 1170
1170 
Сегодня усложним пример из прошлой статьи с простым ETL-конвейером, который добавлял в базу данных интернет-магазина новые записи о клиентах, сгенерированные с помощью библиотеки Faker. Разбираем, как удалить из PostgreSQL данные об успешно доставленных заказах за прошлый месяц, предварительно сохранив их в JSON-файл с многоуровневой структурой. Пишем и запускаем DAG Apache AirFlow в Google Colab.
Постановка задачи
Экземпляр базы данных интернет-магазина, пример проектирования которой от концептуальной до физической модели для PostgreSQL я рассматривала здесь, развернут в облаке serverless-платформе Neon. Схема физической модели данных выглядит следующим образом:
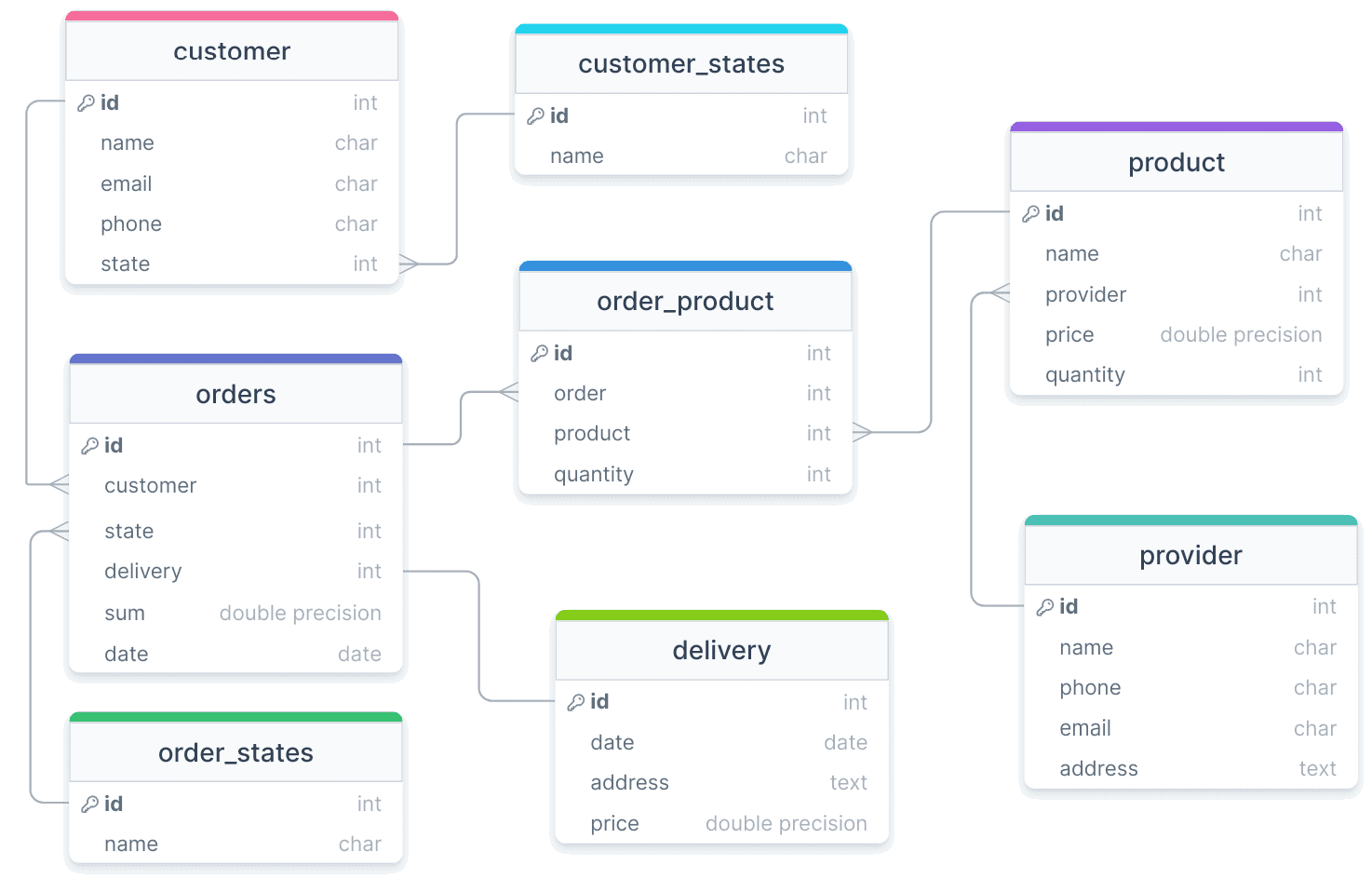
База данных уже наполнена записями. Предположим, чтобы «разгрузить» базу данных, ежемесячно необходимо удалять из нее сведения об успешно доставленных заказах за прошлый месяц, вместе с данными о продуктах, которые входят в этот заказа, а также, клиентах, сделавших заказы. Разумеется, перед удалением эти данные следует сохранить, записав их в архивное файловое хранилище. Далее сделаем это с помощью ETL-конвейера Apache AirFlow, но сперва проверим наличие в базе данных, отвечающих условиям выборки с помощью следующего SQL-запроса:
SELECT
orders.id,
orders.date,
orders.sum,
TRIM(product.name),
product.price,
order_product.quantity,
TRIM(provider.name),
TRIM(customer.name),
