 1152
1152 
Что такое Apache Wayang, чем он похож на Beam и в чем разница с Trino: архитектура и принципы работы еще одного распределенного фреймворка интеграции данных.
Что такое Apache Wayang и чем это отличается от Trino
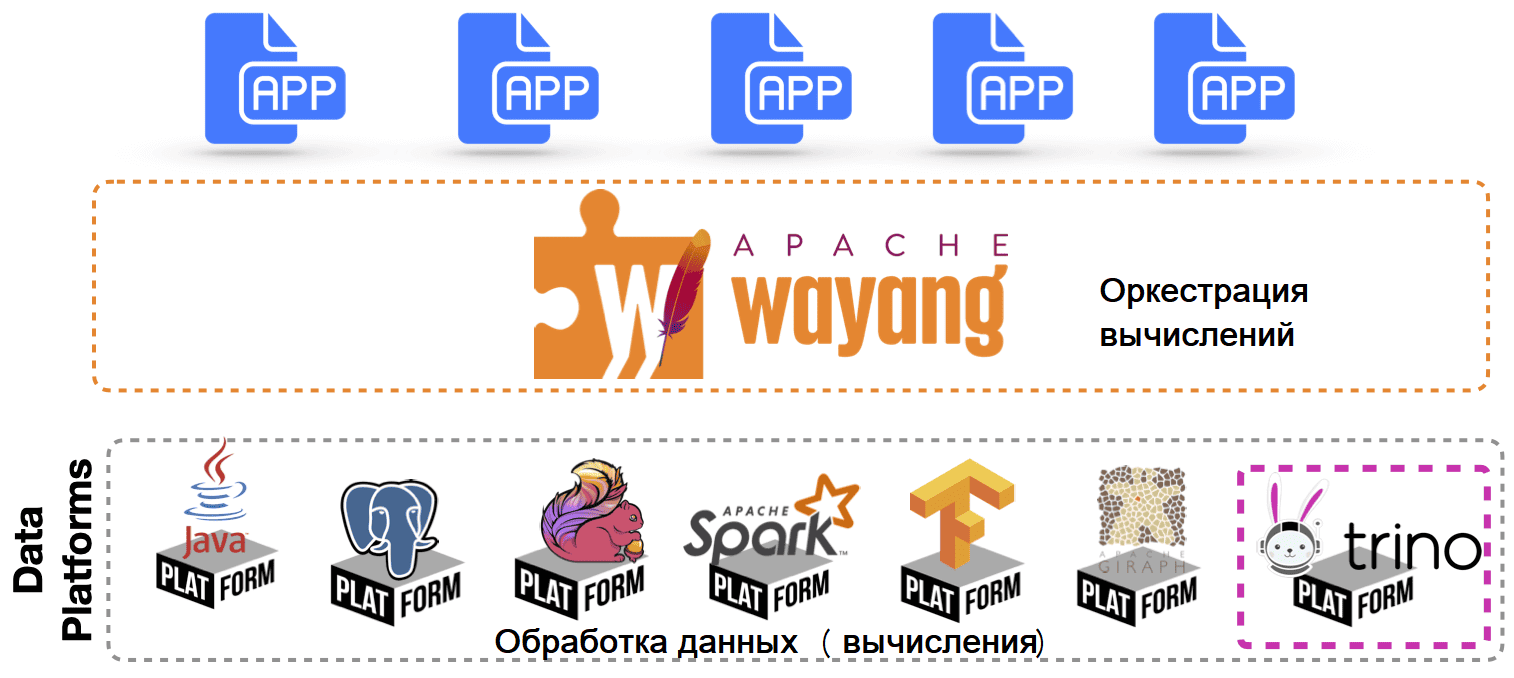
Trino – это мощный, но далеко не единственный инструмент распределенного выполнения аналитических запросов, способный обрабатывать данных из различных источников. Подобные возможности есть еще у одного проекта с открытым исходным кодом — Apache Wayang. Это промежуточное ПО для интеграции разных платформ данных тоже поддерживает SQL. Однако, в отличии от Trino, Wayang не просто выполняет распределенные SQL-запросы, используя возможности базовых платформ данных для интеграции данных, а абстрагирует различные вычислительные движки, предоставляя единый интерфейс для разработки и выполнения задач. Trino же является самостоятельным SQL-движком, который напрямую взаимодействует с источниками данных через коннекторы.
