 992
992 
Содержание
Hbase — это нереляционная распределенная система управления базами данных (СУБД) с открытым исходным кодом, написанная на языке Java. Hbase является проектом экосистемы Hadoop и работает поверх распределенной файловой системы HDFS (Hadoop Distributed File System) [1].
Что такое Apache Hbase: основные особенности архитектуры
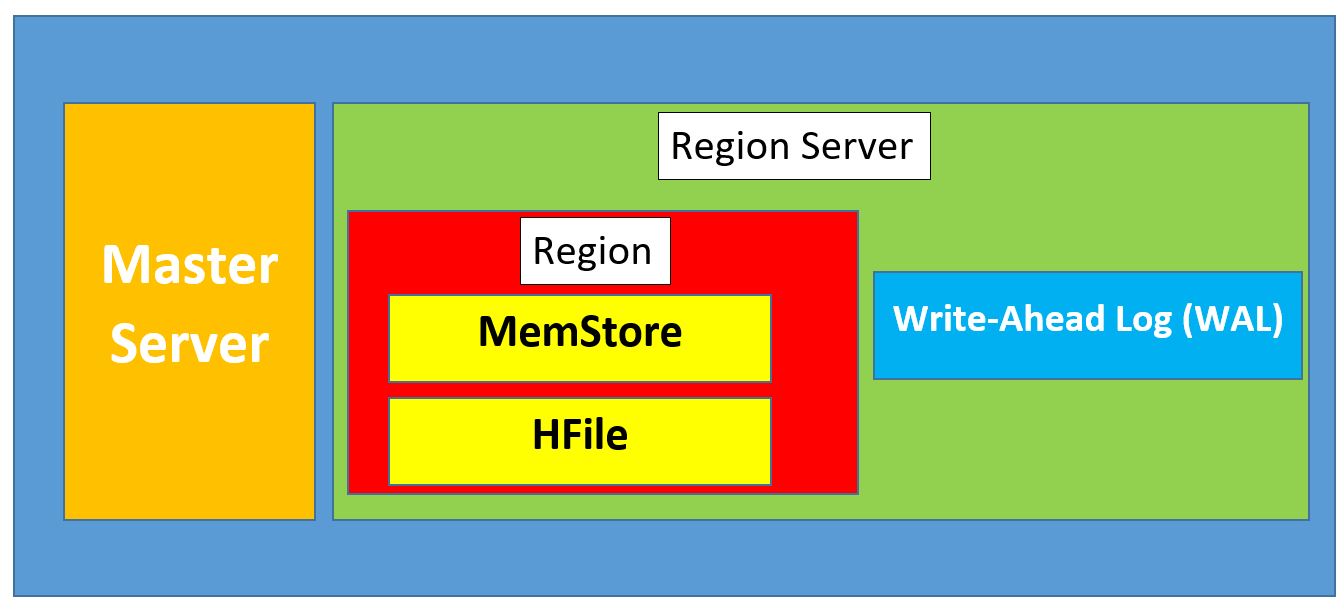
Hbase — это распределенная СУБД класса NoSQL, которая обеспечивает BigTable-подобные возможности для Hadoop (для работы с большими массивами данных) и, следовательно, обеспечивает отказоустойчивый способ хранения больших объемов данных. Архитектура hbase представлена следующими основными компонентами:
- Region Server (RS) — это сервер, который обслуживает один или несколько регионов. Регион — это диапазон записей, соответствующих определенному диапазону подряд идущих строковых ключей (RowKey). В состав каждого региона входят следующие компоненты:
- Persistent Storage (PS) — это основное хранилище данных в СУБД hbase. Данные PS хранятся на HDFS в специальном формате Hfile, который отвечает за их хранение в отсортированном порядке по RowKey.
- MemStore — область памяти, выделяемая для кратковременного хранения данных перед их записью в HFile.
- BlockCache — это специальный кэш, отвечающий за ускоренное чтение часто используемых данных.
- WriteAheadLog (WAL) — это специальный файл для логгирования всех манипуляций с данными для возможности восстановления всех изменений в случае сбоя.
- MasterServer — это главный сервер в кластере hbase, который управляет распределением регионов по RS (например, ведение реестров регионов или управление запуском регулярных задач).
Так как данные по одному региону могут храниться в нескольких HFile-файлах, то для ускорения работы hbase объединяет их. Эта операция носит название compaction (уплотнение). Уплотнение бывает двух видов:
- Minor Compaction — выполняется в фоновом режиме и имеет низкий приоритет по сравнению с другими операциями.
- Major Compaction — запускается по срабатыванию триггеров (при наступлении определенных событий). Имеет высокий приоритет и может существенно замедлить работу кластера. Major Compaction рекомендуется выполнять только в том случае, когда нагрузка на кластер небольшая [1].
Как появилась HBase: краткая история
Проект hbase начал разрабатываться в 2006 году Чедом Уолтерсом и Джимом Келерманом из компании Powerset, которая нуждалась в обработке больших объемов данных для создания поисковой системы на естественном языке. Первая версия hbase была включена в Hadoop 0.15.0 в октябре 2007 года. В мае 2010 года система перешла в категорию проектов верхнего уровня фонда Apache. В 2015 году вышла версия hbase 1.0. Последняя версия hbase 2.3.4 вышла 22 января 2021 года [2].
Начало работы с HBase
Основной структурой для работы с данными в hbase является таблица. Для создания таблиц hbase использует команду create:
create 'emp', 'personal data', 'professional data'
Для того, чтобы вставить данные в созданную таблицу, используется hbase-команда put:
put 'emp','1','personal data:name','raju' put 'emp','1','personal data:city','hyderabad' put 'emp','1','professional data:salary','50000'
Таблицы в hbase также можно создавать, используя Java API (Application Program Interface). За это отвечает Java-класс HBaseAdmin, который в конструктор принимает параметр конфигурации класса Configuration:
Configuration conf = HBaseConfiguration.create(); HBaseAdmin admin = new HBaseAdmin(conf);
Для создания таблицы необходимо также определить дескриптор для семейства столбцов (для возможности добавления новых столбцов), а также дескриптор самой таблицы, содержащий ее название:
//дескриптор таблицы
HTableDescriptor table = new HTableDescriptor(toBytes("Table name"));
//дескриптор семейства столбцов
HColumnDescriptor family = new HColumnDescriptor(toBytes("column family"));
//добавление столбцов в созданный объект таблицы
table.addFamily(family);
Для завершения создания таблицы необходимо вызвать метод createTable() [3]:
admin.createTable(table);
Таким образом, благодаря своей архитектуре, hbase может вести обработку Big Data в распределенной среде без потерь и с весьма высокой скоростью. Именно поэтому hbase является неотъемлемой частью экосистемы Hadoop, являющейся универсальным решением для организации обработки Big Data.
Больше подробностей про Apache Hbase смотрите здесь.
Источники