TRIM(customer.phone),
TRIM(customer.email),
TRIM(customer_states.name),
delivery.date,
TRIM(delivery.address),
delivery.price
FROM
orders
JOIN order_product ON order_product.order = orders.id
JOIN product ON product.id=order_product.product
JOIN provider ON provider.id = product.provider
JOIN customer ON orders.customer = customer.id
JOIN customer_states ON customer_states.id = customer.state
JOIN order_states ON order_states.id = orders.state
JOIN delivery ON orders.delivery = delivery.id
WHERE (orders.state=5) AND (orders.date BETWEEN (CURRENT_DATE-30) AND (CURRENT_DATE))
В этом запросе использована функция TRIM() для обрезки «лишних» пробелов, которые возникают в полях таблиц с типом данных char. Сперва запустим это запрос в веб-интерфейсе платформы Neon, где развернут экземпляр PostgreSQL. В результате получается большая сводная таблица с выполненными заказами за прошлый месяц от текущей даты (номер заказа, дата, сумма), включая данные о входящих в заказ товарах (название, цена, количество, название поставщика), а также сделавших эти заказы клиентах (имя, емейл, телефон).
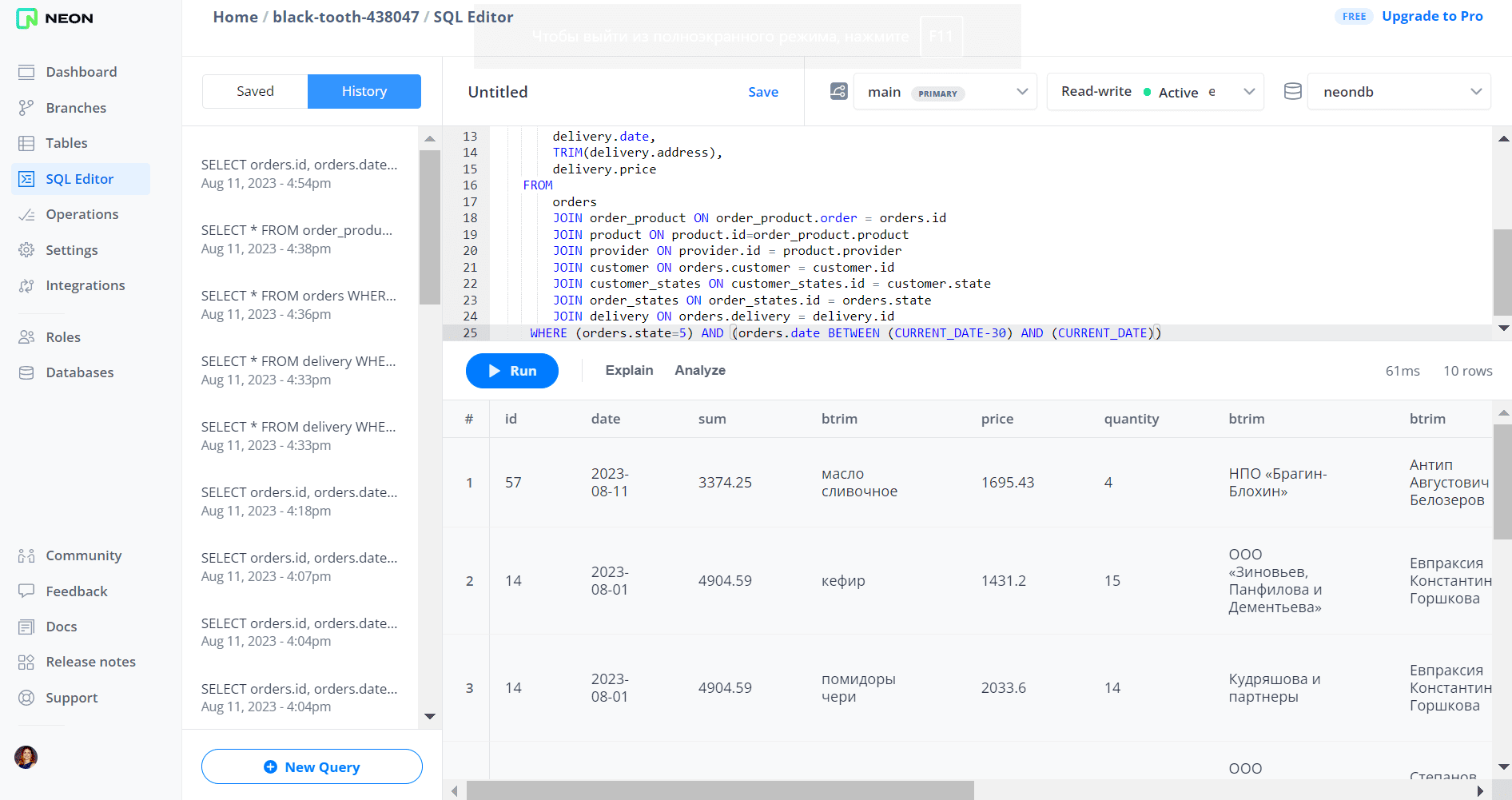
Убедившись, что данные, отвечающие нужным условиям, в базе присутствуют, далее напишем и запустим конвейер удаления этих данных из базы с их предварительным сохранением в JSON-файл. Оформим эту последовательность действий в виде DAG для Apache AirFlow.
