Сегодня усложним пример из прошлой статьи с простым ETL-конвейером, который добавлял в базу данных интернет-магазина новые записи о клиентах, сгенерированные с помощью библиотеки Faker. Разбираем, как удалить из PostgreSQL данные об успешно доставленных заказах за прошлый месяц, предварительно сохранив их в JSON-файл с многоуровневой структурой. Пишем и запускаем DAG Apache...
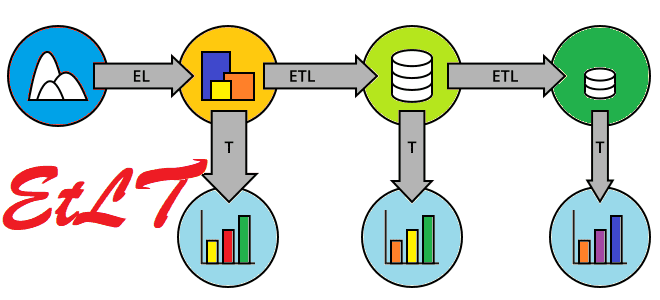
Как развивалась архитектура конвейеров обработки данных, что такое EtLT и почему этот подход почему постепенно заменяет классические ETL и ELT-инструменты. Краткая история развития современной дата-инженерии. От ETL к ELT и обратно: предыстория Архитектура конвейеров обработки данных претерпела несколько итераций от ETL, ELT, XX ETL (Reverse ETL, Zero-ETL) до EtLT. Если экосистема...
Что представляет собой очередное предложение по улучшению проекта Apache Kafka, которое расширяет возможности этой распределенной платформы потоковой передачи событий, превращая ее в средство долговременного хранения данных. Надежность vs скорость: вечный компромисс в Apache Kafka Изначально Apache Kafka позиционировалась как middleware, т.е. сервисный слой для асинхронной интеграции нескольких информационных систем. Этот...
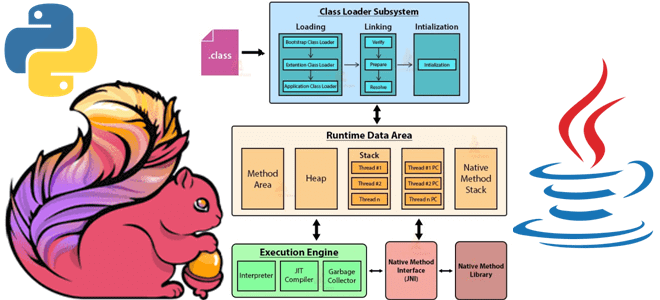
Как и большинство Big Data фреймворков, Apache Flink имеет Python API, позволяя разработчикам высоконагруженных потоковых приложений писать код на этом популярном языке программирования. Однако, Flink-задание выполняется в JVM, поэтому сам фреймворк транслирует Python-код в Java. Разбираемся, в чем особенности этого многоступенчатого процесса. Из Python в Java: как устроен API PyFlink...
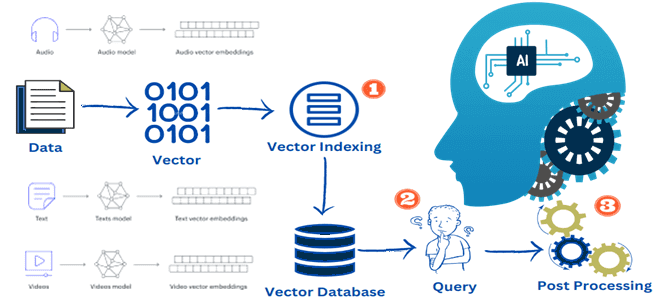
Как устроены векторные базы данных и почему они стали так популярны с распространением ИИ. Архитектура, алгоритмы, принципы работы и примеры векторных СУБД. Что такое векторная СУБД и при чем здесь ИИ Как и следует из названия, векторная база хранит данные в виде векторов. Это понятие из математики означает специализированное представление...

