 1253
1253 
Содержание
Cloudera Impala – далеко не единственное SQL-решение для быстрой обработки больших данных (Big Data), хранящихся в среде Hadoop. C Impala часто сравнивают Apache Hive, однако они существенно отличаются в плане прикладного использования, как мы уже показали здесь. Гораздо ближе к Impala с точки зрения вычислительной модели и сценариев использования (use cases) стоит Apache Drill. Что общего между этими SQL-инструментами стека Big Data и чем они отличаются, читайте в нашей сегодняшней статье.
Что такое Apache Drill и как он работает
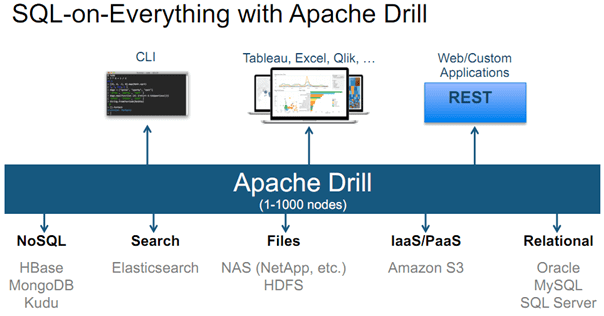
Drill – это проект верхнего уровня фонда Apache Software Foundation, фреймворк с открытым исходным кодом, который поддерживает высоконагруженные распределенные приложения с интерактивной SQL-аналитикой больших объемов данных. Apache Drill представляет собой версию системы Dremel от Google с открытым исходным кодом, которая доступна в качестве инфраструктурного сервиса под названием Google BigQuery. Drill может масштабироваться до 10 000 серверов или более, обрабатывая петабайты данных и триллионы записей в считанные секунды [1].
Отличительными особенностями Apache Drill считаются следующие [2]:
- динамическое вычисление схемы данных на лету, в процессе исполнения SQL-запроса. Не требуется определять схему данных или спецификацию формата хранения заранее. Поскольку некоторые форматы (Parquet, JSON, AVRO) и NoSQL базы данных уже содержат описание формата внутри себя, Drill вычисляет это динамически, начиная обработку данных в процессе записи и определяя схему во время обработки SQL-запроса.
- При этом учтена возможность изменения схемы данных – многие команды могут быть переконфигурированы в этом случае.
- отсутствие централизованной системы хранения метаданных, например, Hive Metastore, в отличие от Cloudera Impala и Apache Hive. Для Drill метаданные доставляется от плагинов, передающих запрос хранилищу. При этом возможно делать SQL-запросы к нескольким разным узлам, собирая таким образом информацию из разных источников (баз данных или файлов).
- поддержка множества нереляционных баз данных и файловых систем – не только Apache Hadoop (HBase, HDFS), но и MongoDB, MapR-DB, MapR-FS, Amazon S3, Azure Blob Storage, Google Cloud Storage, Swift, NAS, а также локальные файлы. Один запрос может включать данные из нескольких хранилищ. В частности, можно объединить информацию о пользователях в MongoDB с каталогом журнала событий из Hadoop.
С архитектурной точки зрения Drill предоставляет собой гибкую иерархическую модель столбчатых данных в виде сложных, динамично развивающихся и изменяющихся модели. Реляционные данные в Drill рассматриваются как особый (упрощенный) случай сложных данных. Таким образом, Дрилл позволяет получить доступ к вложенным атрибутам данных, как к столбцам обычной реляционной таблицы, предоставляя интуитивно понятные расширения, что значительно упрощает работу с информационными массивами.
Архитектура Drill расширяется на каждом уровне: плагин хранения, оптимизация и выполнение SQL-запросов и API-клиента. Для поиска, загрузки плагинов и добавления дополнительных модулей, функций и операторов хранения с минимальной конфигурацией организовано сканирование классов [2].
С позиции разработчика Big Data ключевыми преимуществами Apache Drill является поддержка промышленных API (ANSI SQL, ODBC/JDBC, REST), криптографии и формата PCAP, возможность расширения с помощью собственных плагинов и определяемых пользователем функций (UDF, User Defined Functions), а также соответствие концепции локальности данных, когда информация для обработки и сам вычислительный движок расположены на одном узле [1].