Запуск AirFlow в Colab
Как обычно, я буду разворачивать AirFlow в Google Cloud Platform, и запускать DAG-файлы из Colab, используя удаленный исполнитель, о чем ранее писала здесь и здесь. Чтобы сделать это, следует пробросить туннель с локального хоста удаленной машины во внешний URl-адрес, поскольку Colab представляет собой удаленную среду в Google Cloud Platform, а не локальный хост разработчика. Такое туннелирование можно сделать с помощью утилиты ngrok, которую нужно установить в Colab вместе с другими библиотеками. Для этого нужно написать и запустить в ячейке Colab следующий код:
#Установка Apache Airflow и инициализация базы данных.
!pip install apache-airflow
!airflow initdb
#Установка инструмента ngrok для создания безопасного туннеля для доступа к веб-интерфейсу Airflow из любого места
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
!unzip ngrok-stable-linux-amd64.zip
!pip install pyngrok
#импорт модулей
from pyngrok import ngrok
import sys
import os
import datetime
from airflow import DAG
from airflow.operators.bash import BashOperator
from google.colab import drive
drive.mount('/content/drive')
os.makedirs('/content/airflow/dags', exist_ok=True)
dags_folder = os.path.join(os.path.expanduser("~"), "airflow", "dags")
os.makedirs(dags_folder, exist_ok=True)
#Получение версии установленного Apache Airflow
!airflow version
Затем запустим веб-сервер AirFlow на порту 8888 в виде демона — системной службы, которая запускает сервер в фоновом режиме, исполняя процесс без блокировки терминала, т.е. с возможностью запускать другие ячейки Colab.
#запуска веб-сервера Apache Airflow на порту 8888. Веб-сервер Airflow предоставляет пользовательский интерфейс для управления DAGами, #просмотра логов выполнения задач, мониторинга прогресса выполнения !airflow webserver --port 8888 --daemon
Пробросим туннель с локального хоста удаленной машины Colab ко внешнему URL с помощью ngrok, используя свой (ранее полученный) токен аутентификации:
#Задание переменной auth_token для аутентификации в сервисе ngrok.
auth_token = "……….ваш токен аутентификации……….." #@param {type:"string"}
# Since we can't access Colab notebooks IP directly we'll use
# ngrok to create a public URL for the server via a tunnel
# Authenticate ngrok
# https://dashboard.ngrok.com/signup
# Then go to the "Your Authtoken" tab in the sidebar and copy the API key
#Аутентификация в сервисе ngrok с помощью auth_token
os.system(f"ngrok authtoken {auth_token}")
#Запуск ngrok, который создаст публичный URL для сервера через туннель
#для доступа к веб-интерфейсу Airflow из любого места.
#addr="8888" указывает на порт, на котором запущен веб-сервер Airflow, а proto="http" указывает на использование протокола HTTP
public_url = ngrok.connect(addr="8888", proto="http")
#Вывод публичного URL для доступа к веб-интерфейсу Airflow
print("Адрес Airflow GUI:", public_url)
Инициализируем базу данных метаданных AirFlow, которой по умолчанию является легковесная СУБД SQLite. Она резидентная, т.е. хранится в памяти, а не на жестком диске. Для доступа в веб-интерфейс AirFlow, доступном по URL-адресу, полученному с помощью ngrok, нужно создать пользователя, под логином и паролем которого можно будет войти в веб-интерфейс ETL-оркестратора:
#############################ячейка №3 в Google Colab######################### !airflow db init #Инициализация базы данных Airflow !airflow upgradedb #Обновление базы данных Airflow #Создание нового пользователя в Apache Airflow с именем пользователя anna, именем Anna, фамилией Anna, адресом электронной почты anna@example.com и паролем password. #Этот пользователь будет иметь роль Admin, которая дает полный доступ к интерфейсу Airflow. !airflow users create --username anna --firstname Anna --lastname Anna --email anna@example.com --role Admin --password password
Теперь можно войти в GUI веб-сервера Apache AirFlow, указав логин и пароль ранее созданного пользователя.
