есть только возможность управлять данными и промптами, которые отправляются на вход ML-системе;
- внутренний корпоративный ИИ, созданный для внутреннего использования. Хотя риск работы с такой системой гораздо меньше, чем в предыдущем случае, все равно риск раскрытия конфиденциальной информации остается. Поэтому компании, которые решил создать свой собственный GPT-подобный агент ИИ, должны встроить в него функции анонимизации секретных данных.
- агентский ИИ для клиентов, который создан для обслуживания клиентов бизнеса. Такая система тоже должна иметь функции анонимизации секретных данных, а также очень точные алгоритмы сегментации клиентов, чтобы предлагать персональный сервис, избегая раскрытия конфиденциальной информации.
Кроме обеспечения безопасности, необходимо обеспечить высокое качество данных и релевантность выдаваемых результатов в соответствии с контекстом пользовательского запроса. Это довольно серьезная проблема, поскольку генеративные модели ИИ обучены на старых данных, которые сегодня могут быть уже не актуальны. Это особенно при работе с кодом, когда нейросеть генерирует ответы, используя устаревшие версии библиотек. Поэтому системы агентсткого ИИ должны получать доступ к актуальным данным, в т.ч. хранящихся во внешних доверенных источниках. С этим может помочь платформа потоковой передачи данных. Например, можно использовать Apache Kafka и Kafka Connect для событийной интеграции с внешними источниками и Apache Flink для потоковой обработки полученной и сгенерированной информации.
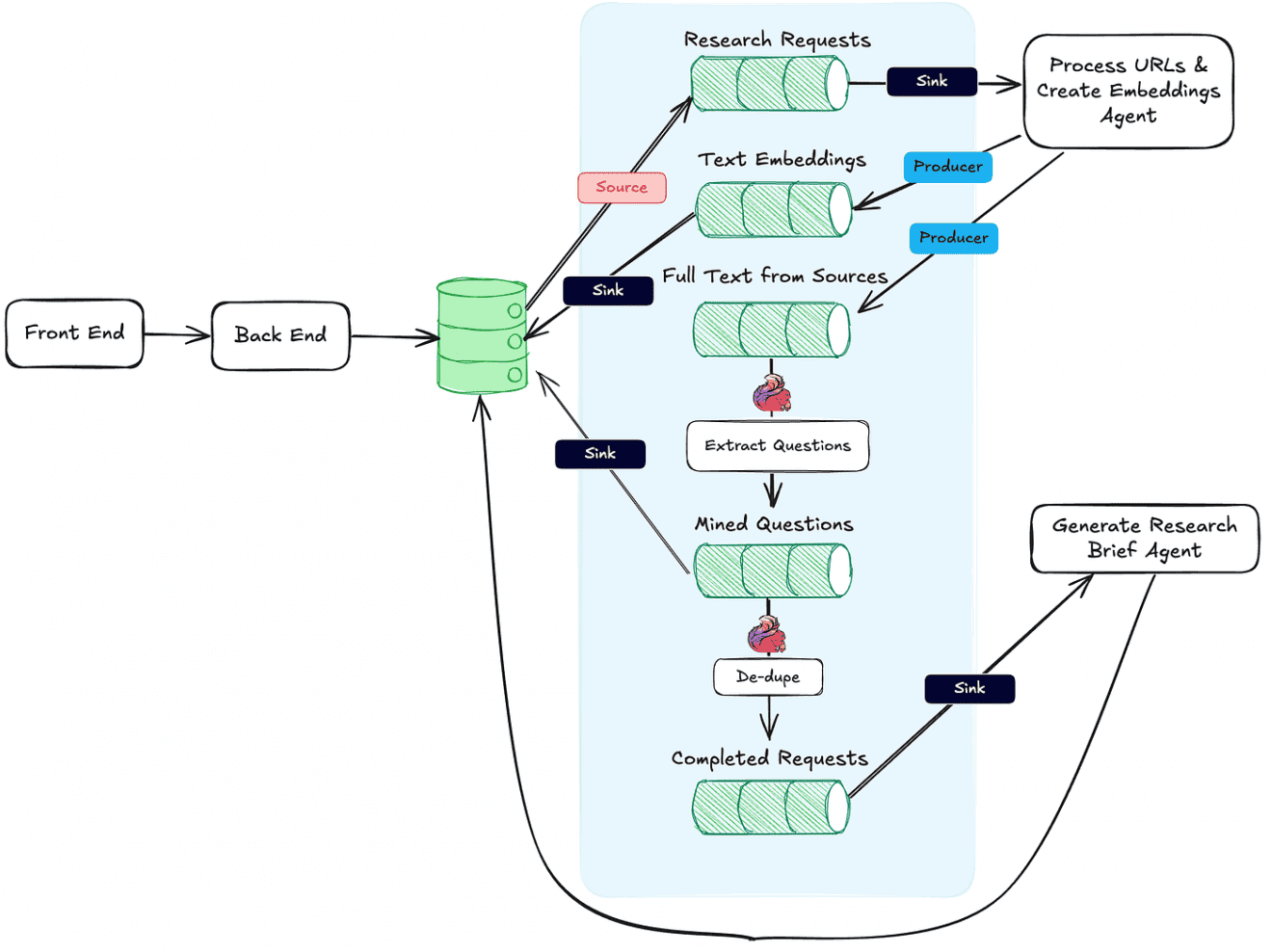
О том, как построить ML-систему агентского ИИ на основе ClickHouse, читайте в нашей новой статье.
Узнайте больше про машинное обучение и ИИ на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Разработка и внедрение ML-решений
- Практическое применение Big Data аналитики для решения бизнес-задач
Источники

