 718
718 
Содержание
Как сократить затраты на хранение исторических данных в ClickHouse для ИИ-сценариев, сохранив высокую скорость аналитики по широким таблицам и озеру данных: эволюция колоночной СУБД в новом проекте с исходным кодом Antalya от Altinity.
Проблемы совмещения ClickHouse с озерами данных и способы их решения
Благодаря колоночной структуре хранения данных ClickHouse не только обеспечивает быструю аналитику огромных объемов в реальном времени, но и неплохо подходит для задач машинного обучения. Об этом мы писали здесь и здесь. Эти варианты использования приводят к стремительному росту данных, поскольку релевантность и точность ML-модели напрямую зависит от размера обучающей выборки. Это приводит к росту затрат, т.к. в ClickHouse чаще всего используется табличный движок MergeTree с репликацией блоков данных минимум на 3 узла в кластере. Такая архитектура надежная, но на порядок дороже, чем хранение тех же данных в объектном хранилище, совместимом с S3. Кроме того, вычисления становятся дороже, т.к. в ClickHouse нет простого способа масштабировать вычисления для большого пакетного задания или разделить ресурсы для загрузки данных, от ресурсов для запросов.
Хотя рабочие нагрузки для аналитики в реальном времени, ИИ и пакетной отчетности исторически были разделены по разным видам хранилищ, сегодня они часто объединяются на одних и тех же данных, хранящихся в озерах и архитектурах Data LakeHouse, состоящих из объектного хранилища, Parquet и открытых табличных форматов, таких как Iceberg. Например, для мониторинга логов или веб-аналитики необходимо добавлять данные в ClickHouse постепенно, непрерывно загружая их из озера и сохраняя в таблицах колоночной БД для быстрой аналитики. В этом случае ClickHouse будет часто опрашивать S3, чтобы проверить наличие новых данных. При обнаружении новых файлов ClickHouse автоматически прочитает, загрузит и объединит все данные в свои таблицы.
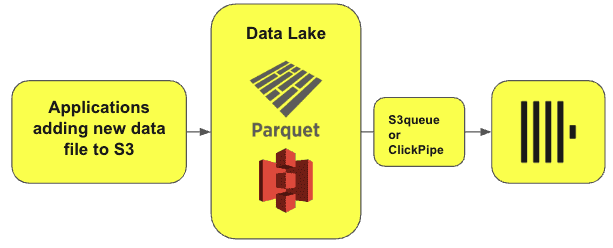
Данные из Data Lake также можно загружать в ClickHouse с помощью двойной записи. Обычно этот метод используется в корпоративных платформах данных, которые должны хранить данные компании, обеспечивая бесперебойный доступ и удобство использования для различных команд с разными требованиями и инструментами. В таких сценариях особенно полезен табличный формат Iceberg, который обеспечивает высокую производительность аналитических SQL-запросов с большими таблицами. Iceberg часто используется в озерах данных и архитектурах LakeHouse. При потоковой передаче данные публикуются в топик Kafka, откуда их считывают несколько потребителей, чтобы одновременно загрузить в таблицы ClickHouse и Iceberg. Такой подход отлично подходит для неизменяемых данных только для добавления (Append Only).
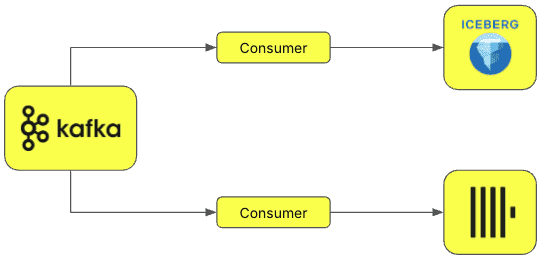
Таким образом, озера данных требуют приема, запроса и уплотнения данных в режиме реального времени. ClickHouse поддерживает это, но изначально не предполагает совмещения аналитики в реальном времени с долговременным хранением исторических данных. Хотя ClickHouse уже поддерживает Iceberg, DeltaLake и Hudi, предоставляя специальные движки таблиц, ему по-прежнему нужен прямой путь к таблице для запроса. Реализовать это можно через интеграцию с каталогами данных, где ClickHouse взаимодействует с каталогом и с хранилищем данных, чтобы читать правильные метаданные.
