 1058
1058 
MapR Convergent Data Platform (MapRCDP) — дистрибутив Apache Hadoop с набором программ, библиотек и утилит Apache Software Foundation, а также средств собственной разработки американской компании MapR для больших данных (Big Data) и машинного обучения (Machine Learning) [1].
Существует три версии MapRCDP:
- Community Edition (M3) — бесплатная версия сообщества;
- Enterprise Edition (M5) — обеспечивает высокую доступность и защиту данных, включая мультиузловый NFS;
- Enterprise Database Edition (M7) – включает данные структурированных таблиц изначально на уровне хранилища и предоставляет гибкую базу данных NoSQL.
MapRCDP может быть установлен на многих версиях Red Hat Enterprise Linux, CentOS, Ubuntu, Oracle Linux и SUSE.
Состав и архитектура MapR
Как и другие популярные дистрибутивы Hadoop (Cloudera, HortonWorks, ArenaData), кроме его основных модулей, MapR содержит дополнительные продукты для работы с большими данными и машинным обучением:
- решения для интеграции, управления потоками и доступа к данными (Flume, Sqoop, Hue, HttpFs);
- фреймворки для распределённой и потоковой обработки, а также брокеры сообщений (Spark, Storm, Kafka)
- нереляционные СУБД и SQL-движки для Big Data аналитики (HBase, Hive, Impala, Spark SQL, Drill);
- координаторы и планировщики задач (Zookeeper, Sahara, Oozie);
- средства Machine Learning (Mahout, MLlib);
- высокоуровневый язык программирования запросов к большим слабоструктурированным наборам данных (Pig);
- продукт полнотекстового и фасетного поиска, динамической кластеризации, интеграции с базами данных и обработка документов со сложным форматом (Solr).
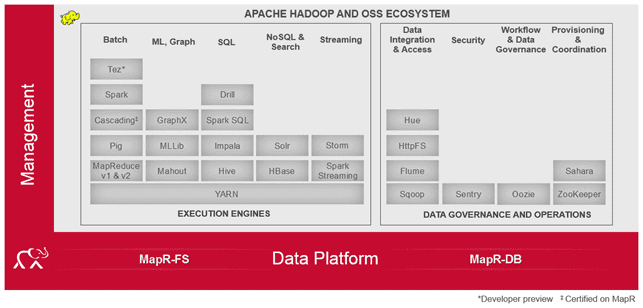
Однако, в отличие от других дистрибутивов Hadoop (Cloudera, HortonWorks, ArenaData, HDInsight), вместо HDFS (Hadoop Distributed File System), MapR использует свою распределенную файловую систему – MapR-FS, а также свою базу данных – MapR-DB.
История появления и развития
2009 – год основания компании выходцами из корпорации Google, Lightspeed Venture Partners, Informatica, EMC Corporation and Veoh [1]
2011 – выпуск корпоративного дистрибутива Apache Hadoop с собственной распределенной файловой системой (MapR-FS) [2];
2012 — доступна поддержка операционных систем Windows и Mac OS [3].
2013 – выпуск MapR DB, NoSQL СУБД с поддержкой Apache HBase API и JSON документов [2];
2014 – выпуск Apache Drill, механизма SQL-запросов с низкой задержкой для широкомасштабных наборов данных, включая структурированные и полуструктурированные/вложенные данные, в т.ч. в форматах JSON и Parquet. Также Drill способен выполнять динамическое обнаружение схемы [4].
2015 – выпуск MapR Streams, масштабируемой системы передачи сообщений, поддерживающую Apache Kafka API и обладающую высокой производительностью и пропускной способностью [2].
2019 — корпорация Hewlett Packard Enterprise (HPE) приобрела компанию MapR, включая продукт MapRCDP и другую интеллектуальную собственность в областях искусственного интеллекта, машинного обучения и управления аналитическими данными [5].
Применение MapRCDP
Наиболее ярким примером использования MapRCDP в качестве основы для Big Data инфраструктуры является индийский проект Aadhaar по построению государственной системы идентификации. Его суть состоит в реализации биометрической базу данных населения, чтобы идентифицировать гражданина Индии на основе его отпечатков пальцев и сканирования радужной оболочки глаза. Проект запущен в 2009 году и работает на основе MapRCDP. Уже более 1 миллиарда жителей зарегистрированы в системе, что составляет 95% взрослого населения Индии. Каждый день в системе регистрируются 500000 новых пользователей. Более 100 миллионов авторизаций выполняется системой ежедневно. Среднее время отклика – 200 миллисекунд. Система использует зеркало MapRCDP для большей доступности и для предотвращения ошибок, поэтому даже перебои электричества или сети выведут ее из строя [2].
Все о настройке, администрировании и использовании инфраструктуры Hadoop для больших данных и машинного обучения на наших компьютерных курсах обучения инженеров, администраторов и аналитиков Big Data и Machine Learning в Москве:
- INTR: Основы Hadoop;
- HADM: Администрирование кластера Hadoop;
- HIVE: Hadoop SQL Hive администратор.
- DSEC: Безопасность озера данных Hadoop
- HDDE: Hadoop для инженеров данных
Источники
- https://en.wikipedia.org/wiki/MapR
- https://habr.com/ru/post/313390/
- https://www.itweek.ru/idea/article/detail.php?ID=144155
- http://qaru.site/questions/tagged/apache-drill
- https://www.hpe.com/us/en/newsroom/press-release/2019/08/hpe-advances-its-intelligent-data-platform-with-acquisition-of-mapr-business-assets/