 630
630 
Содержание
Говоря про перспективы развития экосистемы Apache Hadoop с учетом современного тренда на SaaS-подход к работе с большими данными (Big Data), сегодня мы рассмотрим, как работает коннектор облачного хранилища Google для этого фреймворка. Читайте далее, чем HCFS отличается от HDFS и каковы преимущества практического использования Google Cloud Storage Connector for Hadoop.
Что такое Google Cloud Storage и зачем ему коннектор к Apache Hadoop
Напомним, Google Cloud Storage — это единое хранилище объектов, которое предоставляет доступ к данным через унифицированный API, являясь облачным управляемым решением. Оно поддерживает как высокопроизводительные вычисления, так и архивный вариант использования [1]. Существует несколько способов получить доступ к данным, хранящимся в Google Cloud Storage [2]:
- через приложения Spark, PySpark или Hadoop с использованием префикса gs: //;
- в рамках shell-оболочки Hadoop с помощью команды hadoop fs -ls gs: // bucket / dir / file;
- через браузер Cloud Console Cloud Storage;
- с использованием команд gsutil cp или gsutil rsync.
Для облегчения связи Google Cloud Storage с Big Data на базе приложений Apache Hadoop или Spark, в 2019 году был выпущен специальный коннектор (Google Cloud Storage Connector, GCSC). Он представляет собой клиентскую Java-библиотеку с открытым исходным кодом, которая работает в JVM Hadoop, включая узлы данных, элементы MapReduce, исполнители Spark и пр., позволяя получить доступ к облачному хранилищу. Благодаря коннектору приложения Big Data с открытым исходным кодом, такие как задания Hadoop и Spark, могут читать и записывать данные непосредственно в облачное хранилище, а не в HDFS. Аналогичную возможность Cloud Storage Connector предоставляет через интерфейс командной строки Hadoop-совместимых файловых систем (Hadoop Compatible File System, HCFS), например, Apache Ozone. С учетом современного тренда на перевод ИТ-инфраструктуры в облако, хранение данных в Cloud-хранилище имеет следующие преимущества по сравнению с HDFS [3]:
- отсутствие накладных расходов на администрирование хранилища, в т.ч. обеспечение обновлений и высокой доступности HDFS;
- сокращение затрат на эксплуатацию Big Data системы по сравнению с давно работающим кластером Hadoop HDFS с тремя репликами на постоянных дисках;
- разделение хранилища данных от вычислений позволяет масштабировать каждый уровень независимо от других;
- хранилище остается доступным даже после завершения работы кластеров Hadoop;
- возможно совместное использование сегментов облачного хранилища между эфемерными (ephemeral) кластерами Hadoop, которые используются только во время выполнения заданий.
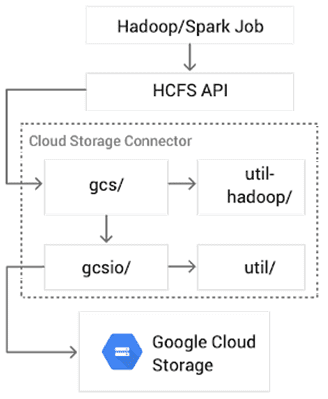
На уровне реализации Google Cloud Storage Connector представляет собой open-source интерфейс HCFS под лицензией Apache 2.0 для облачного хранилища и состоит из четырех основных компонентов [3]:
- gcs — реализация HDFS и каналов ввода/вывода;
- util-hadoop — общие утилиты, обеспечивающие функциональность Hadoop, совместно с другими коннекторами, в т. ч. аутентификацию и авторизацию;
- gcsio — высокоуровневая абстракция JSON API для облачного хранилища;
- util — служебные функции (обработка ошибок, конфигурация транспорта HTTP и пр.), используемые компонентами gcs и gcsio.