По архитектуре и принципам работы Wayang больше похож на Apache Beam, который предоставляет единую модель программирования для потоковой и пакетной обработки данных, позволяя писать один и тот же код для разных вычислительных движков (Spark,Flink и пр.). Примеры этого мы разбирали здесь и здесь. Wayang тоже поддерживает несколько движков выполнения, включая Apache Spark и Flink, и может не только выбирать движок перед запуском, но и адаптироваться в реальном времени, перенаправляя части рабочих процессов на наиболее подходящие платформы для повышения производительности и эффективности. При этом фактическая обработка запросов не выполняется внутри самого Wayang.
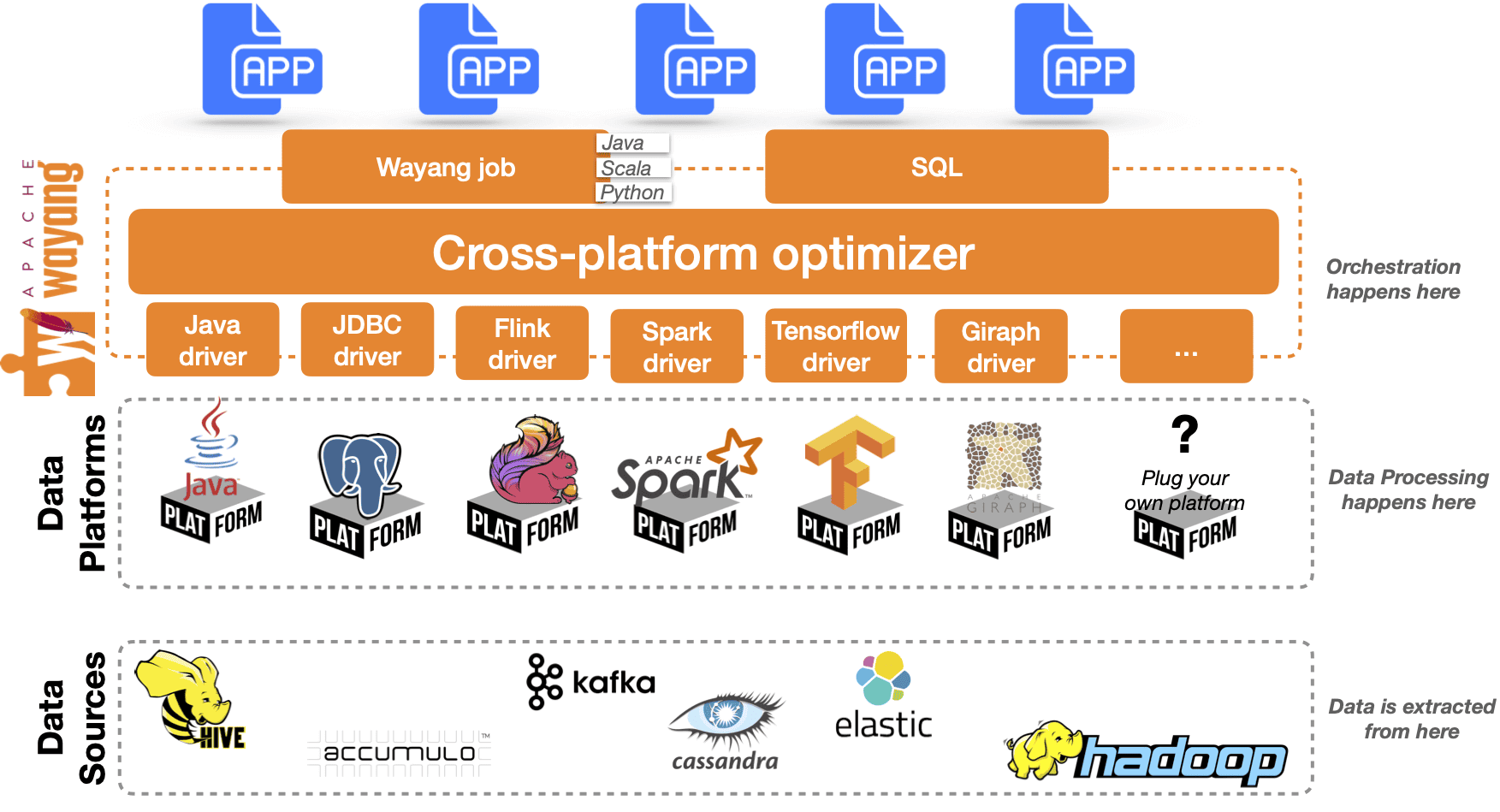
Трехслойная архитектура Apache Wayang реализует стратегическую абстракцию между пользовательскими приложениями и базовыми платформами обработки данных. Это обеспечивает бесшовную интеграцию и оптимизацию. Прикладной уровень инкапсулирует логику, специфичную для приложения, а ядро действует как посредник, транслируя логику приложения в стандартизированное промежуточное представление – WayangPlan. Это стандартизированное представление передается на уровень платформы, где оно оптимизируется для выполнения на различных платформах данных, включая любые базы данных, Spark, Flink и системы машинного обучения. Благодаря этому план выполнения ExecutionPlan использует возможности платформы данных, повышая производительность и эффективность вычислительного конвейера.
Слоистая архитектура Apache Wayang разделяет физические уровни планирования и выполнения, позволяя абстрагироваться от особенностей конкретных платформ обработки:
