 1338
1338 
Содержание
Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS.
Рекомендательная система Spotify: зачем она нужна и что должна делать
Начнем с описания самого сервиса: Spotify – это интернет-ресурс потокового аудио (стриминговый), позволяющий легально и бесплатно прослушивать более 50 миллионов музыкальных композиций, аудиокниг и подкастов, в режиме онлайн, т.е. не загружая их на локальное устройство. Этот сервис доступен в США, Европе, Австралии и Новой Зеландии, а также в некоторых странах Азии и Африки. В общем случае доля сервиса составляет более 36 % мирового аудиостриминга, при этом большая часть (70%) прослушиваний выполняется через плейлисты, а не по поисковым запросам или авторским страницам [1].
С учетом большого числа пользователей (60 миллионов), огромного каталога всевозможного аудиоконтента и специфики прослушиваний через плейлисты (более 1,5 миллиардов плейлистов), тема рекомендательных систем для Spotify весьма актуальна. Главная задача любой рекомендательной системы – это проинформировать пользователя о продукте, который может быть ему интересен в данный момент времени. В результате этого клиент получает не навязчивую рекламу, а полезную информацию, а сервис зарабатывает на предоставлении качественных услуг [2].
Суть работы рекомендательной системы состоит в накоплении статистики по пользователям и продуктам с последующим формированием рекомендаций. Различают 2 основные стратегии создания рекомендательных систем [3]:
- фильтрация на основе содержания (Content-based), когда по анализу данных о контенте создаются профили пользователей (включая демографический, географический и прочие признаки, описывающие потребителя) и объектов (жанр, артист и другие атрибуты, характеризующие продукт) с целью выявления предпочтений пользователя.
- коллаборативная фильтрация (User-based), основанная на ретроспективном анализе пользовательского поведения, независимо от рассматриваемого объекта. Это позволяет учитывать некоторые неявные характеристики, которые сложно выразить при создании профиля. При всех положительных свойствах рекомендательных систем этого типа, для них характерна проблема холодного старта, когда данных о новых пользователях или объектах еще недостаточно для формирования адекватных рекомендаций.
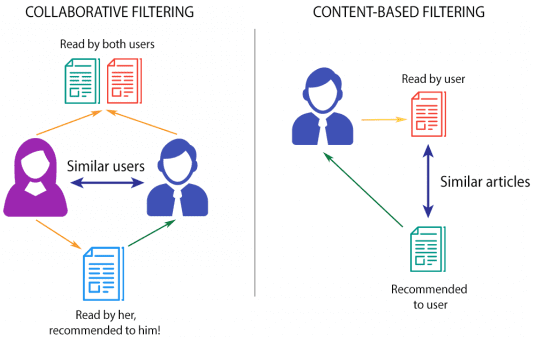
В случае Spotify больше подходит стратегия коллаборативной фильтрации, адаптированная к потребностям конкретного пользователя в зависимости от времени суток. Она учитывает не только общие клиентские интересы и предпочтения, но и временной контекст. Например, любитель тяжелой рок-музыки слушает ее по утрам, по пути на работу, а вечером укладывает детей спать под нежные музыкальные композиции совсем другого жанра [4]. Сформировать такую модель предиктивной аналитики, которая предугадывает поведение пользователя, помогают методы машинного обучения (Machine Learning).
Таким образом, сервис Spotify поставил задачу разработки такой системы персональных рекомендаций, которая должна анализировать данные в реальном времени и историческую статистику, чтобы, соответственно понимая контекст и поведение пользователя, предлагать ему наиболее релевантные аудиозаписи [4].
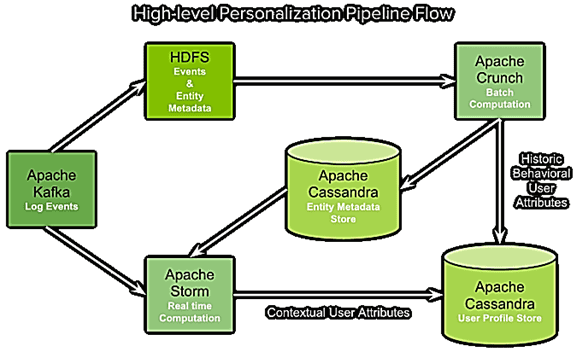
Архитектура и основные возможности Big Data системы сервиса Spotify
Для достижения поставленной бизнес-цели была разработана рекомендательная система на базе эффективного сочетания соответствующих Big Data технологий: Apache Cassandra, Kafka, Storm и Hadoop. Каждый из компонентов отвечает за конкретную часть архитектуры:
- брокер сообщений Apache Kafka обеспечивает сбор и агрегацию пользовательских логов;
- распределенный потоковый фреймворк Apache Storm реализует обработку событий в реальном времени;
- библиотека Apache Crunch используется для запуска пакетных заданий MapReduce в Hadoop и отправки данных в Cassandra для хранения атрибутов пользовательского профиля и метаданных об объектах (списки воспроизведения, исполнители и пр.). Эта Java-библиотека, работающая поверх Hadoop и Apache Spark, предоставляет среду для написания, тестирования и запуска конвейеров MapReduce, состоящих из множества пользовательских функций. Этот API особенно полезен при обработке данных, которые не вписываются в реляционную модель, в частности, временные ряды, сериализованные форматы объектов (protocol buffers или записи AVRO), а также строки и столбцы HBase [5].