В январе 2023 года компания Arenadata, российский разработчик отечественных Big Data решений, выпустила средство мониторинга и управления коннекторами Apache Kafka для своего продукта Arenadata Streaming (ADS). Знакомимся с возможностями и ограничениями ADSCC. Arenadata Streaming Command Center для управления коннекторами Kafka Одной из главных фишек продуктов Arenadata, является ADCM (Arenadata Cluster...
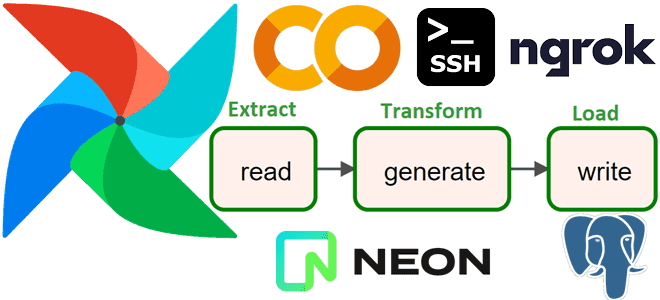
Сегодня реализуем простой ETL-конвейер для реляционной СУБД PostgreSQL, запустив Apache AirFlow в интерактивной среде Google Colab. Пример DAG из 3-х задач: получить количество строк в одной из таблиц БД, сгенерировать новые строки и записать их, не нарушив ограничений уникальности первичного ключа. Постановка задачи Возьмем в качестве примера базу данных для...
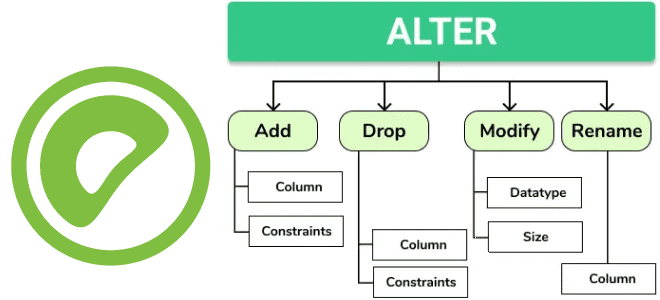
Какие команды изменения таблиц добавлены в 7-ю версию Greenplum и чем они полезны дата-инженеру. Разбираемся с новыми функциями: как добавить столбец, изменить его тип, кодировку хранения и перезаписать несколько таблиц одной командой. Добавление столбца О новых функциях работы с партиционированаными таблицами в Greenplum 7 мы уже писали. В частности, Greenplum...
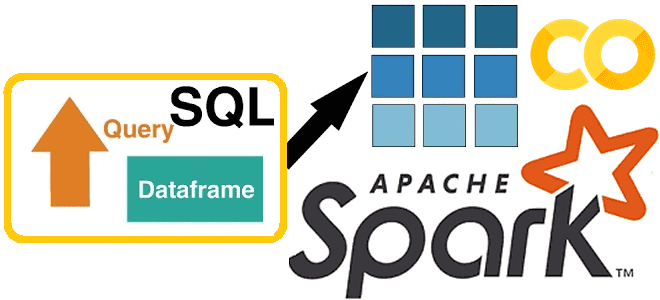
Чем полезны новые фичи Apache Spark SQL, выпущенные в релизе 3.4. Разбираемся с псевдонимами столбцов и параметризованными SQL-запросами на простых примерах, запуская Spark-приложение в Google Colab. Псевдонимы столбцов Хотя с момента выхода Apache Spark 3.4 в апреле 2023 года, о чем мы писали здесь, прошло почти полгода, возможность ссылаться на...

Что такое кластеризация с нулевым лидером, чем координатор отличается от основного узла, каким образом устроен механизм выбора лидера, зачем нужна изоляция процессоров и как ее реализовать, а также другие особенности кластера Apache NiFi. Ключевые компоненты кластера Apache NiFi Хотя Apache NiFi можно запустить на локальной машине, чтобы он выполнялся как...