Что такое Chdb, зачем нужна эта библиотека и как ее использовать в коде Python-приложения для анализа больших данных в ClickHouse без разворачивания полноценного сервера этой колоночной СУБД.
Как и зачем работать с ClickHouse без сервера СУБД
ClickHouse является мощным инструментом аналитики больших данных, который требует соответствующей инфраструктуры. Однако, иногда нужно работать с данными в ClickHouse без разворачивания полноценного сервера этой колоночной СУБД. Например, чтобы выполнить локальные аналитические задачи в рамках разработки, тестирования или отладки приложения. Аналогичная потребность возникает при обработке данных на клиентской стороне, к примеру, в десктопном приложении, чтобы выполнить SQL-запросы без обращения к удалённому серверу. Для таких задач есть Chdb – специальная библиотека, которая позволяет работать с файлами формата ClickHouse прямо из приложения без необходимости разворачивать полноценный сервер СУБД. Разработанный участниками сообщества ClickHouse, ChDB представляет собой встроенный SQL-движок для OLAP-запросов на базе ClickHouse.
Используя Chdb, можно работать с ClickHouse как с движком выполнения SQL-запросов непосредственно в памяти приложения, написанного на языках Python, Go, Rust, NodeJS, Bun. Библиотека поддерживает Parquet, CSV, JSON, Apache Arrow, ORC и еще более 60 форматов данных. Chdb использует ядро ClickHouse, чтобы выполнять запросы и обрабатывать данные. Поэтому Chdb наследует высокую производительность и функциональность ClickHouse. Эта библиотека совместима с ClickHouse на уровне API, позволяя разработчику выполнять аналитические запросы с минимальными задержками непосредственно в приложении, не требуя отдельного сервера.
ClickHouse как полноценная СУБД предназначена для работы с постоянно хранящимися данными, а библиотека Chdb больше подходит для временной аналитики или встраивания аналитических функций в приложения. Это полезно, когда надо выполнять аналитические запросы на лету, без развертывания и поддержки отдельного сервера ClickHouse, например, в рамках тестирования и разработки, когда требуется быстрота и гибкость аналитики без тяжелой инфраструктуры. Также Chdb подходит для случаев, где важно минимизировать задержки и накладные расходы на сетевые взаимодействия.
Например, чтобы работать с ClickHouse с помощью Chdb в Python-приложении, его необходимо сперва установить, затем импортировать модули и можно выполнять запросы. Следующий код показывает пример чтения данных из таблицы колоночной СУБД:
pip install chdb
import chdb
# Устанавливаем соединение с ClickHouse
connection = chdb.Connection(
host='localhost', # Адрес сервера ClickHouse
port=9000, # Порт сервера ClickHouse
user='default', # Имя пользователя
password='', # Пароль пользователя
database='default' # Имя базы данных
)
# Выполняем SQL-запрос
query = "SELECT * FROM my_table LIMIT 10"
result = connection.execute(query)
# Обрабатываем и выводим результат
for row in result:
print(row)
# Закрываем соединение
connection.close()
Помимо SELECT-запросов, в Chdb добавлена поддержка сессий к привязкам Python, что позволяет разработчику сохранять состояние между запросами, создавая таблицы, в которые можно вставлять и запрашивать данные. Это переносит мощь ClickHouse-движка MergeTree и разреженных индексов в код Python-приложения, расширяя возможности локальной аналитики больших данных. Речь о Python зашла не случайно, ведь Chdb изначально разрабатывался как инструмент, который превратит ClickHouse в готовый к использованию Python-модуль. Именно этот язык разработки является самым популярным в области Data Science и инженерии данных. Учитывая возможности ClickHouse для аналитической обработки огромных объемов данных и решения ML-задач, идея работать с этой колоночной СУБД в рамках создания прототипирования аналитических приложений на Python, вполне логична. Однако, реализовать эту идею оказалось не так просто, что мы и разберем далее.
История создания Chdb
Вообще возможность встроить ClickHouse в модуль Python реализована уже давно: можно просто напрямую включить двоичный файл clickhouse-local в Python-пакет, а затем передать ему SQL, например, через класс popen() модуля subprocess в Python, извлекая результаты через канал. Напомним, в Python класс popen()выполняет дочернюю программу в новом процессе. В POSIX-системах этот класс использует os.execvp()для выполнения дочерней программы, а в Windows – функцию CreateProcess().