Пока не запущен планировщик AirFlow в разделе DAGs пусто, т.е не отображается ни один конвейер. Лучше всего запустить планировщик AirFlow тоже в фоновом режиме с помощью аргумента —daemon:
!airflow scheduler --daemon
После выполнения этой команды в ячейке Colab, в веб-интерфейсе AirFlow в разделе DAGs будут показаны демонстрационные цепочки задач, которые создаются автоматически. Однако, нас интересует не обучающий типовой материал, а запуск собственного ETL-процесса для своей базы данных. Для этого напишем соответствующий пользовательский DAG.
ETL для PostgreSQL
Чтобы сократить количество ручных операций с Python-файлами, таких как копирование и загрузка, оформим код конвейера в виде текста, который генерируется кодом, запускаемым в Colab. Следующий код записывает DAG в файл, копирует его в соответствующий каталог в установке AirFlow, а также активирует его выполнение.
import psycopg2
from google.colab import files
code = '''
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import json
import os
import psycopg2
import requests
default_args = {
'owner': 'airflow',
'start_date': datetime.now() - timedelta(days=1),
'retries': 1
}
dag = DAG(
dag_id='ANNA_DAG_Clean_Orders',
default_args=default_args,
#schedule_interval='0 0 1 * *' # Повторять каждый первый день месяца в 00:00
schedule_interval='@daily'
)
def read_postgres(**kwargs):
connection_string='postgres://Yor_user_name:your_password@your_host.neon.tech/neondb'
conn = psycopg2.connect(connection_string)
select_query = """
SELECT
orders.id,
orders.date,
orders.sum,
TRIM(product.name),
product.price,
order_product.quantity,
TRIM(provider.name),
TRIM(customer.name),
TRIM(customer.phone),
TRIM(customer.email),
TRIM(customer_states.name),
delivery.date,
TRIM(delivery.address),
delivery.price
FROM
orders
JOIN order_product ON order_product.order = orders.id
JOIN product ON product.id=order_product.product
JOIN provider ON provider.id = product.provider
JOIN customer ON orders.customer = customer.id
JOIN customer_states ON customer_states.id = customer.state
JOIN order_states ON order_states.id = orders.state
JOIN delivery ON orders.delivery = delivery.id
WHERE (orders.state=5) AND (orders.date BETWEEN (CURRENT_DATE-30) AND (CURRENT_DATE))
"""
cur = conn.cursor()
cur.execute(select_query)
results = cur.fetchall()
cur.close()
conn.close()
return results
def write_to_file(**kwargs):
results = kwargs['ti'].xcom_pull(task_ids='read')
orders = []
order_dict = {}
for result in results:
order_id, order_date, order_sum, product_name, product_price, product_quantity, product_provider, customer_name, customer_phone, customer_email, customer_status, delivery_date, delivery_address, delivery_price = result
if order_id not in order_dict:
order_dict[order_id] = {
'order_id': order_id,
'order_date': str(order_date),
'order_sum': order_sum,
'products': [],
'customer': {
'customer_name': customer_name,
'customer_phone': customer_phone,
'customer_email': customer_email,
'customer_status': customer_status
},
'delivery': {
'delivery_date': str(delivery_date),
'delivery_address': delivery_address,
'delivery_price': delivery_price
}
}
product = {
'product_name': product_name,
'product_price': product_price,
'product_quantity': product_quantity,
'product_provider': product_provider
}
order_dict[order_id]['products'].append(product)
orders = list(order_dict.values())
filename = datetime.now().strftime("%Y-%m-%d_%H-%M-%S.json")
filepath = os.path.join('/content/airflow/files/delivered', filename)
with open(filepath, 'w') as f:
json.dump(orders, f)
f.close()
def delete_from_database():
connection_string='postgres://Yor_user_name:your_password@your_host.neon.tech/neondb'
conn = psycopg2.connect(connection_string)
delete_query = """
DELETE FROM order_product
WHERE order_product.order IN (
SELECT orders.id
FROM orders
WHERE order_product.order = orders.id
AND (orders.state=5) AND (orders.date BETWEEN (CURRENT_DATE-30) AND (CURRENT_DATE))
);
DELETE FROM orders
WHERE id IN (
SELECT orders.id
FROM orders
WHERE (orders.state=5) AND (orders.date BETWEEN (CURRENT_DATE-30) AND (CURRENT_DATE))
);
"""
cur = conn.cursor()
cur.execute(delete_query)
conn.commit()
cur.close()
conn.close()
read_task = PythonOperator(
task_id='read',
python_callable=read_postgres,
dag=dag
)
write_task = PythonOperator(
task_id='write',
python_callable=write_to_file,
provide_context=True,
dag=dag
)
delete_task = PythonOperator(
task_id='delete',
python_callable=delete_from_database,
provide_context=True,
dag=dag
)
read_task >> write_task >> delete_task
'''
with open('/root/airflow/dags/ANNA_DAG_Clean_Orders.py', 'w') as f:
f.write(code)
!cp ~/airflow/dags/ANNA_DAG_Clean_Orders.py /content/airflow/dags/ANNA_DAG_Clean_Orders.py
!airflow dags unpause ANNA_DAG_Clean_Orders
В этом коде выполняется импорт библиотек psycopg2 для работы с PostgreSQL и requests для выполнения HTTP-запросов. Также определяется переменная code, где хранится сам код DAG для Apache Airflow под названием ANNA_DAG_Clean_Orders. Целесообразно запускать этот DAG раз в месяц, однако, для тестирования и отладки я поставила расписание ежедневно, задав значение @daily в интервале запуска schedule_interval=’@daily’ вместо schedule_interval=’0 0 1 * *’, что означало бы повторять каждый первый день месяца в 00:00.
