 1016
1016 
Содержание
Рассмотрев ключевые сходства и различия Cassandra и HBase, сегодня мы поговорим, в каких случаях стоит выбирать ту или иную нереляционную СУБД для обработки больших данных (Big Data) в NoSQL-хранилище.
Где используются NoSQL-СУБД в Big Data
Прежде всего отметим основные области применения рассматриваемых нереляционных СУБД. Проанализировав наиболее известные примеры использования (use cases) Apache HBase и Кассандры, можно сделать вывод, что обе системы широко применяются для обработки временных рядов в следующих направлениях Big Data:
- показания smart-датчиков в IoT/IIoT;
- сбор и аналитика событий пользовательского поведения (действия, счетчики веб-сайтов и т.д.), в том числе для построения рекомендательных систем, о чем мы рассказывали здесь на примере стримингового сервиса Spotify;
- финансовые системы (биржевая аналитика, обнаружение мошенничества);
- агрегация данных из систем обмена сообщениями (чаты, мессенджеры, электронная почта, смс и пр.)
Все вышеотмеченные приложения обусловлены главными достоинствами Apache HBase и Cassandra: отказоустойчивостью, масштабируемостью, гибкой моделью данных и высокой скоростью обработки информации [1]. Однако, несмотря на общие свойства и области прикладного использования, иногда необходимо выбирать между этими двумя системами. Для этого важно учитывать контекст их применения и специфические характеристики каждой СУБД, о чем мы поговорим далее.
Ключевые аргументы в пользу Apache HBase
Напомним, HBase работает поверх Apache Hadoop, храня данные в HDFS и используя службу Zookeeper для координации работ между сервисами, управления их конфигурациями и синхронизацией. Поэтому при наличии уже существующей хадуп-инфраструктуры целесообразно сделать выбор в пользу Apache HBase. Однако, с учетом специфики распределения данных по узлам кластера согласно механизму регионирования, для работы HBase необходимо достаточное количество региональных серверов.
Благодаря своим архитектурным особенностям (блочный кэш HDFS, Bloom-фильтры и собственная система индексов), эта NoSQL-СУБД считается более подходящей для произвольного доступа к данным в виде множества согласованных операций чтения. Кроме того, она позволяет работать с большими данными как в поточном, так и в пакетном режиме, в. т.ч. используя преимущества вычислительной модели MapReduce [2].
Наконец, стоит помнить о наличии целого ряда инструментов, позволяющих выполнять SQL-запросы к данным, хранящимися в нереляционной СУБД: Apache Phoenix, Drill, Hive и Cloudera Impala. Также HBase предоставляет разработчику Big Data собственные REST-интерфейсы и другие API, которые на практике бывают удобнее аналогичных решений Кассандры (SQL-подобного языка CQL, Java- и Thrift-API) [3].
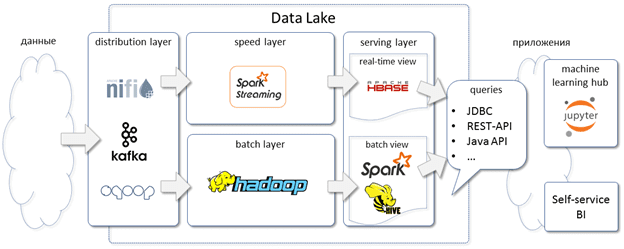
Таким образом, с учетом некоторых ограничений, HBase может быть основой OLAP- и даже OLTP-решений, когда ACID-транзакции не являются строго обязательными. Например, если необходимо просканировать огромные объемы информации, чтобы найти какие-то конкретные данные в небольших количествах. Из-за отсутствия дублирования данных, HBase будет отличным выбором. Также эта СУБД подойдет для работы с данными по моделям машинного обучения (Machine Learning), организации корпоративных хранилищ и озер данных (Data Warehouse, Data Lake) с целью BI-аналитики [1]. В частности, именно так Apache HBase используется в российском отделении Раффайзен-банка [4].
Когда использовать Cassandra и почему
Кассандру стоит предпочесть в следующих случаях:
- необходима самостоятельная система, независящая от сторонней инфраструктуры;
- требуется ACID-поддержка транзакций (хотя легковесная, бы на уровне одной записи) и вторичная индексация (без привлечения дополнительных инструментов, как Apache Phoenix в случае HBase) [5];
- проектируемая система больше ориентирована на запись, чем на чтение данных – Cassandra записывает информацию быстрее, чем читает, о чем мы подробно писали здесь.
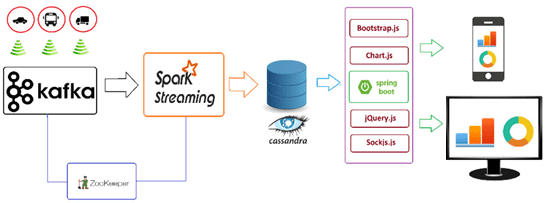
Таким образом, Cassandra отлично подходит для веб- или мобильных приложений, а также проектов со сложной аналитикой и анализом в реальном времени для географически распределенных Big Data систем. Например, приложение транспортного мониторинга, которое в режиме онлайн собирает и обрабатывает информацию с IoT-устройств, расположенных на наземном транспорте (автомобили, автобусы, грузовые машины и т.д.) [6].
Как настроить и эффективно эксплуатировать нереляционные СУБД для интерактивной аналитики больших данных, вы узнаете на наших практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
Источники
- https://stackoverflow.com/questions/40957891/hbase-for-real-time-application
- https://habr.com/ru/post/258581/
- https://habr.com/ru/company/raiffeisenbank/blog/332496/
- https://data-flair.training/blog/hbase-vs-cassandra/
- https://www.infoq.com/articles/traffic-data-monitoring-iot-kafka-and-spark-streaming/