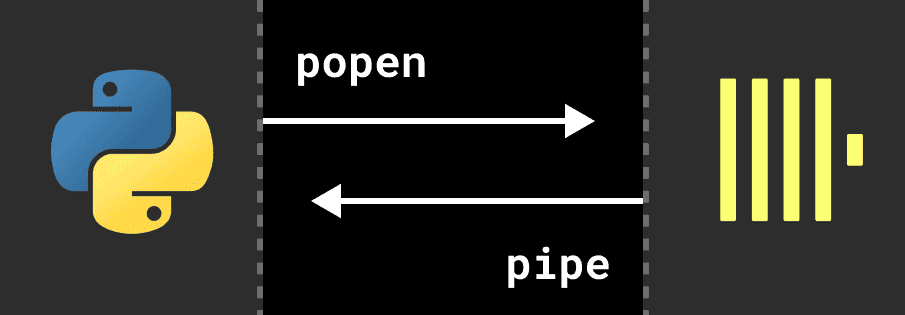
Однако такой подход влечет за собой ряд проблем:
- Запуск независимого процесса для каждого запроса сильно снижает производительность, особенно если размер двоичного файла clickhouse-local составляет около 500 МБ;
- Придется создавать несколько копий результатов SQL-запроса, чтобы считывать их из канала и копировать в буфер в Python-процессе.
- Реализация пользовательских функций Python и поддержка SQL в Pandas DataFrame ограничена.
Поэтому разработчики Chdb начали искать другое решение. ClickHouse включает ряд реализаций, называемых BufferBase, включая ReadBuffer и WriteBuffer, которые примерно соответствуют C++ istream и ostream. Для эффективного чтения из файлов и вывода результатов, например, чтение CSV или JSONEachRow и вывод результатов выполнения SQL-запросов, буфер ClickHouse также поддерживает произвольный доступ к базовой памяти. Он даже может создавать новые буферы на основе вектора без копирования памяти. ClickHouse внутренне использует производные классы BufferBase для чтения/записи сжатых файлов, а также удаленных файлов, например, из объектного хранилища S3 или внешних веб-ресурсов по протоколу HTTP.
Чтобы избежать копирования результатов выполнения SQL-запросов на уровне ClickHouse, вместо стандартного вывода stdout для получения данных разработчики Chdb использовали встроенный WriteBufferFromVector. Это гарантирует отсутствие блокировок параллельных выходных конвейеров при получении исходных блоков памяти выходных данных SQL-запросов. А, чтобы избежать копирования памяти из объектов C++ в Python, использованы Python-объекты memoryview, который позволяют коду Python получать доступ к внутренним данным объекта, поддерживающего буферный протокол.
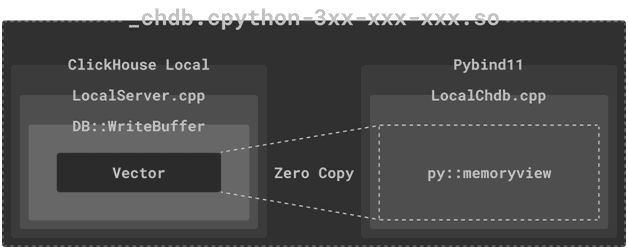
Чтобы обеспечить создание и уничтожение классов C++, которые необходимы для вышеописанной реализации, они связаны с жизненным циклом объектов Python с помощью простого определения шаблона класса:
class attribute((visibility("default"))) query_result {
public:
query_result(local_result * result) : result(result);
~query_result();
}
py::class_<query_result>(m, "query_result")
Этот код определяет класс query_result в C++ и делает его доступным для использования в Python через pybind11. Это позволяет интегрировать C++ код в Python приложения, обеспечивая возможность использования высокопроизводительных C++ функций и классов из Python. Атрибут visibility(“default”) используется в C++ для управления видимостью символов при компиляции. Указание visibility(“default”) означает, что класс query_result будет видим за пределами текущей сборки (например, динамической библиотеки), что позволяет использовать его в других модулях или приложениях. Конструктор query_result(local_result * result) принимает указатель на объект типа local_result и инициализирует член класса result. Стандартный деструктор ~query_result() будет вызван при уничтожении объекта этого класса. Код создаёт связывание класса query_result с Python, используя библиотеку pybind11. Создаваемый Python-класс query_result будет обёрткой для C++ класса query_result. Созданный класс добавлен в модуль Python и доступен под названием query_result.
Таким образом, архитектура Chdb выглядит так:
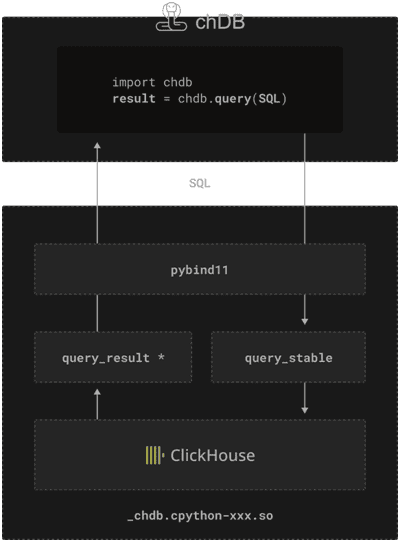
Бенчмаркинговые тесты, проведенные разработчиками этой библиотеки, показали ее высокую производительность при обработке больших объемов данных. Таким образом, Chdb может быть отличным инструментом для интеграции легковесной аналитики больших данных в приложение. Однако, это не отменяет ClickHouse, которая все равно остается мощной колоночной СУБД для сложной и долговременной аналитики больших данных, хранящихся в постоянном хранилище.
Научиться работать с ClickHouse вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