В этом DAG определены следующие функции:
- read_postgres — функция подключения к базе данных PostgreSQL, которая выполняет SELECT-запрос, выбирая определенные поля из таблицы с заказами (orders) и связанных с ней таблиц, согласно условию статуса успешной доставки и попадания даты заказа в прошлый месяц от текущей даты (WHERE (orders.state=5) AND (orders.date BETWEEN (CURRENT_DATE-30) AND (CURRENT_DATE)));
- write_to_file – функция, которая записывает результаты выполненного SQL-запроса в JSON-файл в формате;
- delete_from_database, которая выполняет удаление данных из таблиц order_product и orders на основе заданного выше словия.
Вышеприведенный код создает экземпляры класса PythonOperator для каждой задачи с указанием ее идентификатора, вызываемой Python-функции (python_callable) и DAG, к которому принадлежит задача. За передачу данных между задачами отвечает параметр provide_context=True, позволяющий предоставлять контекстные переменные (dag_run, execution_date, task_instance, task и пр.), которые нужны для выполнения представленного конвейера. Как упростить этот DAG-файл, описав каждую задачу в отдельном Python-скрипте, читайте в моей новой статье.
После выполнения кода, создающего Python-файл с DAG, этот ETL-конвейер появится в веб-интерфейсе AirFlow.
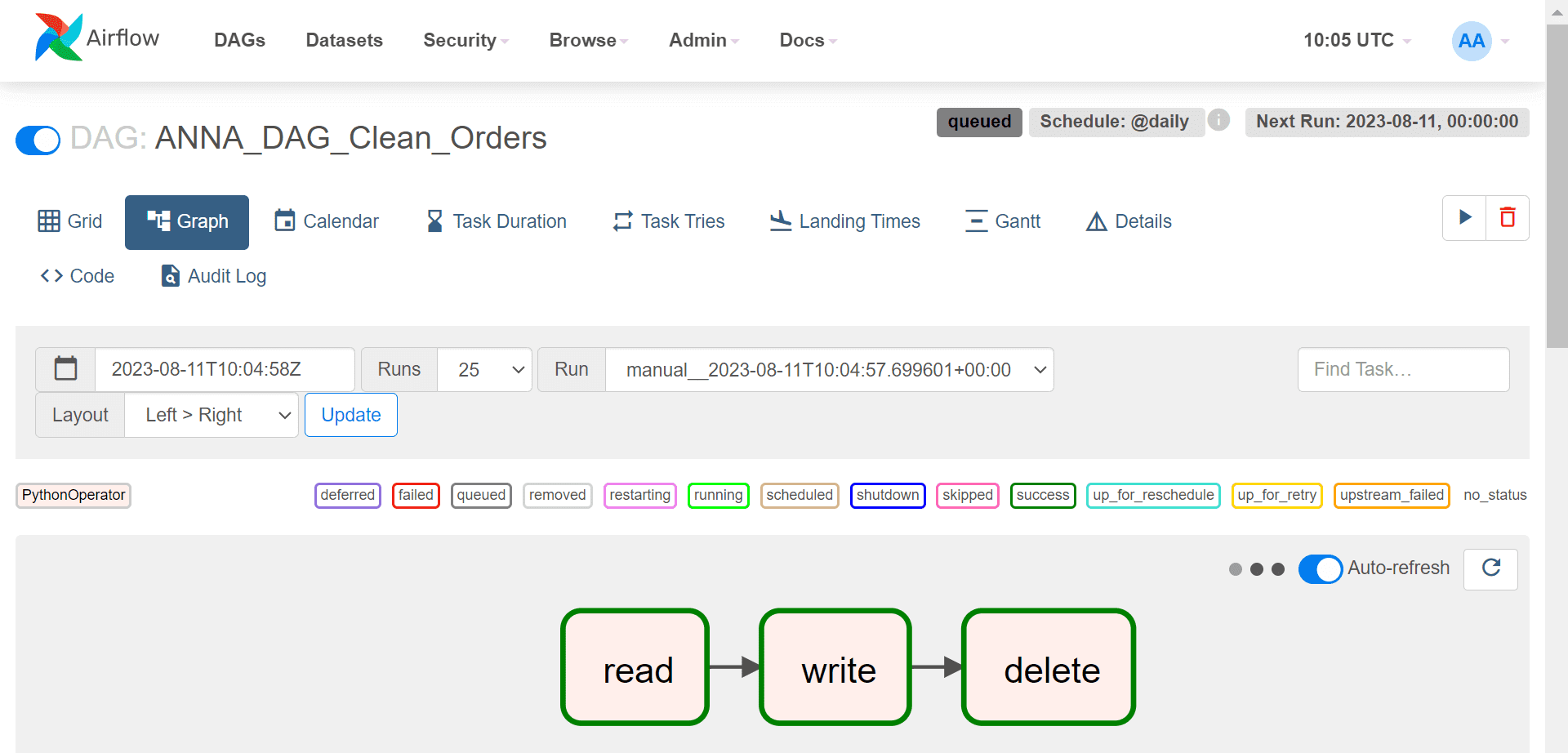
Запустив свой DAG с помощью команды Trigger, можно посмотреть, как каждая задача успешно выполняется. Граф задач выглядит так:
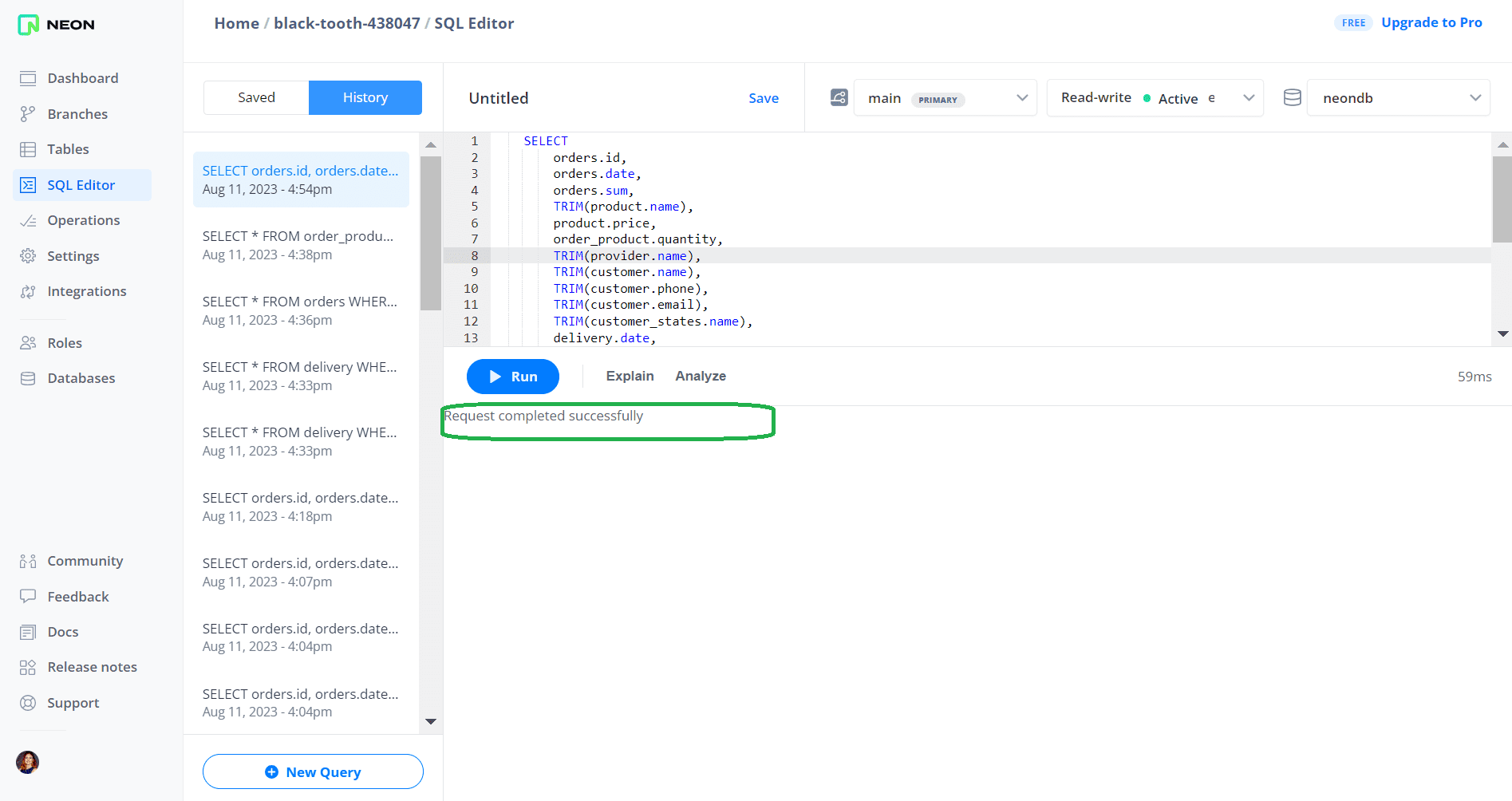
В интерфейсе платформы Neon, где развернут экземпляр PostgreSQL, можно проверить, что данные действительно удалены. Для этого снова запустим тот же самый запрос. В результате не выведено ни одной строки.