7 главных плюсов Google Cloud Storage Connector
Помимо основного назначения GCSC, которое состоит в облегчении взаимодействия данных в облачном хранилище с локальными Hadoop/Spark-заданиями, ключевыми преимуществами Google Cloud Storage Connector можно назвать следующие [3]:
- оптимизация механизма чтения колоночных Big Data форматов (Parquet, ORC), которая позволяет интеллектуально читать только те фрагменты файла (столбцы), нужные для обработки запроса. Коннектор полностью поддерживает раскрытие предикатов и читает только байты, запрашиваемые уровнем вычислений с помощью fadvise. Она пришла из Linux и позволяет приложениям предоставлять ядру операционной системы подсказку насчет шаблона доступа ввода-вывода: последовательное сканирование или случайный поиск. Это позволяет ядру выбирать подходящие методы упреждающего чтения и кэширования для увеличения пропускной способности или уменьшения задержки.
- совместная блокировка – изоляция для изменений каталога облачного хранилища, которая изолирует операции изменения каталога, выполняемые через shell-оболочку HDFS (команда hadoop fs) и другие интерфейсы API HCFS для Cloud Storage. Это предотвращает несогласованность данных во время конфликтующих операций каталога с облачным хранилищем, упрощает восстановление любых неудачных операций с каталогом и облегчает миграцию с HDFS в Cloud Storage.
- Распараллеливание модификации каталогов, помимо использования пакетного запроса, Cloud Storage Connector выполняет пакеты Cloud Storage параллельно, сокращая время переименования для каталога с 32 000 файлов с 15 минут до 1 минуты 30 секунд.
- оптимизация задержки за счет уменьшения количества необходимых запросов облачного хранилища для высокоуровневых операций файловой системы Hadoop;
- параллельное выполнение glob-алгоритмов обеспечивает наилучшую производительность при работе с глубокими и широкими файловыми деревьями;
- восстановление скрытых каталогов во время удаления и переименования вместо операций со списками и glob-объектами уменьшает временную задержку и устраняет необходимость в разрешениях на запись для запросов на чтение;
- согласованность чтения облачного хранилища разрешает запросы одной и той же версии объекта, предотвращая разночтение отличающихся версий и повышая производительность.
При том, что коннектор поставляется под эгидой корпорации Google, его исходный код полностью открыт и поддерживается Google Cloud Platform (GCP), включая предварительную настройку в Cloud Dataproc и облачных сервисах Hadoop и Spark, управляемых GCP. Однако, GCSC также может использоваться в других дистрибутивах Apache Hadoop – от MapR, Cloudera или Hortonworks. Это позволяет легко переносить локальные данные HDFS в облако или группировать рабочие нагрузки в GCP [3]. Данный факт является еще одним аргументом в пользу применения SaaS-подхода. В частности, из наиболее крупных примеров практического использования Google Cloud Storage Connector стоит отметить кейс соцсети Twitter, которая мигрировала с локальных Хадуп-кластеров в облачное объектное хранилище в 2018-2019 годах [4]. Примечательно, что именно на базе этого внедрения было реализовано одно из вышеотмеченных преимуществ – повышение эффективности чтения колоночных форматов с помощью разработанного Twitter прототипа использования запросов диапазона для чтения только столбцов. Это было сделано в середине 2018 года в рамках массового тестирования SQL-запросов для больших данных по колоночным файлам в облачном хранилище на примере датасета размером более 20 петабайт [3]. В следующей статье мы продолжим разговор про облачные сервисы аналитики Big Data и разберем, как устроена Хадуп-платформа Dataproc от Google: архитектура, принципы работы и механизмы обеспечения информационной безопасности.
Как на практике эффективно работать с облачными и локальными компонентами экосистемы Apache Hadoop для хранения и аналитики больших данных в проектах цифровизации частного бизнеса, а также государственных и муниципальных предприятий, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Hadoop
- Администрирование кластера Hadoop
- Безопасность озера данных Hadoop
- Hadoop для инженеров данных
- Основы Arenadata Hadoop
- Администрирование кластера Arenadata Hadoop
- Анализ данных с Apache Spark
Источники
- https://www.infoq.com/news/2019/09/Google-Cloud-Storage-Hadoop/
- https://cloud.google.com/dataproc/docs/concepts/connectors/cloud-storage
- https://cloud.google.com/blog/products/data-analytics/new-release-of-cloud-storage-connector-for-hadoop-improving-performance-throughput-and-more
- https://blog.twitter.com/engineering/en_us/topics/infrastructure/2019/the-start-of-a-journey-into-the-cloud/

