 1518
1518 
Содержание
Apache HBase – это нереляционная, распределенная база данных с открытым исходным кодом, написанная на языке Java по аналогии BigTable от Google. Изначально эта СУБД класса NoSQL создавалась компанией Powerset в 2007 году для обработки больших объёмов данных в рамках поисковой системы на естественном языке. Проектом верхнего уровня Apache Software Foundation HBase стала в 2010 году. СУБД относится к категории «семейство столбцов» (wide-column store) и представляет собой колоночно-ориентированное, мультиверсионное хранилище типа «ключ-значение» (key-value). Она работает поверх распределенной файловой системы HDFS и обеспечивает возможности BigTable для Hadoop, реализуя отказоустойчивый способ хранения больших объёмов разреженных данных [1].
Как хранится информация в NoSQL СУБД: модель данных
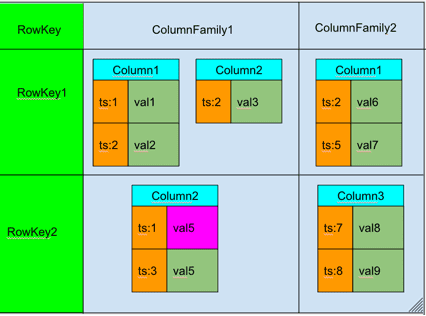
Модель данных HBase отличается от классических реляционных СУБД, реализуясь по типу ключ-значение – <table, RowKey, Column Family, Column, timestamp> -> Value [2]:
- данные организованы в таблицы, проиндексированные первичным ключом (RowKey);
- для каждого первичного ключа может храниться неограниченный набор атрибутов (колонок);
- Колонки организованны в группы колонок (Column Family). Обычно в одну группу объединяют колонки с одинаковым шаблоном использования и хранения. Список и названия групп колонок фиксирован и имеет четкую схему. На уровне группы колонок задаются такие параметры как time to live (TTL) и максимальное количество хранимых версий.
- Для каждого атрибута может храниться несколько различных версий. Разные версии имеют разный штамп времени (timestamp, ts).
- Записи физически хранятся в порядке, отсортированном по первичному ключу. При этом информация из разных колонок хранится отдельно, благодаря чему можно считывать данные только из нужного семейства колонок, таким образом, ускоряя операцию чтения.
- Атрибуты, принадлежащие одной группе колонок и соответствующие одному ключу, физически хранятся как отсортированный список. Любой атрибут может отсутствовать или присутствовать для каждого ключа. Отсутствие атрибута не влечет никаких накладных расходов на хранение пустых значений.
- Если разница между штампом времени (timestamp) для определенной версии и текущим временем больше TTL, такая запись помечается к удалению. Аналогично, если количество версий для определённого атрибута превысило максимальное количество версий.
Как работает Apache HBase с массивами Big Data: принцип действия
HBase обеспечивает случайный доступ в реальном времени к данным в Hadoop в сочетании с удобством пакетной обработки. Благодаря этому можно работать с очень большими таблицами, что позволяет эффективно хранить многостраничные или разреженные данных [1].
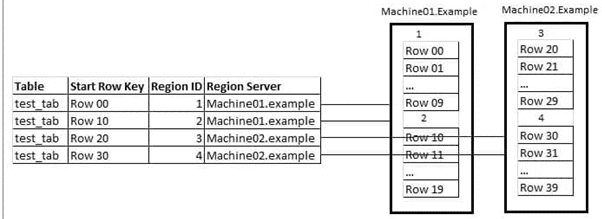
Поскольку HBase является распределенной СУБД, она может работать на десятках и сотнях физических серверов, обеспечивая бесперебойную работу даже при выходе из строя некоторых узлов. Распределение данных по разным физическим машинам кластера обеспечивается механизмом регионирования – автоматической горизонтальной группировки табличных строк [3].