- на нижних уровнях программного стека находятся различные носители данных и поддерживаемые платформы обработки данных;
- ядро Wayang включает оптимизатор, исполнитель, монитор и драйверы для конкретных платформ.
- на уровне API Wayang уже поддерживает Java и Scala, а также разрабатывается API Python. Кроме этого, пользователи могут напрямую вводить SQL-запросы через библиотеку SQL, которая преобразует их в план Wayang. Wayang также поставляется с библиотекой ML для задач машинного обучения. Чтобы обеспечить поддержку большего количества языков программирования, в Wayang внедряется библиотека Polyglot.
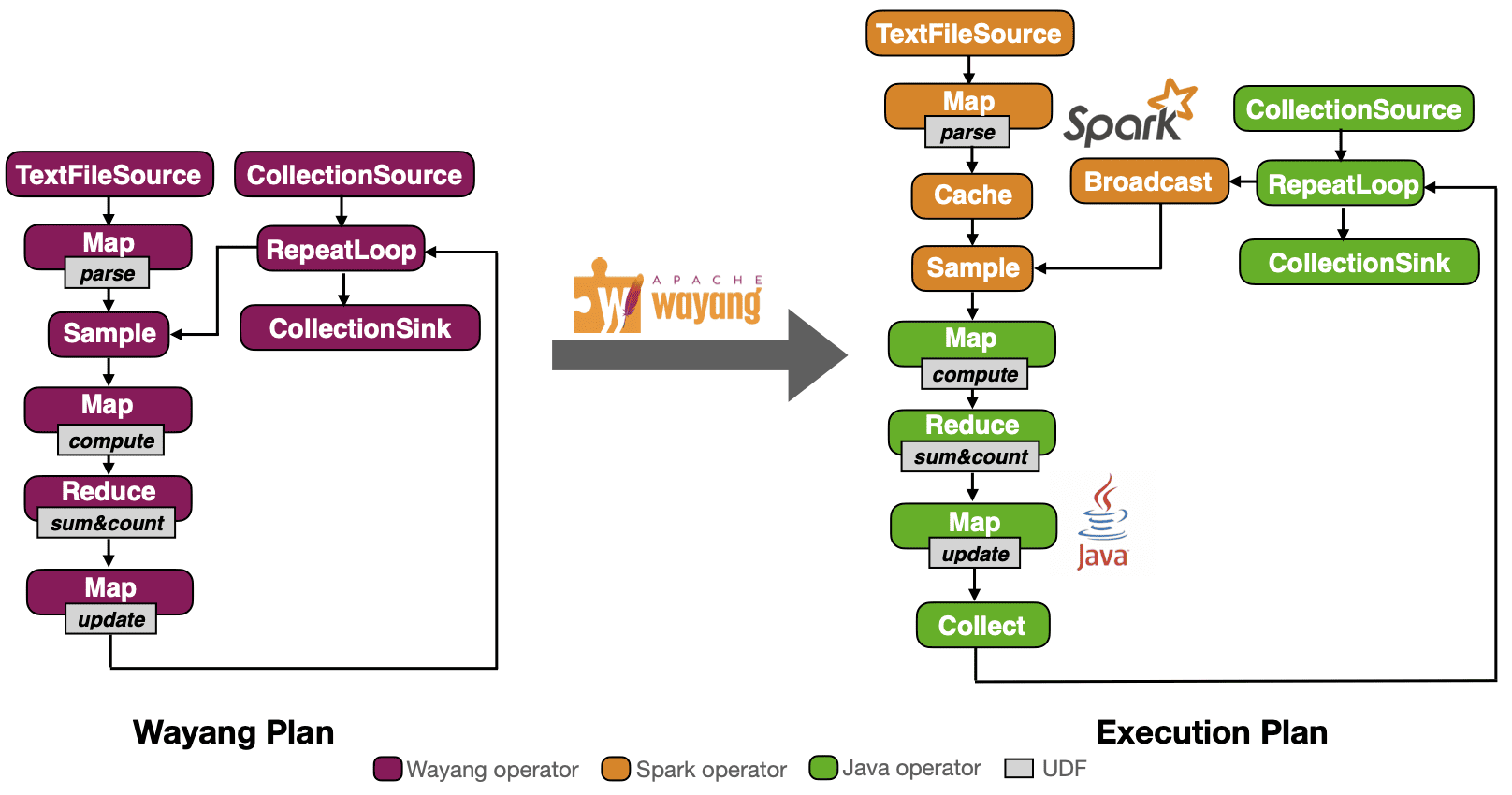
Например, алгоритм стохастического градиентного спуска, который используется в большинстве задач глубокого обучения, в плане Wayang представляется как набор операторов, выполняемых на разных вычислительных движках, например, на Spark, и как процессы Java.
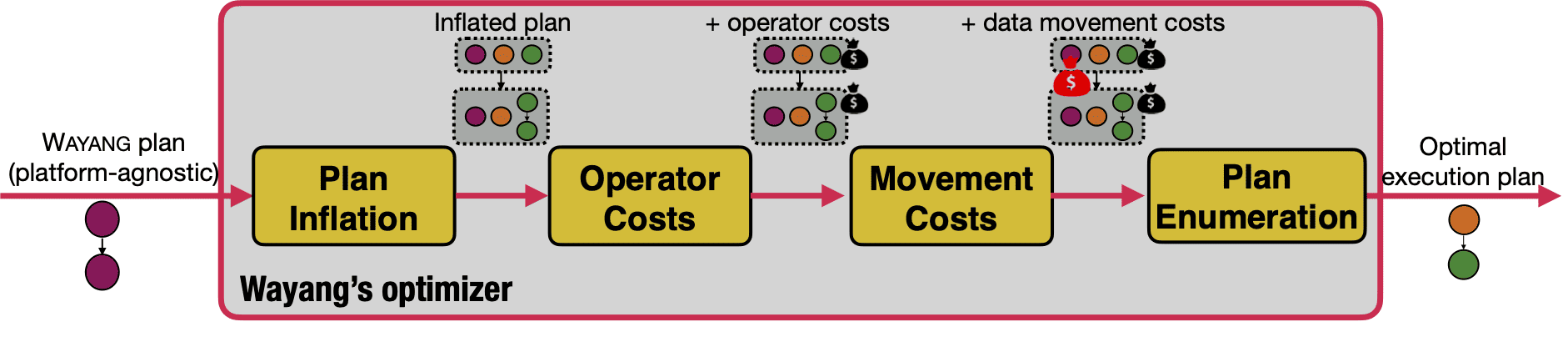
Кроссплатформенный оптимизатор запросов Wayang является основным компонентом ядра. Он получает в качестве входных данных план Wayang и выводит план выполнения, специфичный для платформы для сокращения общей стоимости. Метрика стоимости может быть любой, от времени выполнения до денежных затрат или потребления энергии. Для этого оптимизатор сначала для каждого узла, соответствующего оператору Wayang, добавляет все операторы выполнения, специфичные для платформы. После этого оптимизатор добавляет затраты на перемещение промежуточных данных с одной платформы на другую. По умолчанию Wayang