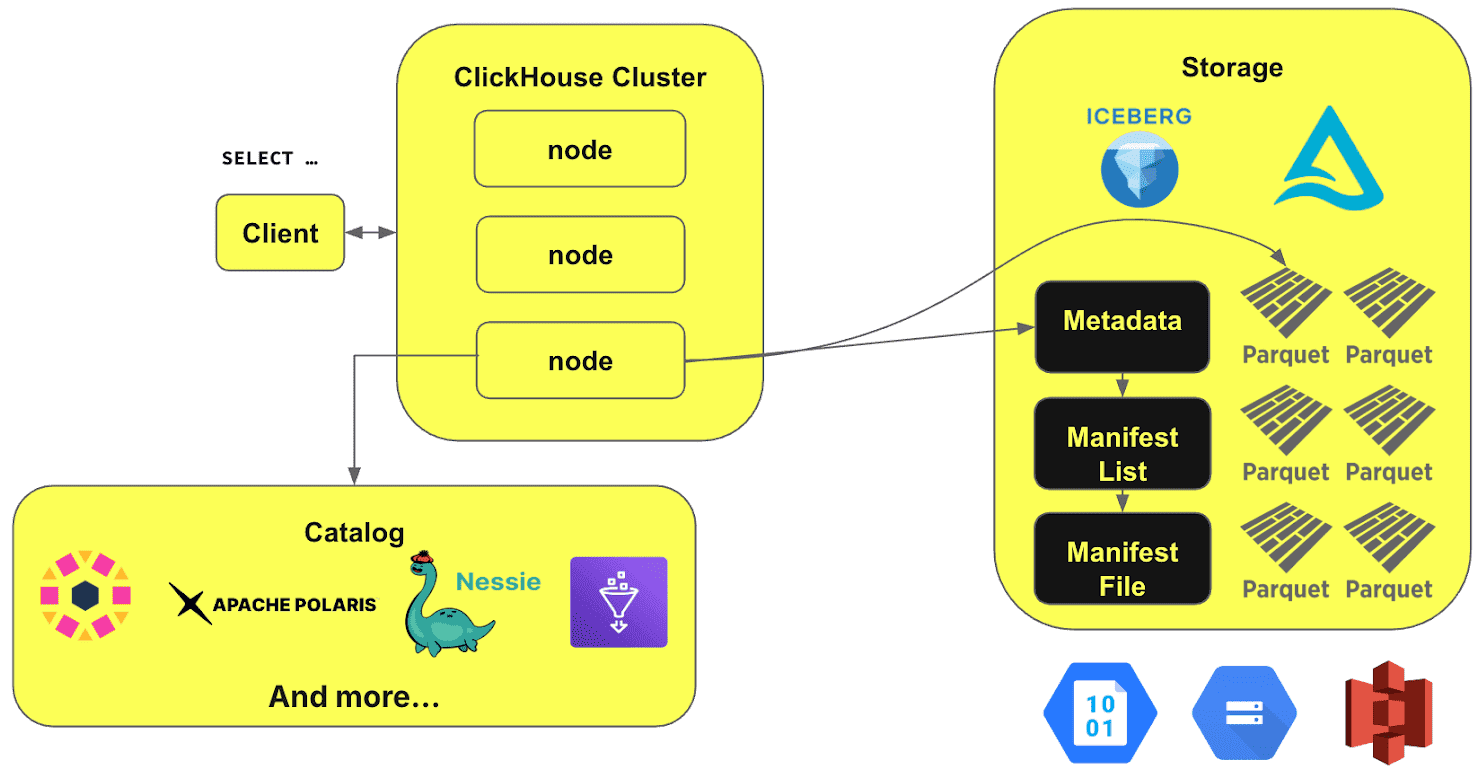
Устранить противоречие разных рабочих нагрузок поможет разделение вычислений и хранения. Реализовать это можно через интеграцию горячих данных в ClickHouse с историческим хранилищем в озере данных в виде Iceberg-таблиц. Чтобы сделать это, компания Altinity запустила проект Antalya, который адаптирует ClickHouse для использования формата Iceberg в озере данных в качестве основного хранилища. При этом сохраняются все преимущества ClickHouse, от поддержки SQL с параллельным выполнением, RBAC-политикой авторизации и многоуровневое хранилище. Таким образом, хранение исторических данных в таблицах Iceberg снижает стоимость хранения в 10 раз и расширяет спектр рабочих нагрузок, включая ИИ. Также упрощается доступ к данным: приложения могут видеть их, независимо от расположения, из одного SQL-соединения ClickHouse. Быстрое и независимое масштабирование захвата, слияния, преобразования и аналитических запросов снижает дорогостоящее и избыточное выделение вычислительных ресурсов, позволяя оптимизировать расходы на инфраструктуру благодаря спотовым экземплярам.