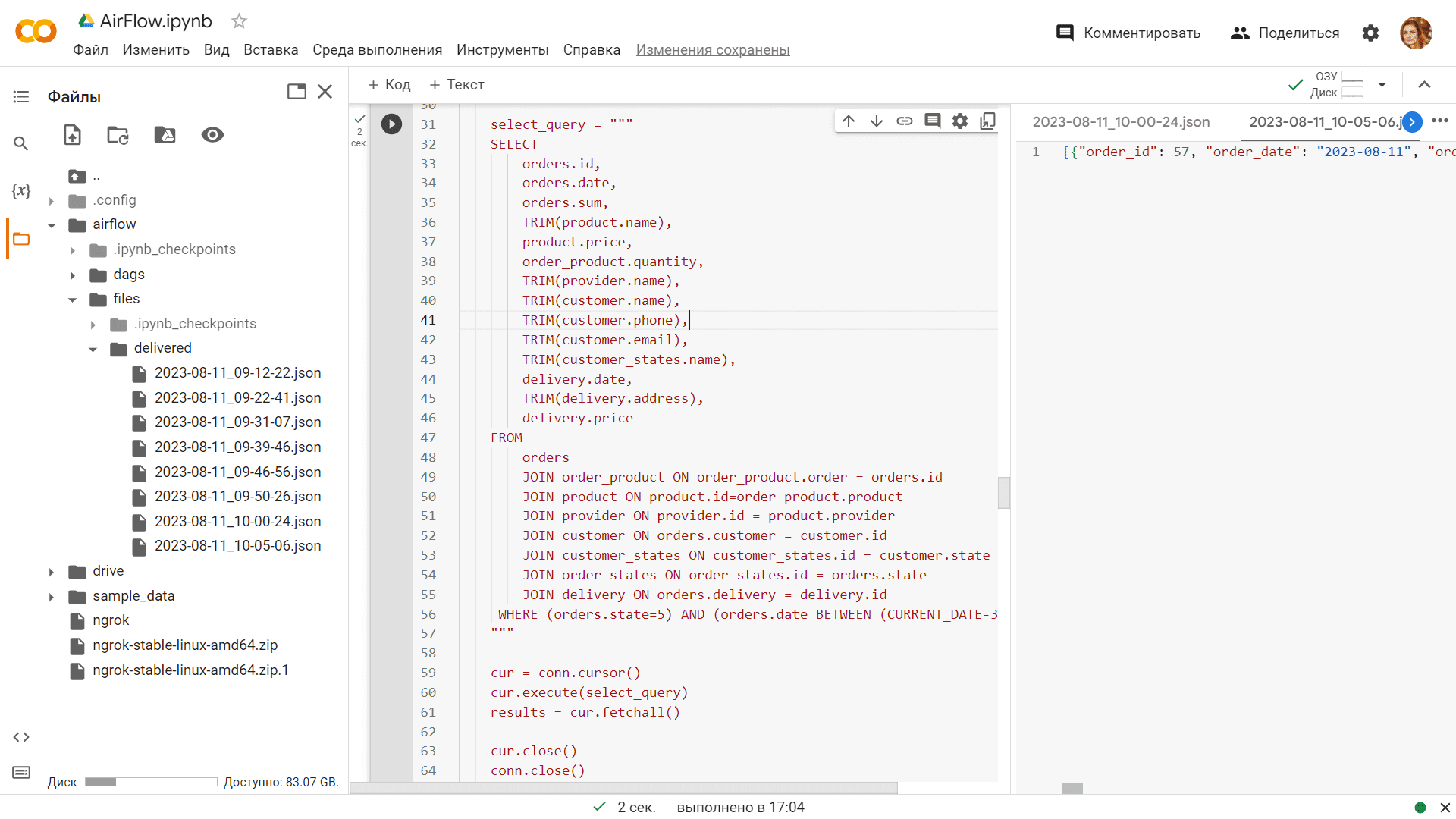
Удаленные данные сохранены в JSON-файл в папке, определенной в коде DAG. В моем случае это каталог /content/airflow/files/delivered в пространстве Colab. Имя файла содержит дату и время, когда был выполнен этот DAG. Поскольку в процессе разработки я очень много тестировала и отлаживала код, еще до операции удаления данных, этих JSON-файлов получилось больше, чем один.
