 1081
1081 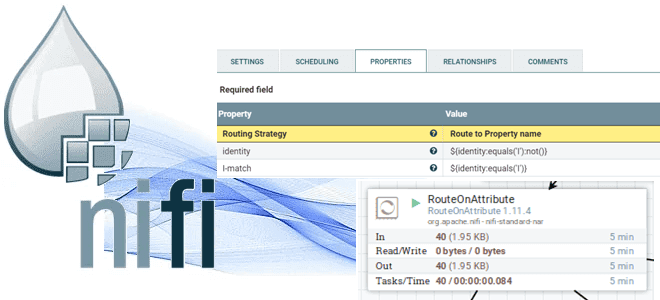
Содержание
Что такое атрибуты FlowFile, какие процессоры есть в Apache NiFi для работы с ними и как маршрутизировать поток данных на основе пользовательских свойств.
Атрибуты FlowFile и процессоры для работы с ними
Основной единицей данных, которая перемещается через систему в Apache NiFi является FlowFile. Он представляет собой контейнер для данных и метаданных, которые используются для обработки и маршрутизации в конвейерах потоках. Каждый FlowFile состоит из двух главных компонентов:
- контент – данные, которые FlowFile содержит;
- атрибуты — метаданные, которые описывают FlowFile, такие как уникальный идентификатор, размер и путь к файлу, а также пользовательские поля, которые могут быть добавлены в процессе обработки для передачи дополнительной информации.
Атрибуты представляют собой пары ключ-значение, которые связаны с пользовательскими данными. Каждый FlowFile создается с несколькими атрибутами, которые меняются в течение его жизненного цикла, позволяя маршрутизировать FlowFile по конвейеру обработки данных с помощью RouteOnAttribute и других подобных процессоров.
Также атрибуты используются для настройки процессоров. Например, процессор PutFile может использовать атрибуты, чтобы знать, где хранить каждый FlowFile, поскольку атрибуты каталога и имени файла могут быть разными для каждого FlowFile. Наконец, атрибуты предоставляют чрезвычайно контекст о данных, включая происхождение FlowFile.
Каждый FlowFile имеет минимальный набор атрибутов:
- filename — имя файла, которое можно использовать для хранения данных в локальной или удаленной файловой системе;
- path— имя каталога, который можно использовать для хранения данных в локальной или удаленной файловой системе;
- uuid— универсальный уникальный идентификатор, который отличает FlowFile от других;
- entryDate— дата и время, когда FlowFile поступил в систему, т.е. был создан. Значение этого атрибута — число, представляющее количество миллисекунд с полуночи 1 января 1970 года (UTC).
- lineageStartDate— каждый раз, когда FlowFile клонируется, объединяется или разделяется, это приводит к созданию дочернего FlowFile. По мере того, как эти дочерние элементы затем клонируются, объединяются или разделяются, выстраивается цепочка происхождения. Это значение представляет дату и время, когда исходный FlowFile-предок вошел в систему. По сути, этот атрибут представляет задержку FlowFile. Значение представляет собой число, которое представляет количество миллисекунд с полуночи 1 января 1970 года (UTC).
- fileSize— количество байтов, занимаемых содержимым FlowFile.
Атрибуты uuid, entryDate, lineageStartDate и fileSize генерируются системой и не могут быть изменены.
Для работы с атрибутами в NiFi есть несколько соответствующих процессоров, которые позволяют извлечь значения метаданных FlowFile:
- EvaluateJsonPath— процессор для работы с JSON документами, который позволяет извлекать значения из JSON, используя выражения JSONPath, чтобы обращаться к элементам JSON по их структуре. С помощью этого процессора можно извлекать конкретные значения, создавать атрибуты на основе этих значений и даже фильтровать данные по определённым критериям, чтобы либо заменить содержимое FlowFile, либо извлечь значение в атрибут, заданный пользователем.
- EvaluateXPath— процессор для работы с XML документами. Он использует язык запросов XPath, который позволяет извлекать и манипулировать данными в формате XML, чтобы извлекать значения из XML, создавать атрибуты и направлять поток данных на основе результата выполнения XPath-выражений, заменить содержимое FlowFile или извлечь значение в атрибут, заданный пользователем.
