 1012
1012 
Зачем в Apache Flink 1.20 добавлена новая функция восстановления пакетных заданий после сбоя JobMaster, как она работает и какие параметры надо настроить для повышения ее эффективности.
Восстановление пакетных заданий Flink после сбоя JobMaster
Как и любой фреймворк стека Big Data, Apache Flink включает множество компонентов, каждый из которых выполняет конкретную функцию обеспечения доступности и/или согласованности распределенной обработки больших данных. В частности, за управление выполнением пакетных и потоковых заданий отвечает мастер или диспетчер заданий (JobMaster). В кластере Flink одновременно могут выполняться несколько заданий, каждым из которых управляет как минимум один отдельный JobMaster. В режиме высокой доступности может быть несколько диспетчеров заданий, один из которых всегда является лидером, а остальные находятся в режиме ожидания.
До версии Flink 1.20, если JobMaster сталкивался с ошибкой и прекращал работать, задание не выполнялось, если режим высокой доступности отключен. При включенном режиме высокой доступности JobMaster автоматически перезапускался. В этом случае потоковые задания восстанавливались с последней успешной контрольной точки. Но пакетные задания, не имеющие механизма контрольных точек, теряли свое состояние и начинались с самого начала. В случае длительных пакетных заданий это довольно сильно снижало общую производительность обработки данных. Поэтому начиная с версии 1.20, о которой мы писали здесь, в Apache Flink добавлена функция восстановления прогресса для пакетных заданий после сбоя JobMaster без повторного запуска завершенных задач.
Для реализации этой функции введен компонент JobEventStore. Он обеспечивает запись событий изменения состояния JobMaster, таких как ExecutionGraph, OperatorCoordinator и пр. во внешнюю файловую систему. Во время сбоя и последующего перезапуска диспетчера заданий JobMaster менеджеры задач (TaskManager) сохранят промежуточные данные результатов, созданные заданием, и будут непрерывно переподключаться. После перезапуска JobMaster он восстановит соединения с менеджерами задач и восстановит состояние задания на основе сохраненных промежуточных результатов и событий, ранее записанных в JobEventStore. Таким образом, весь ход выполнения пакетного задания будет восстановлен.
Однако, при этом может возникнуть рассинхронизация между записанными и восстановленными результатами. Например, если некоторые менеджеры задач неожиданно потерпят сбой во время выполнения, промежуточные результаты станут недоступными. Поэтому Flink также необходимо получить информацию о промежуточных результатах из менеджеров задач и службы удаленного обмена данными между узлами распределенной системы (Remote Shuffle Service, RSS) для повторной калибровки результатов восстановления хода выполнения задания. Подробнее об RSS читайте в нашей новой статье.
Во время выполнения задания JobEventStore получает и записывает во внешнюю файловую систему следующие события изменения состояния JobMaster:
- оптимизация адаптивного плана выполнения пакетных заданий на основе результатов выполнения вышестоящего уровня. Поскольку каждый процесс восстановления основан на результатах выполнения вышестоящего уровня, их запись необходима для планирования задач и отказоустойчивости.
- информация о выполненных задачах, чтобы избежать их повторного выполнения;
- состояние OperatorCoordinator, который отвечает за координацию операторов и обеспечение связи между ними. Его состояние тесно связано с согласованностью данных. Например, SourceCoordinator содержит информацию о том, какие исходные разделы были обработаны.
- состояние ShuffleMaster, который в RSS отвечает за метаданные данных для shuffle-операций. Чтобы новый диспетчер заданий мог повторно использовать эти промежуточные результаты, необходимо восстановить состояние Shuffle Master.
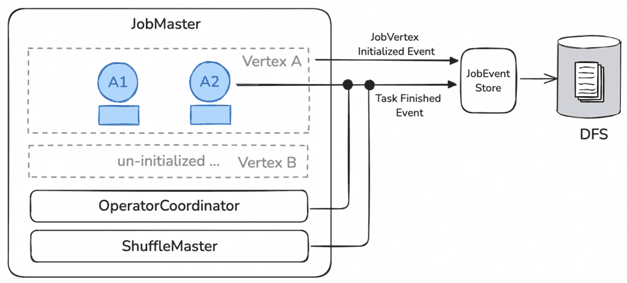
Во время выполнения пакетных заданий Flink сохраняет промежуточные результаты в менеджерах задач и RSS-службе удаленного обмена данными во время выполнения. Когда происходит аварийное переключение диспетчера заданий, менеджеры задач и RSS сохраняют промежуточные результаты, связанные с заданием, и постоянно пытаются повторно подключиться к JobMaster. После настройки нового диспетчера заданий менеджеры задач и RSS восстановят свои соединения с JobMaster, а затем сообщат данные о своих промежуточных результатах.
