 628
628 
Содержание
Что такое дополнительный выходной поток DataStream в Apache Flink, зачем это нужно, чем механизм SideOutput лучше операторов filter и split, а также как его использовать: примеры на Python.
Что такое дополнительный выходной поток DataStream в Apache Flink и зачем это нужно
Хотя выходные результаты большинства операторов API DataStream в Apache Flink представляют собой единый поток одинакового типа данных, его можно разделить на несколько потоков, причем разных типов данных. Этот механизм под названием SideOutput доступна с версии 1.9. Дополнительные или побочные выходы определяются как объект OutputTag[X], где X — тип данных выходного потока. Функция процесса выдает событие на один или несколько побочных выходов через объект Context. Это полезно, когда нужно обрабатывать и маршрутизировать данные разными способами в зависимости от условий. Например, необходимо разделить поток заказов в соответствии с ожидаемой суммой или разделить пользовательские логи в соответствии с геолокацией и пр.
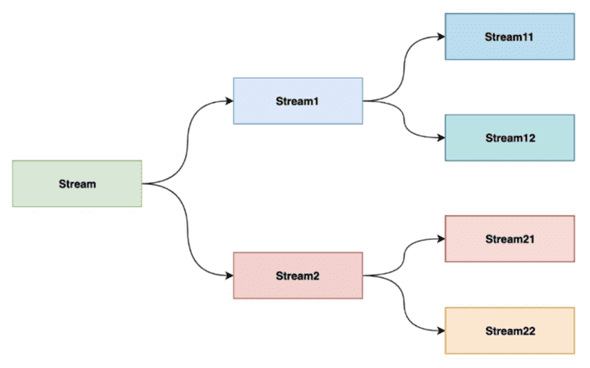
В отличие от оператора filter(), который используется для фильтрации потоковых данных по заданным пользователем условиям, SideOutput() может разделить поток несколько раз, не беспокоясь об исключениях. Это утилизирует ресурсы кластера Flink более эффективно. Также SideOutput() проще в использовании, чем метод split() для разделения потока. В случае split() нужно определить OutputSelector в операторе split, затем переписать в нем метод select, отметить различные типы данных и, наконец, использовать select() на возвращенном splitStream для преобразования соответствующих данных в выбранные.
Чтобы отправить данные в SideOutput(), используется специальный объект OutputTag. Он служит меткой для данных, которые должны быть перенаправлены в дополнительный поток. Для этого внутри функции (ProcessFunction, KeyedProcessFunction, CoProcessFunction, KeyedCoProcessFunction, ProcessWindowFunction, ProcessAllWindowFunction) нужно использовать метод Context.output(OutputTag, value). Это позволит отправить данные в дополнительный, а не в основной поток. Например, на Python это выглядит так:
output_tag = OutputTag("side-output", Types.STRING())
После того как данные были отправлены в дополнительный поток, их можно извлечь в дальнейшем шаге обработки. Для этого используется метод DataStream.getSideOutput(OutputTag).
side_output_stream = main_data_stream.get_side_output(output_tag)
Если этого явно не сделать, то результат побочного выходного потока будет выведен в основной, что может привести к сбою задания, когда типы данных отличаются.
Таким образом, в дополнение к основному потоку, который получается в результате операций с DataStream, можно создать любое количество дополнительных выходных потоков. Тип данных в потоках результатов не обязательно должен совпадать с типом данных в основном потоке, и типы различных побочных выходов также могут отличаться. Эта полезно, когда надо разделить поток данных без его репликации и сложных фильтров.
Познакомившись с тем, что такое дополнительный выходной поток DataStream, далее рассмотрим небольшой пример на Python.
Пример использования функции side output
Следующий код выполняет задачу обработки потока данных в Apache Flink. Сгенерируем поток заявок от клиентов (физических или юридических лиц) с помощью Python-библиотеки Faker. Разделение по побочным потокам будет происходить в зависимости от того типа клиента: физлицо или юрлицо.
from pyflink.datastream import StreamExecutionEnvironment
from pyflink.datastream.functions import ProcessFunction
from pyflink.datastream import OutputTag
from pyflink.common.typeinfo import Types
from faker import Faker
import random
# Определение тегов для side outputs
physical_person_tag = OutputTag('physical_persons', Types.PICKLED_BYTE_ARRAY())
legal_entity_tag = OutputTag('legal_entities', Types.PICKLED_BYTE_ARRAY())
# Определение функции обработки
class SplitClientType(ProcessFunction):
def process_element(self, value, ctx):
if 'company' in value:
# Отправляем юридические лица в legal_entity_tag
ctx.output(legal_entity_tag, value)
else:
# Отправляем физических лиц в physical_person_tag
ctx.output(physical_person_tag, value)
# Отправляем всё в основной поток для демонстрации
yield value
# Создание среды выполнения
env = StreamExecutionEnvironment.get_execution_environment()
# Создание функции генерации заявок
def generate_requests(num_requests):
fake = Faker()
requests = []
for _ in range(num_requests):
if random.choice([True, False]):
requests.append({'person': fake.name()})
else:
requests.append({'company': fake.company()})
return requests
# Создание исходного потока данных
input_data = env.from_collection(generate_requests(10))
# Применение функции обработки с side outputs
main_stream = input_data.process(SplitClientType(), output_type=Types.PICKLED_BYTE_ARRAY())
# Получение side outputs
physical_persons_stream = main_stream.get_side_output(physical_person_tag)
legal_entities_stream = main_stream.get_side_output(legal_entity_tag)
# Печать результатов на консоль
main_stream.print("Main Stream")
physical_persons_stream.print("Physical Persons")
legal_entities_stream.print("Legal Entities")
# Запуск Flink приложения
env.execute("Side Output Example")
В этом примере создается 2 тега для побочных выходов (OutputTag): для физических лиц (physical_person_tag) и для юридических лиц (legal_entity_tag). Класс SplitClientType наследует ProcessFunction и реализует метод process_element, который обрабатывает каждый элемент потока. Если в элементе есть ключ company, то он отправляется в поток для юридических лиц. В противном случае, элемент отправляется в поток для физических лиц. При этом элемент также отправляется в основной поток. Функция generate_requests() создает список фейковых заявок, каждая из которых отправлена физическом лицом с ключом person или юридическим лицом с ключом company. К исходному потоку данных применяется функция обработки SplitClientType, которая разделяет поток на side outputs и основной поток. Из основного потока извлекаются side outputs для физических и юридических лиц.
Таким образом, механизм SideOutput позволяет разделить логику обработки различных типов данных, делая код более управляемым. Обработка различных типов данных в отдельных потоках может улучшить производительность приложения Apache Flink благодаря возможности применять разные оптимизации и ресурсы для каждого потока. Код становится более гибким за счет модульности. Например, можно легко изменить или расширить обработку side output потоков без необходимости изменения основного потока. Наконец, побочные выходы можно использовать для обработки и логирования ошибок или аномальных данных, отделяя их от основного потока обработки. Таким образом, side outputs в Apache Flink обеспечивают мощный механизм для создания сложных и производительных приложений потоковой обработки данных.
Узнайте больше про возможности Apache Flink для пакетной и потоковой аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