использует линейные формулы стоимости для оценки этих затрат, но можно подключить свой собственный оптимизатор, например, основанный на ML-модели. На последнем этапе оптимизации запроса алгоритм перечисления рассматривает доступные варианты для вывода оптимального плана выполнения относительно определенной стоимости.
Разработчик может управлять оптимизатором, указывая в своем коде, где надо выполнить оператор, с помощью вызова withTargetPlatform(plat). Затем оптимизатор учитывает решения пользователя и выводит план выполнения, перемещаясь по сокращенному пространству поиска во время перечисления плана.
Кроссплатформенный оптимизатор Apache Wayang не только выбирает наиболее подходящий механизм обработки для каждой задачи, но и позволяет выполнять одну задачу на нескольких платформах. Это достигается за счет расширяемого набора графовых преобразований, применяемых к плану Wayang, который определяет альтернативные варианты выполнения, чтобы обеспечить лучшую производительность. Затем эти альтернативные планы оцениваются с использованием платформенно-специфичных моделей затрат, которые определены пользователем или извлечены из исторических данных. Эти модели затрат параметризуются на основе базовой аппаратной конфигурации, такой как количество вычислительных узлов для распределенных операций.
Компонент ML4all как часть Wayang избавляет пользователей от сложностей выбора алгоритма и низкоуровневых деталей реализации приложений машинного обучения, позволяя сосредоточиться на бизнес-логике. В частности, ML4all использует CBO-оптимизатор (Cost Based Optimizer) для динамического определения оптимального алгоритма градиентного спуска для каждого сценария. Это очень повышает производительность, позволяя обрабатывать большие наборы данных.