- Распределенная файловая система Apache Hadoop HDFS хранит информацию о пользовательском поведении в виде записей о событиях и метаданные об объектах.
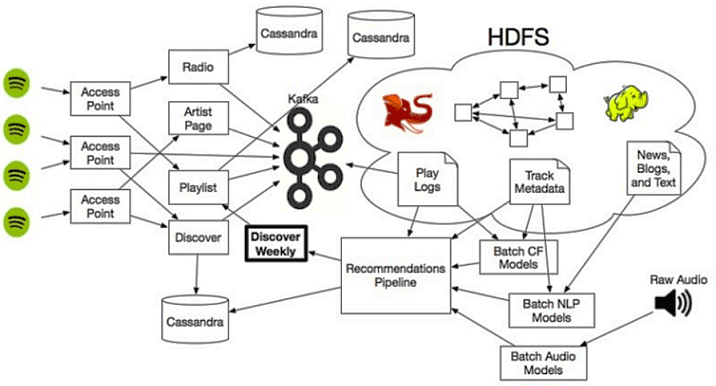
Таким образом, Apache Kafka собирает и агрегирует данные по пользовательским событиям (завершение аудиозаписи, включение рекламы), откуда их считывают 2 группы подписчиков (consumer), подписанных на разные темы (topic) [4]:
- все необработанные логи сперва записываются в распределенную файловую систему Apache Hadoop (HDFS), а затем обрабатываются с помощью Crunch, удаляя повторяющиеся события, отфильтровывая ненужные поля и преобразуя записи в формат AVRO.
- подписчики Kafka в топологиях Storm используют информацию о пользовательских событиях для вычислений в реальном времени.
Другие конвейеры Crunch принимают и генерируют метаданные объектов (жанр, темп, исполнители и пр.). Эта информация также хранится в HDFS и экспортируется с помощью Crunch в Cassandra для поиска в реальном времени в конвейерах Storm. Таким образом, кластер Cassandra обеспечивает хранение метаданных объектов. Конвейеры Storm обрабатывают исходные события из Kafka, отфильтровывая и обогащая их метаданными объектов, группируя по пользователям и определяя клиентские атрибуты с помощью специальных алгоритмов машинного обучения [6]. Такая комбинация пользовательских атрибутов представляет собой профиль пользователя, также хранящийся в кластере Cassandra [4].
Роль Apache Cassandra в рекомендательной системе стримингового сервиса
Благодаря своим архитектурным особенностям и ключевым достоинствам, именно Apache Cassandra, в отличие других СУБД, используемых в Spotify (Memcached, Sparkey), смогла обеспечить следующие потребности рассматриваемой рекомендательной системы [4]:
- горизонтальное масштабирование;
- поддержка репликации;
- отказоустойчивость и надежность;
- низкая временная задержка (low latency) обработки данных с возможностью проведения операций практически в режиме онлайн;
- возможность управлять согласованностью распределенных данных;
- загрузка пакетных и потоковые данных из Crunch и Storm соответственно;
- широкий набор схем данных для разных вариантов использования, в частности, метаданных для множества различных объектов, что позволило бы сократить эксплуатационные расходы.
Также стоит отметить возможности Cassandra для массового импорта информации из других источников данных, в частности, HDFS, путем создания сохраненных таблиц (SSTable) и последующей потоковой передачи их в кластер. Это намного проще, быстрее и эффективнее, чем отправка множества отдельных операторов INSERT для всех данных, которые нужно загрузить в Кассандру [4].
По результатам тестирования описанного Big Data проекта Apache Cassandra показала высокую скорость обработки и надежность хранения данных, благодаря чему была успешно внедрена в production-версию разработанной системы персональных рекомендаций стримингового сервиса Spotify.
В следующей статье мы рассмотрим, чем отличается Apache Cassandra от другой популярной NoSQL-СУБД для Big Data, HBase, и что общего между этими нереляционными системами. А о примере использования технологий Big Data в Spotify для анализа пользовательских сеансов читайте здесь.
Научитесь разрабатывать распределенные приложения потоковой аналитики больших данных с Apache Kafka и Spark на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для разработчиков
- Основы Apache Spark для разработчиков
- Потоковая обработка в Apache Spark
- Анализ данных с Apache Spark
Источники
- https://ru.wikipedia.org/wiki/Spotify
- https://habr.com/ru/company/lanit/blog/420499/
- https://ru.wikipedia.org/wiki/Рекомендательная_система
- https://labs.spotify.com/2015/01/09/personalization-at-spotify-using-cassandra/
- https://crunch.apache.org/
- https://hackernoon.com/spotifys-discover-weekly-how-machine-learning-finds-your-new-music-19a41ab76efe