Регион — это диапазон записей, соответствующих определенному диапазону подряд идущих первичных ключей. Каждый регион содержит следующие параметры [2]:
- Persistent Storage— основное хранилище данных в Hbase. Данные физически хранятся на HDFS, в специальном формате HFile, отсортированные по значению первичного ключа (RowKey). Одной паре (регион, column family) соответствует как минимум один HFIle.
- MemStore— буфер на запись, специально выделенная область памяти для накопления данных перед записью, поскольку обновлять каждую запись в отсортированном HFile довольно дорого. Как только MemStore наполнится до некоторого критического значения, создается очередной HFile, куда будут записаны новые данные.
- BlockCache— кэш на чтение, позволяющий существенно экономить время на часто читаемых данных.
- Write Ahead Log (WAL) – специальный файл для логгирования всех операций с данными, чтобы их можно было восстановить в случае сбоя.
Изначально таблица состоит из одного региона, который разбивается на новые по мере роста (после превышения конкретно заданного порогового размера). Когда таблица становится слишком большой для одного сервера, она обслуживается кластером, на каждом узле которого размещается подмножество регионов таблицы. Таким образом, регионирование обеспечивает распределение нагрузки на таблицу. Совокупность отсортированных регионов, доступных по сети, образует общее содержимое распределенной таблицы [3].
Поскольку данные по одному региону могут храниться в нескольких HFile, для ускорения работы HBase периодически объединяет их, выполняя одну из 2-х операций под названием compaction [2]:
- Minor Compaction, который запускается автоматически и выполняется в фоновом режиме. Имеет низкий приоритет по сравнению с другими операциями.
- Major Compaction, запускаемый вручную или в случае наступления определенных условий (триггеров), например, срабатывание по таймеру. Имеет высокий приоритет и может существенно замедлить работу кластера. Эту операцию рекомендуется выполнять при невысокой нагрузке на кластер. Во время выполнения Major Compaction также происходит физическое удаление данных, ранее помеченных соответствующей меткой tombstone.
Помимо Compaction-операций, HBase позволяет также работать с данными, считывая и записывая новую информацию. Однако, в отличие от реляционных СУБД, HBase поддерживает только 4 основные действия по обработки данных, которые отличаются от классических SQL-запросов [1]:
- Put – добавить новую или обновить существующую запись. Временной штамп (timestamp) этой записи может быть задан вручную или установлен автоматически как текущее время.
Для добавления новой записи используется инструкция
put ’<table name>’,’row1’,’<colfamily:colname>’,’<value>’
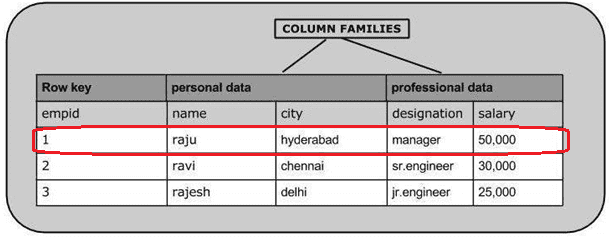
Например, чтобы создать 1-ю запись таблицы, используется следующий код [4]:
put ’emp’,’1′,’personal data:name’,’raju’
put ’emp’,’1′,’personal data:city’,’hyderabad’
put ’emp’,’1′,’professional data:designation’,’manager’
put ’emp’,’1′,’professional data:salary’,’50000′
Для изменения существующей записи используется инструкция
put ‘table name’,’row ’,’Column family:column name’,’new value’
К примеру, так можно изменить значение ‘raju’ в столбце city на ‘Delhi’.
put ’emp’,’row1′,’personal:city’,’Delhi’
- Get – получить данные по определенному первичному ключу (RowKey). Можно указать Column Family, откуда будет считана информация и количество версий, которые требуется прочитать. Инструкция выглядит так: get ’<table name>’,’row1’.