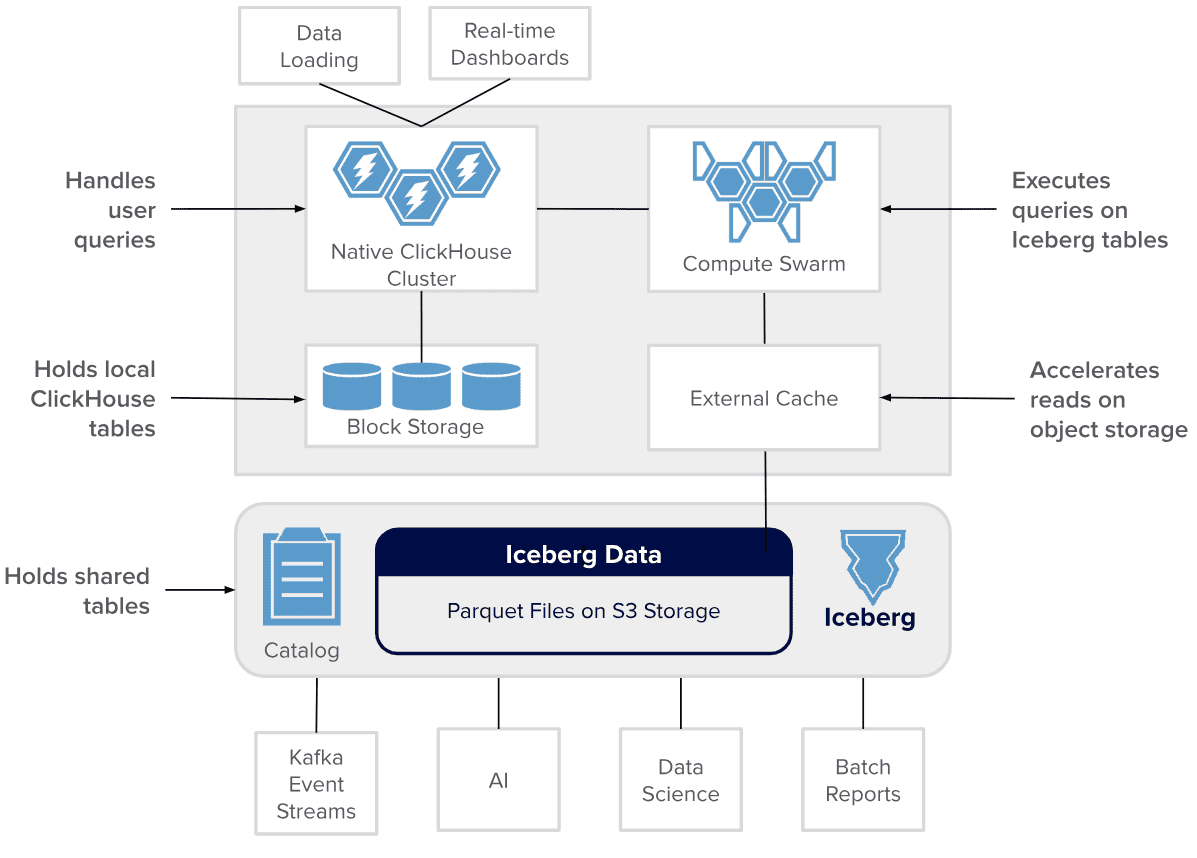
Таким образом, Antalya — это новый мощный способ создания высокопроизводительных и недорогих аналитических систем в реальном времени для таблиц общих озер данных. Это достигается благодаря следующим техническим решениям:
- Iceberg, Parquet и S3 для ускорения чтения с помощью фильтров Блума, оптимизации PREWHERE, кэширование метаданных Parquet и пр.
- Улучшения доступа к данным благодаря stateless-серверам оркестратора Docker-контейнеров Swarm, которые предлагают вычисления в реальном времени на таблицах Iceberg с использованием дешевых серверов ClickHouse без сохранения состояния. Также поддерживается распределенное кэширование и многоуровневое хранение в хранилище Iceberg. Это обеспечивает сокращение расходов, сохраняя высокую скорость обработки запросов в реальном времени.
- Облачная природа среды выполнения, которая позволяет запускать системы где угодно. Шаблоны облачных операций обеспечивают быстрое автоматическое масштабирование Swarm, мониторинг, развертывание кэша и самого Kubernetes.
Чтобы понять, как работает Antalya, далее рассмотрим варианты использования и особенности реализации этой архитектуры.