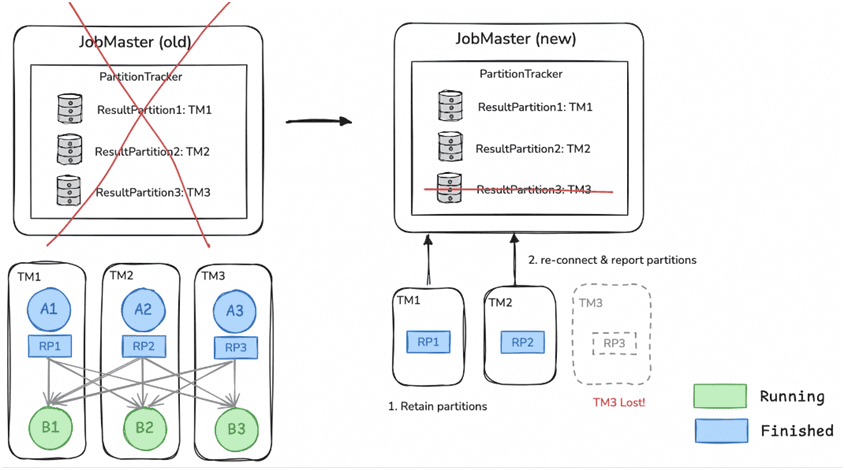
После перезапуска JobMaster восстановит соединения с менеджерами задач и RSS-службой, используя события, записанные в JobEventStore, и на основе промежуточных результатов восстановит ход выполнения задания. Сначала диспетчер заданий будет использовать события, хранящиеся в JobEventStore, для восстановления состояний выполнения каждого оператора в задании. Затем, основываясь на состоянии OperatorCoordinator, JobMaster восстановит необработанные исходные данные, чтобы избежать потери или дублирования данных. Впоследствии диспетчер заданий будет дополнительно корректировать ход выполнения на основе доступных промежуточных результатов, сообщаемых менеджерами задач и RSS-службой. Если какой-либо раздел промежуточного результата потерян, но все еще необходим для нижестоящих задач, задача продюсера будет сброшена и выполнена повторно. Наконец, выполнение задания продолжится с восстановленного прогресса.
Настройки и оптимизации
Чтобы использовать функцию восстановления состояния пакетных заданий Flink, необходимо включить режим высокой доступности кластера и установить конфигурацию execution.batch.job-recovery.enabled в значение true. Все новые источники данных в Apache Flink 1.20 поддерживают восстановление прогресса для пакетных заданий, реализуя интерфейс SupportsBatchSnapshot для SplitEnumerator. Без этого задачи источника должны будут перезапускаться после сбоя JobMaster, если не завершен весь исходный этап. В настоящее время FileSource и HiveSource уже реализовали этот интерфейс.
В заключение отметим, что в настоящее время только адаптивный пакетный планировщик (Adaptive Batch Scheduler) поддерживает функцию восстановления состояния пакетных заданий. Впрочем, это используется по умолчанию, если явно не настроен другой планировщик.
Для повышения эффективности восстановления состояния пакетных заданий после сбоя JobMaster, чтобы избежать повторного запуска уже завершенных задач, можно настроить следующие параметры оптимизации:
- batch.job-recovery.snapshot.min-pause – минимальное время паузы, разрешенное между моментальными снимками для OperatorCoordinator и ShuffleMaster. Этот параметр можно настроить на основе ожидаемой нагрузки ввода-вывода кластера Flink и допустимого количества регрессии состояния. Рекомендуется уменьшить этот интервал, если предпочтительны меньшие регрессии состояния и приемлема более высокая нагрузка ввода-вывода.
- batch.job-recovery.previous-worker.recovery.timeout – длительность тайм-аута, разрешенного для рабочих процессов перемешивания данных при повторном подключении. В процессе восстановления Flink запрашивает сохраненную информацию о промежуточных результатах у Shuffle Master. Если тайм-аут достигнут, Flink будет использовать все полученные промежуточные результаты для восстановления состояния.
- job-event.store.write-buffer.flush-interval – интервал очистки буферов записи JobEventStore.
- job-event.store.write-buffer.size – размер буфера записи Когда буфер заполнен, его содержимое сбрасывается во внешнюю файловую систему.
Освойте возможности Apache Flink для пакетной и потоковой аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- https://www.alibabacloud.com/blog/how%C2%A0flink%C2%A0batch%C2%A0jobs%C2%A0recover%C2%A0progress%C2%A0during%C2%A0jobmaster%C2%A0failover_601648
- https://nightlies.apache.org/flink/flink-docs-release-1.20/docs/ops/batch/recovery_from_job_master_failure/
- https://nightlies.apache.org/flink/flink-docs-release-2.0-preview1/api/java/org/apache/flink/runtime/jobmaster/event/JobEventStore/