JSON-файл содержит сведения об удаленных заказах, товарах и клиентах согласно следующей схеме:
{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Generated schema for Root",
"type": "array",
"items": {
"type": "object",
"properties": {
"order_id": {
"type": "number"
},
"order_date": {
"type": "string"
},
"order_sum": {
"type": "number"
},
"products": {
"type": "array",
"items": {
"type": "object",
"properties": {
"product_name": {
"type": "string"
},
"product_price": {
"type": "number"
},
"product_quantity": {
"type": "number"
},
"product_provider": {
"type": "string"
}
},
"required": [
"product_name",
"product_price",
"product_quantity",
"product_provider"
]
}
},
"customer": {
"type": "object",
"properties": {
"customer_name": {
"type": "string"
},
"customer_phone": {
"type": "string"
},
"customer_email": {
"type": "string"
},
"customer_status": {
"type": "string"
}
},
"required": [
"customer_name",
"customer_phone",
"customer_email",
"customer_status"
]
},
"delivery": {
"type": "object",
"properties": {
"delivery_date": {
"type": "string"
},
"delivery_address": {
"type": "string"
},
"delivery_price": {
"type": "number"
}
},
"required": [
"delivery_date",
"delivery_address",
"delivery_price"
]
}
},
"required": [
"order_id",
"order_date",
"order_sum",
"products",
"customer",
"delivery"
]
}
}
В самом файле данные отображаются не очень удобно для чтения (сплошным текстом), однако их можно переформатировать в любом онлайн-конвертере.
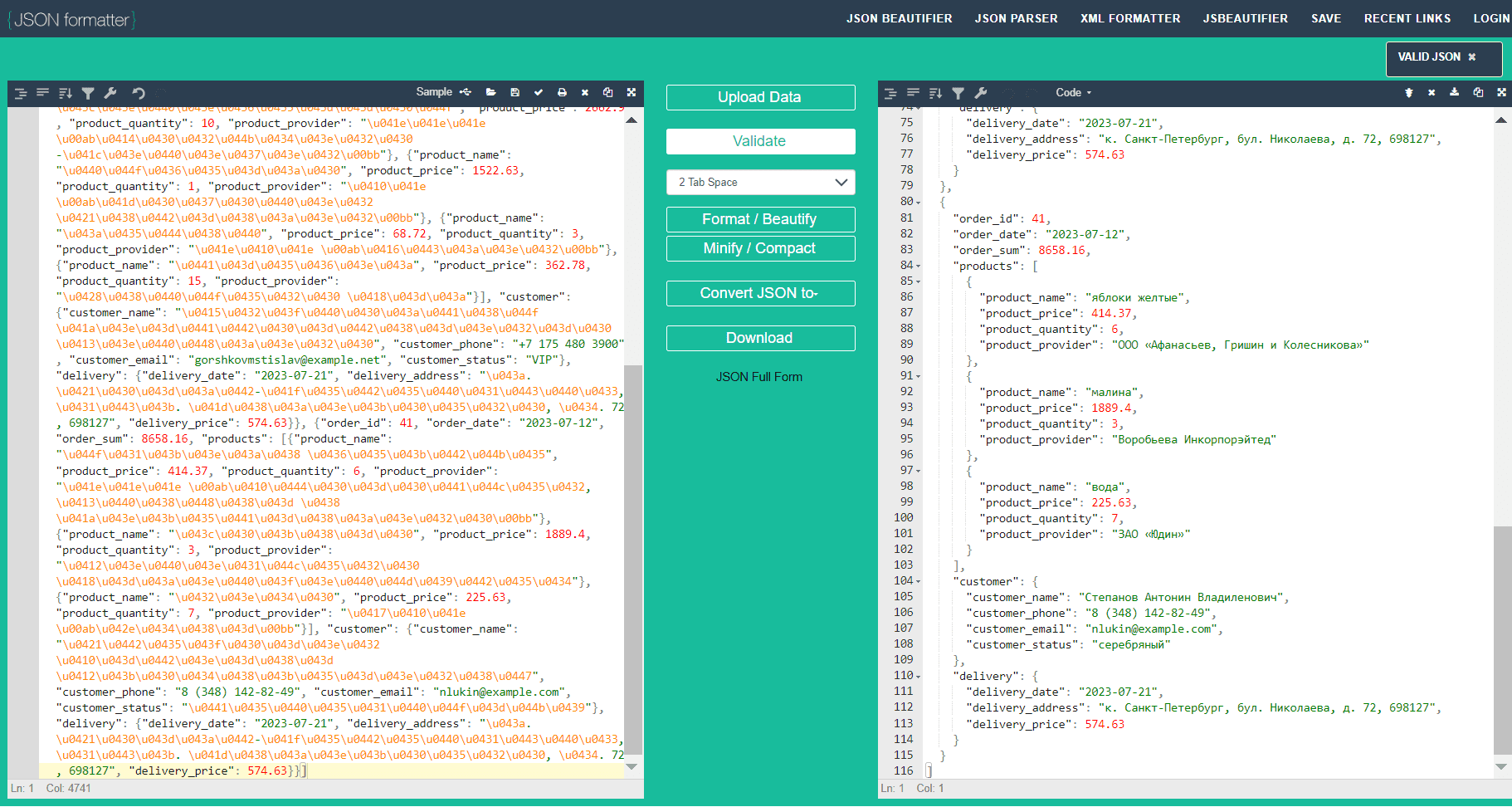
Таким образом, этот простой пример показал, как можно регулярно работать с удаленной РСУБД с помощью Apache AirFlow. Узнать больше про этот эффективный оркестратор рабочих процессов и его практическое использование в дата-инженерии и аналитике больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