- EvaluateXQuery— процессор также используется для работы с XML документами, но в отличие от EvaluateXPath, он использует мощный и гибкий язык XQuery. XQuery позволяет выполнять более сложные операции, такие как преобразование структуры данных, фильтрация и агрегация. Процессор EvaluateXQuery позволяет выполнять сложные запросы к XML-данным и возвращать результаты в требуемом формате.
- ExtractText – процессор для сравнения заданных пользователем регулярных выражений с текстовым содержимым FlowFile и извлечения значений, которые добавляются в качестве именованных пользователем атрибутов.
- HashAttribute– процессор, который выполняет функцию хеширования для конкатенации определенного пользователем списка существующих атрибутов.
- HashContent– процессор, который выполняет функцию хеширования содержимого FlowFile и добавляет значение хеш-функции в качестве атрибута.
- IdentifyMimeType– процессор, который оценивает содержимое FlowFile, чтобы определить, какой тип файла инкапсулирует FlowFile. Этот процессор способен обнаруживать множество различных типов MIME, таких как изображения, документы текстового процессора, текст и форматы сжатия, и это лишь некоторые из них.
- UpdateAttribute– процессор, который добавляет или обновляет любое количество определяемых пользователем атрибутов в FlowFile. Это полезно для добавления статически настроенных значений, а также для динамического получения значений атрибутов с помощью языка выражений. Этот процессор также позволяет обновлять атрибуты условно, на основе правил, предоставленных пользователем.
Как уже было отмечено ранее, именно процессор UpdateAttribute позволяет дата-инженеру добавлять свои собственные атрибуты к каждому FlowFile в определенном месте потока, добавив в GUI свойство и задав ему значение. Для каждого FlowFile, обрабатываемого процессором UpdateAttribute, добавляется атрибут для каждого определяемого пользователем свойства. Имя атрибута будет таким же, как имя добавленного свойства. Значение атрибута будет таким же, как значение свойства. Значение свойства может также содержать язык выражений, чтобы изменять или добавлять атрибуты на основе других атрибутов.
Также процессор UpdateAttribute имеет расширенный пользовательский интерфейс, который позволяет пользователю настраивать набор правил, для которых атрибуты должны быть добавлены. В этом пользовательском интерфейсе пользователь может настраивать механизм правил, указывая правила, которые должны совпадать, чтобы настроенные атрибуты были добавлены в FlowFile.
Пример маршрутизации потока данных в NiFi на основе атрибутов
Одной из самых мощных функций NiFi является возможность маршрутизации FlowFiles на основе их атрибутов. Основным механизмом для этого является процессор RouteOnAttribute. Этот процессор, как и UpdateAttribute, настраивается в диалоговом окне конфигурации процессора путем добавления определяемых пользователем свойств. Атрибуты каждого FlowFile будут сравниваться с настроенными свойствами, чтобы определить, соответствует ли FlowFile указанным критериям. Ожидается, что значение каждого свойства будет выражением специального языка выражений и вернет логическое значение.
После оценки выражений языка выражений, предоставленных в отношении атрибутов FlowFile, процессор определяет, как маршрутизировать FlowFile на основе выбранной стратегии маршрутизации. Наиболее распространенной стратегией является стратегия маршрутизации по имени свойства (Route to Property name). При выборе этой стратегии процессор выставит связь для каждого настроенного свойства. Если атрибуты FlowFile удовлетворяют заданному выражению, копия FlowFile будет направлена в соответствующую связь. Например, если есть новое свойство с именем «begins-with-r» и значением «${filename:startsWith(\’r’)}», то любой FlowFile, имя файла которого начинается с буквы «r», будет направлен в эту связь. Все остальные FlowFile будут направлены в отношение unmatched.
