 1103
1103 
Содержание
В этой статье рассмотрим архитектуру и принципы работы системы хранения, аналитической обработки и визуализации больших данных на базе компонентов Hadoop, таких как Apache Spark, Hive, Tez, Ranger и Knox, развернутых в облачном Google-сервисе Dataproc. Читайте далее, как подключить к этим Big Data фреймворкам BI-инструменты Tableau и Looker, а также что обеспечивает комплексную информационную безопасность такого SaaS-решения.
Облачный Hadoop от Google: что это и кому нужно
Как мы уже упоминали, миграция с локальных кластеров в облака остается одним из наиболее востребованных трендов в области Big Data. Не случайно практически каждый SaaS/PaaS-провайдер предлагает полностью готовый или гибко настраиваемый облачный продукт на базе Apache Hadoop и Spark, а также других компонентов для хранения и анализа больших данных. Ценообразование при этом обычно строится по модели затраченных ресурсов, которые масштабируются в зависимости от текущего спроса (on-demand).
Одним из таких решений, наиболее популярных сегодня, является Dataproc – управляемая служба Spark и Hadoop, которая позволяет использовать open-source инструменты стека Big Data для пакетной обработки, запросов, потоковой передачи и машинного обучения. Сервисный подход позволяет автоматизировать управление кластером, включая процедуры их создания, настройки и отключения, если вычислительные мощности больше не нужны. Доступ к Dataproc возможен через его пользовательский интерфейс (UI), REST API, Cloud SDK и облачные клиентские библиотеки (Cloud Client Libraries) [1].
Рассмотрим типичный кейс использования Dataproc для BI-аналитики на больших данных. Предположим, требуется предоставить аналитикам данных безопасный доступ к инструментам бизнес-аналитики (BI, Business Intelligence), чтобы они могли эффективно извлекать из массивов Big Data ценную для бизнеса информацию. Чтобы более эффективно использовать вычислительные мощности и гибкую масштабируемость с минимизацией затрат, целесообразно обратить внимание на облачные решения, например, на базе Dataproc от Google. Как это устроено, мы подробнее рассмотрим далее.
Как устроена система аналитики Big Data на Dataproc: архитектура и принципы работы
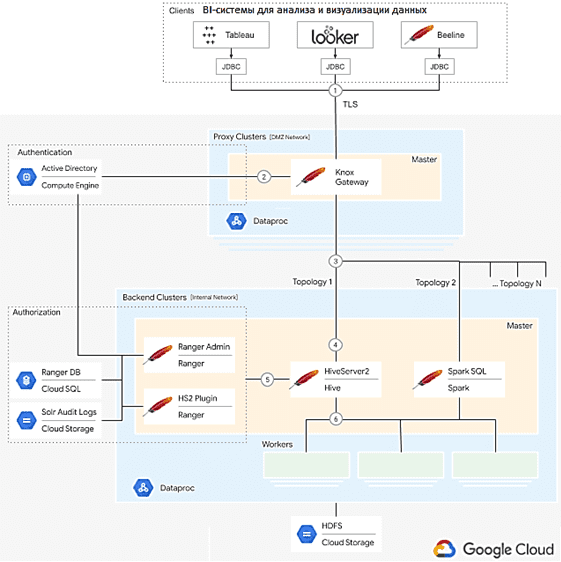
Клиентские приложения, в частности, BI-системы Tableau и Looker, подключаются к единой точке входа в Dataproc-кластер через JDBC. Точка входа предоставляется Apache Knox, установленным на главном узле кластера. Напомним, Apache KNOX – это REST API и шлюз приложений для компонентов экосистемы Hadoop, которая обеспечивает единую точку доступа для всех HTTP-соединений с Hadoop-кластерами и систему единой аутентификации Single Sign On (SSO) для сервисов и пользовательского интерфейса компонентов этой Big Data экосистемы. Apache Knox Gateway реализует внешний уровень защиты кластера Hadoop, обеспечивая безопасность по периметру кластера. Apache Knox разработан как обратный прокси-сервер с подключаемыми поставщиками для аутентификации, авторизации, аудита и других услуг. Клиенты отправляют в Knox запросы, URL-адреса и параметры которых уходят далее в соответствующую службу Hadoop. Таким образом, Knox является центральным элементом архитектуры, выполняя роль единой точки входа, которая прозрачно обрабатывает запросы клиента и скрывает сложность системы. Связь с Apache Knox защищена TLS, а аутентификация реализована через каталог LDAP.
После аутентификации Apache Knox направляет запрос пользователя в один из нескольких серверных кластеров. Маршруты и конфигурация определяются как пользовательские топологии. Дескриптор топологии определяет характер аутентификации, URI внутренних сервисов для пересылки запросов и простые списки контроля доступа (ACL) для авторизации каждой службы.
Apache Hive в выбранном внутреннем кластере принимает SQL-запрос, выполняет его семантический анализ и строит направленный ациклический граф (DAG) этапов, которые должны выполняться механизмом обработки. Таким образом, Hive транслирует пользовательские SQL-запросы в механизмы обработки больших данных, доступные в Apache Hadoop. Одним из них является Apache Tez, который отвечает за выполнение групп DAG, подготовленных Hive, и последующий возврат результатов.
За детальную авторизацию пользователя отвечает Apache Ranger – инфраструктура обеспечения, мониторинга и управления комплексной безопасностью данных на платформе Hadoop. Ranger перехватывает запрос, проверяет авторизацию пользователя и определяет правомочность обработки данных. Если проверка прошла успешно, серверная служба обрабатывает запрос и возвращает результаты. Для крупномасштабной обработки данных также применяется Apache Spark, который поддерживает общее выполнение DAG и может использоваться Hive. В частности, Spark SQL был изначально построен на основе HiveServer2 и позволяет выполнять SQL-запросы в Apache Spark. Примечательно, что пока Spark SQL не имеет официальной поддержки подключаемого модуля Ranger, поэтому авторизация должна выполняться через общие списки управления доступом (ACL) в Apache Knox [2]. Подробнее про обеспечение информационной безопасности кластера Apache Hadoop с помощью Knox и Ranger мы рассказывали здесь.
Завтра мы продолжим разговор про использование компонентов экосистемы Apache Hadoop в Dataproc и рассмотрим особенности процесса миграции с локальной инфраструктуры в облачный кластер. А подробнее разобраться с основами Hadoop, а также освоить особенности администрирования и эксплуатации этой экосистемы хранения и обработки больших данных, вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Основы Hadoop
- Администрирование кластера Hadoop
- Безопасность озера данных Hadoop
- Hadoop для инженеров данных
- Построение конвейеров обработки данных с Apache Airflow и Arenadata Hadoop
- Основы Arenadata Hadoop
- Администрирование кластера Arenadata Hadoop
Источники
- https://cloud.google.com/dataproc/docs/concepts/overview
- https://medium.com/google-cloud/connecting-your-visualization-software-to-hadoop-on-google-cloud-64b55f536fab