Благодаря поддержке пользовательских функций (UDF, User Defined Function), оптимизатор Wayang получает из платформ данных семантическую информацию об их функциях, подсказки по оптимизации, например, количество итераций, ограничения и альтернативные планы выполнения. Это обеспечивает оптимальную производительность. Apache Wayang включает широкий набор операторов для определения задач.
Таким образом, Wayang отлично подходит для разработчиков, когда нужна гибкость в выборе вычислительных платформ и возможность переносимости кода. В свою очередь, Trino идеален для аналитиков и специалистов по Data Science, которым нужно выполнять быстрые и эффективные SQL-запросы к большим и разнообразным наборам данных. Подробнее об этом мы говорим в новой статье про сравнение Trino и StarRocks.
Подобно Beam, Wayang обеспечивает гибкость благодаря поддержке различных движков и сред выполнения. В Trino интеграция с различными источниками данных обеспечивается его архитектурой на основе плагинов, частным случаем которых являются коннекторы. Поэтому Trino можно подключить к Wayang как платформу, чтобы объединять и анализировать данные из разных хранилищ с помощью SQL-запросов. Wayang может динамически управлять вычислительными ресурсами, настраивая их для выполнения запросов Trino. Подробнее о месте Trino в архитектуре данных мы писали здесь.
Освоить работу с Trino вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