Язык выражений NiFi позволяет получать доступ к значениям атрибутов FlowFile и управлять ими при настройке потоков обработки данных. Для свойств, которые поддерживают язык выражений, он используется путем добавления выражения в фигурные скобки. Выражение может быть таким же простым, как имя атрибута. Например, чтобы сослаться на атрибут uuid, можно просто использовать значение ${uuid}. Если имя атрибута начинается с любого символа, отличного от буквы, или если оно содержит символ, отличный от цифры, буквы, точки (.) или подчеркивания (_), имя атрибута необходимо будет заключить в кавычки. Например, ${My Attribute Name} будет недопустимым, но ${‘My Attribute Name’} будет ссылаться на атрибут My Attribute Name. Помимо ссылок на значения атрибутов, можно выполнять ряд функций и сравнений с этими атрибутами. Например, если надо проверить, содержит ли атрибут filename букву «r» без учета регистра, это можно сделать с помощью выражения ${filename:toLower():contains(‘r’)}.
Функции разделены двоеточиями. Можно объединить любое количество функций для создания более сложных выражений и встроить одно выражение в другое. Например, если нужно сравнить значение атрибута attr1 со значением атрибута attr2, можно сделать это с помощью следующего выражения: ${attr1:equals( ${attr2} )}. Язык выражений NiFi содержит множество различных функций, которые можно использовать для выполнения задач, необходимых для маршрутизации и манипулирования атрибутами. Существуют функции для разбора и манипулирования строками, сравнения строковых и числовых значений, манипулирования и замены значений и сравнения значений.
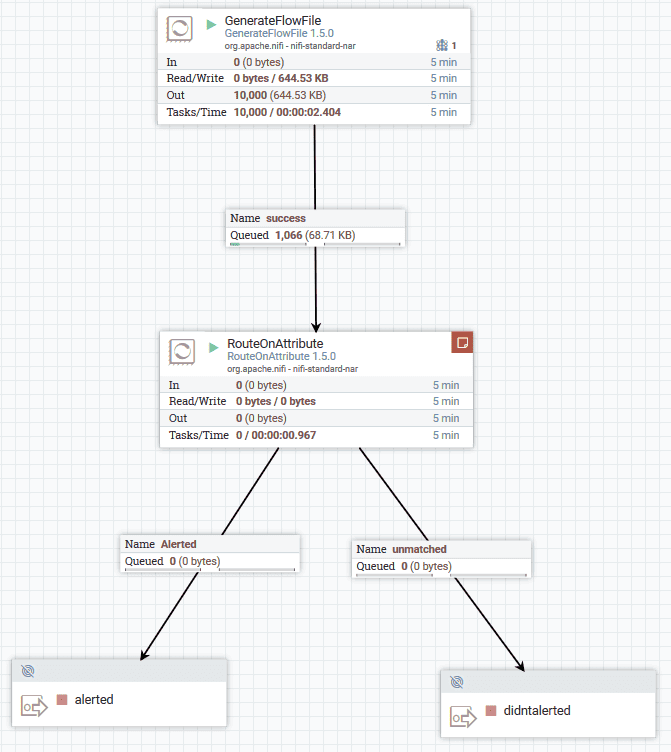
Чтобы продемонстрировать, как используется процессор RouteOnAttribute для маршрутизации потока данных, рассмотрим небольшой пример. Предположим, поток данных содержит информацию о заказах. Каждый FlowFile имеет пользовательский атрибут orderType, который может принимать значения digital или physical. Нужно маршрутизировать заказы на цифровые и физические продукты в разные потоки для дальнейшей обработки.
Для этого следует добавить процессор RouteOnAttribute на холст Apache NiFi. В настройках процессора надо добавить два новых свойства:
- digitalRoute: ${orderType:equals(«digital»)}
- physicalRoute: ${orderType:equals(«physical»)}
Наконец, надо связать выходы процессора RouteOnAttribute с другими процессорами или выходами для дальнейшей обработки. Например, из связи digitalRoute направить FlowFile в процессор для обработки цифровых заказов, а из связи physicalRoute – в процессор для обработки физических заказов.
Таким образом, с помощью процессора RouteOnAttribute можно гибко управлять потоками данных в зависимости от значений атрибутов FlowFile, чтобы реализовать сложные сценарии маршрутизации данных в рамках Apache NiFi. Чем это отличается от маршрутизации на основе содержимого, читайте в нашей новой статье.
Узнайте больше про администрирование и использование Apache NiFi для построения эффективных ETL-конвейеров потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

