 1034
1034 
Содержание
ORC (Optimized Row Columnar) – это колоночно-ориентированный (столбцовый) формат хранения Big Data в экосистеме Apache Hadoop. Он совместим с большинством сред обработки больших данных в среде Apache Hadoop и похож на другие колоночные форматы файлов: RCFile и Parquet. Формат ORC был разработан в феврале 2013 года корпорацией Hortonworks в сотрудничестве с Facebook, а месяц спустя Cloudera и Twitter представили Apache Parquet [1].
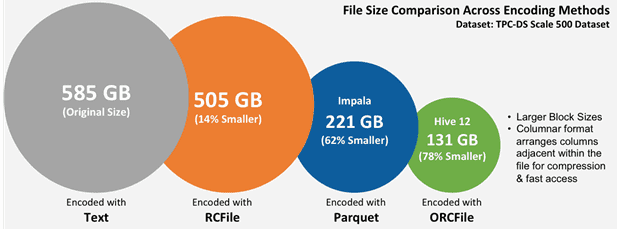
Как устроен Apache ORC
ORC оптимизирован для чтения потоков Big Data, включая интегрированную поддержку быстрого поиска нужных строк. Колоночное хранение данных позволяет читать, распаковывать и обрабатывать только те значения, которые необходимы для текущего запроса. Поскольку данные в ORC строго типизированы, поэтому при записи выбирается кодировка, наиболее подходящая для каждого типа данных, создавая внутренний индекс по мере записи файла [2].
Как и другой популярный колоночный формат Big Data файлов, Apache Parquet, файлы ORC имеют разделяемую внутреннюю структуру – разбиение на независимые друг от друга полосы (stripes, страйпы) размером по умолчанию 64 МБ. Каждый страйп (strip) – это единица распределенной работы. Внутри страйпов столбцы отделены друг от друга, что обеспечивает возможность избирательного чтения данных, гарантируя высокую скорость обработки [2]. Предикаты и индексы позволяют определить, какие страйпы в файле необходимо прочитать для конкретного запроса, а индексы сужают область поиска до группы строк (row group, 10 тысяч строк), еще больше повышая скорость чтения информации. Индексы строятся по каждой из колонок, что влияет на скорость чтения, увеличивая размер. При потоковом чтении индексы можно не читать [3].
Метаданные, которые составляют существенную часть файла, хранятся в сжатом виде и включают [3]:
- статистическую и описательную информацию – в частности, формат позволяет воссоздать таблицу, которая в нем хранится, включая названия и типы полей;
- индексы;
- информация о разбиении на страйпы и потоки.
Значения колонок также хранятся в сжатом виде, обеспечивая возможность чтения и распаковки только нужного блока данных. Сжатие влияет и на размер, и на скорость чтения [3]. Таким образом, благодаря сжатию ORC оптимально хранит метаданные, обеспечивая баланс между скоростью потокового чтения и компактностью хранения. ORC поддерживает полный набор типов, включая сложные (структуры, списки, карты и объединения) [2].
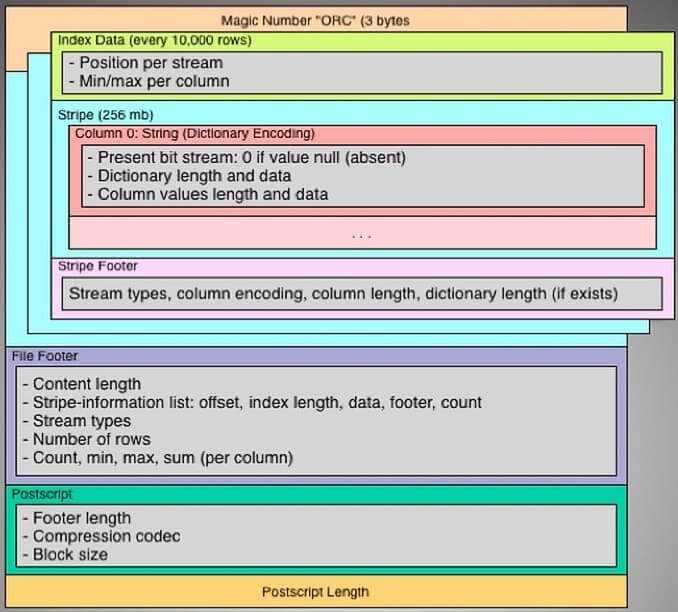
Где и зачем используется формат Big Data файлов Optimized Row Columnar
На практике многие крупные пользователи Hadoop используют этот формат из-за его эффективности и быстроты обработки. В частности, соцсеть Facebook хранит десятки петабайт в своем хранилище данных именно в формате ORC, который значительно быстрее, чем RCFile или Parquet. Yahoo также использует ORC для хранения своих данных [2].
Optimized Row Columnar часто сравнивают с другим машиночитаемым колоночно-ориентированным форматом хранения файлов Big Data – Apache Parquet. Они оба появились примерно в одно время и служат для одних и тех же целей – эффективного хранения информации в долговременной (а не оперативной) памяти за счет столбцовой структуры данных и высокого коэффициента сжатия. Однако, если в большинстве случаев файлы Parquet хранятся на жестком диске, то ORC активно применяется для работы с Big Data в Apache Hive — СУБД на основе платформы Hadoop. В связи с этим, по сравнению с Parquet, формат Optimized Row Columnar обладает следующими ключевыми преимуществами [4]:
- индексация блоков для каждого столбца, что делает операции вводы-выводы более эффективными, позволяя Hive пропускать чтение целых блоков данных при отсутствии предикатов;
- генерация наиболее эффективного графа при оптимизации SQL-запросов благодаря считыванию метаданных на уровне столбцов (Cost Based Optimizer);
- соответствие ACID-требованиям к транзакциям (Atomicity — Атомарность, Consistency — Согласованность, Isolation — Изолированность, Durability — Долговечность) [5].
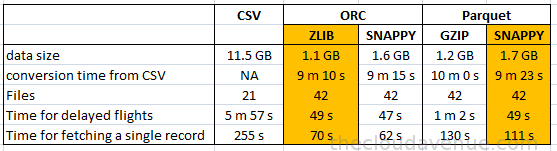
Источники
- https://en.wikipedia.org/wiki/Apache_ORC
- https://orc.apache.org/docs/
- https://habr.com/ru/company/alfastrah/blog/458552/
- https://community.cloudera.com/t5/Support-Questions/ORC-vs-Parquet-When-to-use-one-over-the-other/td-p/95942
- https://ru.wikipedia.org/wiki/ACID