Что общего между Дрилл и Импала и чем они отличаются
Прежде всего отметим, чем похожи Apache Drill и Cloudera Impala:
- оба продукта основаны на архитектуре MPP (Massively Parallel Processing), которая отличается от вычислительной модели MapReduce, используемой в Apache Hive, высокой скоростью исполнения и возможностью распараллеливания операций;
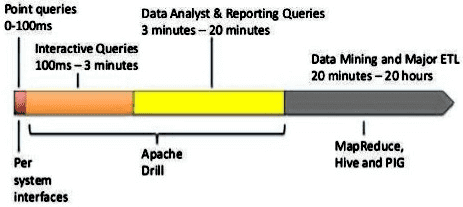
- постоянная работа системных служб (демонов) и кэширование данных в памяти позволяет ускорить время выполнения SQL-запросов, обеспечивая интерактивные вычисления, в отличие от Apache Hive;
- аналогичные распределенные механизмы компиляции программного кода, оптимизированные, в первую очередь, для столбцовых форматов хранения данных, таких как Parquet.
С прикладной точки зрения для Дрилл и Impala характерны высокая скорость и интерактивность выполнения SQL-запросов к данным, хранящимся в среде Hadoop. Однако, стоит выделить 2 существенных отличия этих SQL-инструментов [3]:
- Impala необходимо централизованное хранилище метаданных (Hive Metastore) для определения схемы и форматов хранения данных, тогда как Drill вычисляет схему динамически при выполнении SQL-запроса, получая метаданные на лету от плагинов, передающих запрос различным источникам данных;
- Impala относится к стеку инструментов SQL-on-Hadoop, предназначенному, в первую очередь, для работы с данными в этой среде, тогда как Drill позиционируется как SQL-средство для любых хранилищ – распределенных и локальных нереляционных баз данных и файловых систем, позволяющее объединять информацию от разных источников.
Apache Drill vs Cloudera Impala: что выбирать для практического использования
На практике оба этих SQL-средства для интерактивной аналитики больших данных активно используются в различных Big Data проектах. О некоторых примерах реального применения Cloudera Impala мы рассказывали здесь. Apache Drill также не только помогает аналитикам и ученым по данным (Data Analyst, Data Scientist) работать с большими объемами неструктурированной информации, но и используется в различных бизнес-приложениях по всему миру.
Например, Ericsson, шведский производитель телекоммуникационного оборудования, использует Дрилл для интерактивной аналитики активности беспроводных сетей на своих устройствах и предоставления отчетов разным провайдерам об их использовании. В Intuit, американской компании по разработке программного обеспечения для бизнеса и финансов, Apache Drill применяется для анализа и генерации отчетов по топикам Kafka. При этом главным достоинством Drill является поддержка объединенного типа данных для потока кликов в формате JSON. RedBus, крупнейшая в Индии онлайн-платформа для продажи автобусных билетов, использует API-интерфейсы REST Apache Drill для запросов и выполнения ETL-потоков из различных хранилищ данных Mongo, Kafka и S3 [4].
Таким образом, благодаря способности Apache Drill интерактивно работать с разными форматами и источниками данных без предварительного определения схемы и форматов, этот SQL-инструмент можно назвать идеальным решением для аналитики больших объемов необработанной (сырой) информации в режиме онлайн. Возможность объединения данных из нескольких хранилищ в уникальный SQL-запрос делает интеграцию разнородных источников информации простой и быстрой. Поэтому Дрилл широко используется в аналитике больших данных различных Data Science приложениях. В тоже время, на практике большинство метаданных уже определено, что позволяет эффективно работать с ними с помощью Impala. Таким образом, Дрилл больше подходит для исследовательских задач и визуализации данных, тогда как Impala – для стандартных отчетов BI (Business Intelligence). При выборе Apache Drill vs Cloudera Impala стоит учитывать особенности конкретного варианта использования: типы, форматы, источники и конфигурации исходных данных, поскольку именно эти факторы в конечном счете оказывают глубокое влияние на оперативность процесса бизнес-аналитики и производительность запросов [3].
В следующей статье мы поговорим про другой SQL-инструмент обработки Big Data — Apache Phoenix. Все подробности аналитики больших данных рассматриваются на наших практических курсах в лицензированном учебном центре обучения и повышения квалификации ИТ-специалистов (менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data) в Москве:
- BDAM: Аналитика больших данных для руководителей
- HIVE: Hadoop SQL администратор Hive
- IMPA: Cloudera Impala Data Analytics
Источники