Архитектура и примеры использования проекта Antalya
Как уже было отмечено, таблицы Iceberg с Parquet снижают затраты на хранение в 10 раз по сравнению с реплицированными MergeTree-таблицами ClickHouse. Для этого разработчики Antalya решили ускорить чтение Parquet-файлов и масштабировать вычисления с помощью кластеров Swarm. Кластеры Swarm — это масштабируемые пулы саморегистрирующихся серверов ClickHouse без сохранения состояния. Именно они читают файлы Parquet, ускоряя выполнение запросов и сокращая нагрузку на существующие приложения ClickHouse.
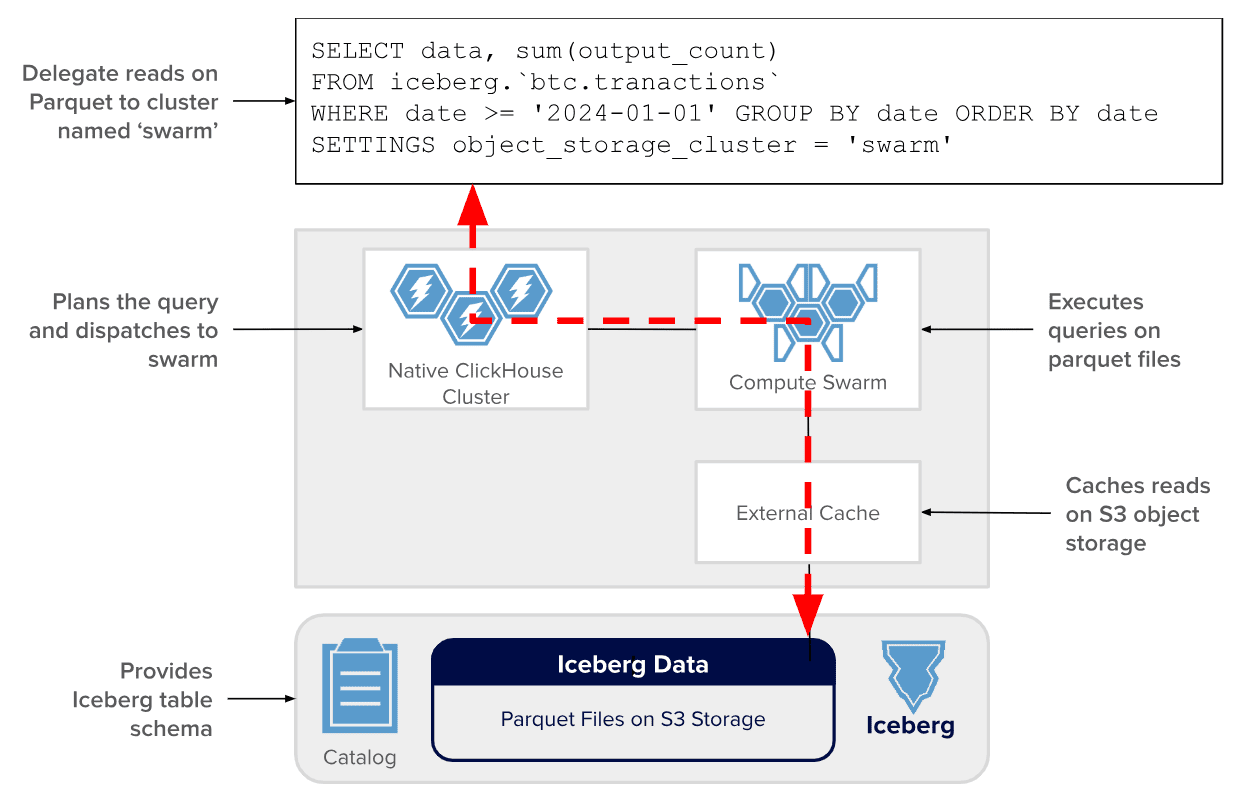
Быстрая и дешевая скорость чтения файлов Parquet в Swarm обеспечивается следующими факторами:
- Кэширование, которое сокращает задержку обработки данных на 90% и более. Узлы-инициаторы ClickHouse кэшируют метаданные Iceberg, что снижает стоимость планирования запросов. Кластеры Swarm кэшируют блоки файлов S3 и метаданные Parquet-файлов, снижая стоимость их на определенных узлах кластера.Внешние HTTP-кэши сохраняют запросы API к S3, включая медленные вызовы S3 ListObjectsV Они уменьшают количество вызовов API, сокращают задержку во всем кластере Swarm и затраты на облачное объектное хранилище.
- Автоматическое масштабирование с использованием типовых инструментов Kubernetes. Узлы Swarm регистрируются при появлении в кластере и отменяются при их исчезновении.