В ответ на эту инструкцию таблица из рассмотренного выше примера отобразится в shell-интерфейсе HBase следующим образом [5]:
get ’emp’, ‘1’
COLUMN CELL
personal : city timestamp = 1417521848375, value = hyderabad
personal : name timestamp = 1417521785385, value = raju
professional: designation timestamp = 1417521885277, value = manager
professional: salary timestamp = 1417521903862, value = 500004 row(s) in 0.0270 seconds
- Scan – поочередное чтение записей, начиная с указанной. Можно указать запись, до которой следует читать или количество записей, которые необходимо считать. Также в параметрах операции отмечается Column Family, откуда будет производиться чтение и максимальное количество версий для каждой записи.
Синтаксис команды: scan ‘<table name>’. Shell-оболочка HBase ответит на эту инструкцию следующим образом [6]:
hbase(main):010:0> scan ’emp’
ROW COLUMN + CELL
1 column = personal data:city, timestamp = 1417521848375, value = hyderabad
1 column = personal data:name, timestamp = 1417521785385, value = raju
1 column = professional data:designation, timestamp = 1417585277,value = manager
1 column = professional data:salary, timestamp = 1417521903862, value = 50000
1 row(s) in 0.0370 seconds
- Delete – пометить определенную версию к удалению. Физического удаления при этом не произойдет, оно будет отложено до следующего Major Compaction, о котором мы рассказали выше. Синтаксис: delete ‘<table name>’, ‘<row>’, ‘<column name >’, ‘<time stamp>’
Вот как это будет выглядеть в Shell-оболочке HBase [7]:
hbase(main):006:0> delete ’emp’, ‘1’, ‘personal data:city’,1417521848375
0 row(s) in 0.0060 seconds
Кластерная архитектура
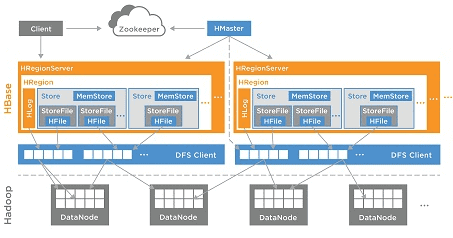
Для распределенной работы с данными в HBase имеются следующие основные архитектурные компоненты [2]:
- Region Server, который обслуживает один или несколько регионов. Region Server включает memstore для кэширования часто используемых строк в памяти.
- Master Server – главный узел в кластере, управляющий распределением регионов по региональным серверам, включая ведение их реестра, управление запусками регулярных задач и других организационных действий.
Вычислительная модель MapReduce может использоваться для загрузки большого объема данных, при этом на этапе Reduce выполняется загрузка данных в таблицу – локальная запись данных на соответствующем Region Server [1].
За координацию работ между сервисами HBase отвечает служба Apache ZooKeeper, предназначенная для управления конфигурациями и синхронизации сервисов. Серверы ZooKeeper и HMaster предоставляют клиентам информацию о топологии кластера. Клиенты подключаются к ним и загружают список регионов, содержащихся в региональных серверах, и диапазонах ключей, размещенных в регионах.
Высокая доступность данных и отказоустойчивость HBase обеспечиваются благодаря следующем особенностям этой распределенной СУБД класса NoSQL [1]:
- развертывание на нескольких экземплярах HMaster и ZooKeeper;
- распределение данных по многим узлам гарантирует, что сбой одного из них не приведет к потере доступности данных;
- формат HFile, хранящий данные непосредственно в HDFS, можно читать и записывать с помощью многих инструментов Apache стека Big Data (например, Hive, Pig, MapReduce, Tez), что позволяет практически в режиме реального времени анализировать данные, не копируя их в другие хранилища.
О достоинствах и недостатках Apache HBase, а также примерах практического применения этой СУБД класса NoSQL в реальных Big Data проектах мы расскажем в отдельной статье.
Источники
- https://ru.bmstu.wiki/Apache_HBase
- https://habr.com/ru/company/dca/blog/280700/
- https://ru.wikipedia.org/wiki/HBase
- https://www.tutorialspoint.com/hbase/hbase_create_data.htm
- https://www.tutorialspoint.com/hbase/hbase_read_data.htm
- https://www.tutorialspoint.com/hbase/hbase_scan.htm
- https://www.tutorialspoint.com/hbase/hbase_delete_data.htm