- Эфемерность – узлы Swarm могут работать на спотовых экземплярах, что снижает затраты на вычисления более чем вдвое. А минимальный объем хранилища сокращает затраты еще больше.
Примечательно, что кластеры Swarm не ограничиваются только таблицами Iceberg. Они могут читать любые Parquet-данные в S3, включая таблицы Hive, а также файлы Parquet, использующие подстановочные знаки.
Чтобы снизить затраты на хранение исторических данных, Antalya поддерживает многоуровневое хранилище в ClickHouse, которое автоматически перемещает табличные данные в более дешевое место хранения по мере их устаревания. При этом пользователи по-прежнему видят исходную одну таблицу, независимо от того, где фактически хранятся данные. Antalya расширяет многоуровневое хранилище, перемещая старые данные в Iceberg, что снижает стоимость их хранения примерно в 10 раз. При этом запросы, которые попадают в многоуровневые таблицы, автоматически направляются в локальное хранилище и хранилище Iceberg одновременно. Swarm обеспечивает дополнительную вычислительную мощность для сканирования холодных данных. Это помогает сохранять кластеры, которые управляют горячими данными, небольшими. Приложения видят только один набор результатов.
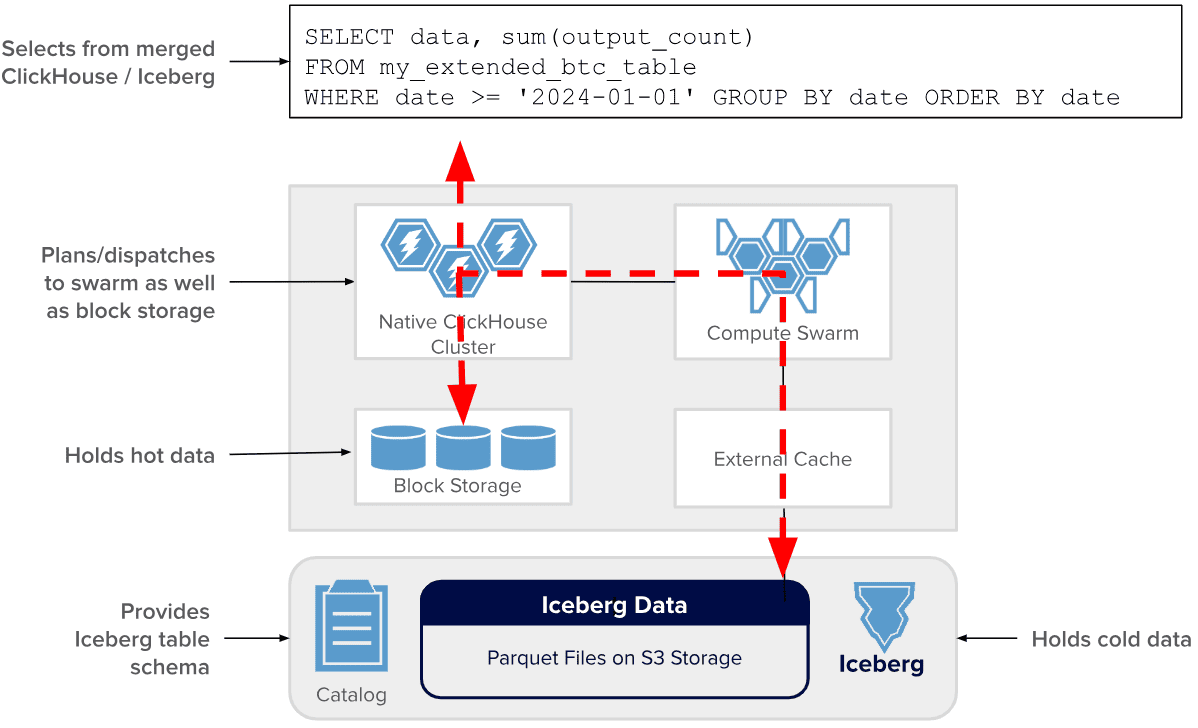
В заключение отметим, что Antalya активно использует существующие возможности ClickHouse, такие как табличный движок MergeTree, а также функции, позволяющие избегать пробелов или дубликатов в данных при их выборке. Как и ClickHouse, Antalya является проектом с открытым исходным кодом и доступен в ветке Antalya в репозитории Altinity ClickHouse на GitHub. Это современный инструмент построения масштабируемой архитектуры данных, сочетающий возможности ClickHouse, облачные операции и озера на Iceberg/Parquet для выскопроизводительных и экономичных аналитических систем с запуском в любом месте.
Освойте ClickHouse на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

