Как развивалась архитектура конвейеров обработки данных, что такое EtLT и почему этот подход почему постепенно заменяет классические ETL и ELT-инструменты. Краткая история развития современной дата-инженерии.
От ETL к ELT и обратно: предыстория
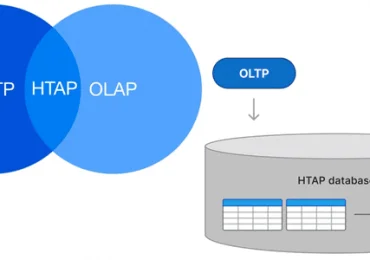
Архитектура конвейеров обработки данных претерпела несколько итераций от ETL, ELT, XX ETL (Reverse ETL, Zero-ETL) до EtLT. Если экосистема Hadoop в основном полагалась на ELT-методы (извлечение, загрузка, преобразование), появление хранилищ и озер данных, работающих в реальном времени сделало ELT устаревшим.
Впрочем, исторически первой архитектурой конвейера обработки данных считается ETL. Она основана на появлении корпоративных хранилищ данных в 1990-хх гг. Билл Инмон, автор методологии DW 2.0, определил Data Warehouse как архитектуру хранения данных для разделенных субъектов, где данные классифицируются и очищаются во время хранения. В то время большинство источников данных были структурированными реляционными базами, а хранилища преимущественно работали с OLTP-кейсами для запросов и хранения истории. Обработка сложных ETL-процессов с такими базами данных была не так-то проста. Чтобы решить эту проблему, появилось множество ETL-инструментов (Informatica, Talend, Kettle и пр.), которое упростило интеграцию сложных источников данных и повысило эффективность рабочих нагрузок хранилища данных.
Классическая ETL-архитектура обеспечивала плавную интеграцию сложных источников данных и переносила почти половину операций работы с хранилищем на ETL-инструменты. Поэтому почти 20 лет, с 90-хх гг. XX века до конца первого десятилетия XXI века включительно архитектура ETL считалась отраслевым стандартом инженерии данных. Однако, из-за высокой степени вовлечения профессиональных дата-инженеров, которые работали со специализированными ETL-инструментами, цикл обработки бизнес-требований становится довольно длинным.
Поэтому примерно с 2005 года начала активно развиваться архитектура ELT. Появились системы с массивно-параллельной обработкой (MPP, Massively Parallel Processing) и распределенные технологии, что привело к постепенному переходу от ETL к ELT. Наиболее яркими примерами здесь можно назвать продукты компании Teradata и Hadoop Hive, которые сосредоточились на прямой загрузке данных в промежуточный уровень хранилища без сложных преобразований, таких как объединение и группировка. Далее выполнялась обработка с использованием SQL или HQL из промежуточного уровня в атомарный уровень данных, далее в уровень агрегации и представления. Решения Teradata работали со структурированными данными, а Hadoop с неструктурированными.
Использование высокопроизводительных вычислений хранилища данных для обработки больших объемов данных повышает рентабельность инвестиций в оборудование. Сложная бизнес-логика может обрабатываться с помощью SQL-запросов, с которыми знакомы большинство аналитиков и дата-инженеров. Однако, ELT-архитектура начала XXI века подходила лишь для простых сценариев и работы с большими объемами данных, но была неэффективна во взаимодействии со сложными источниками. Кроме того, она не поддерживала обработку запросов в режиме реального времени. Подробнее про разницу ETL и ELT мы писали здесь.
От ELT к EtLT через ODS
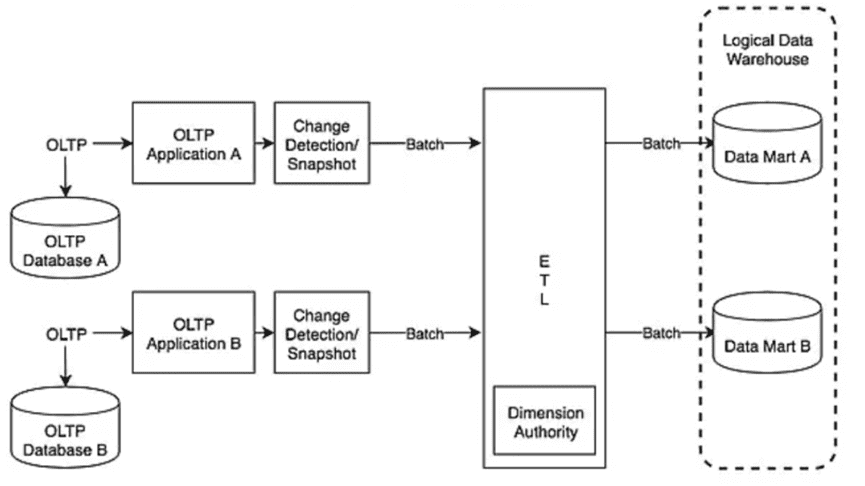
Чтобы смягчить недостатки ELT-архитектуры, в качестве переходного решения для работы со сложными источниками данных в реальном времени, была представлена идея ODS-хранилищ (Operational Data Store). ODS-архитектура включала обработку сложных источников данных через захват измененных данных (CDC, Change Data Capture) в реальном времени, а также выделение потоковых API или обработку микропакетов (Micro-Batch) в отдельный уровень хранения перед их ELT-перемещением в DWH. Этот подход до сих пор очень распространен. Например, ODS-хранилище может быть реализовано в рамках классического DWH, а задания Spark и MapReduce используются для начальных ETL-процессов. Позже они же выполняют обработку бизнес-данных в корпоративном хранилище данных, с использованием, например, Hive, Teradata, Oracle и DB2.
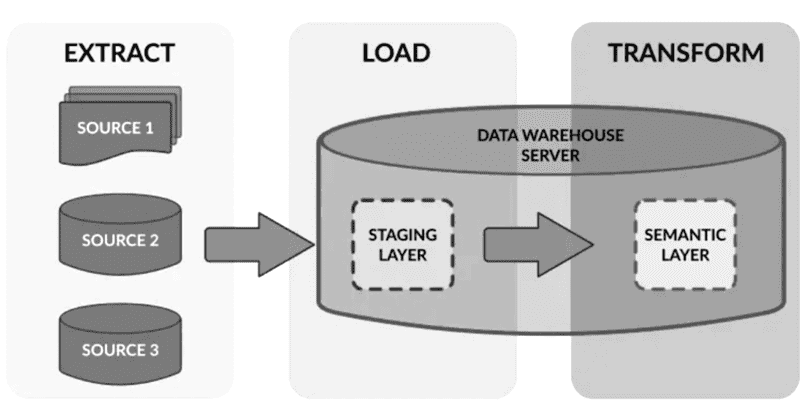
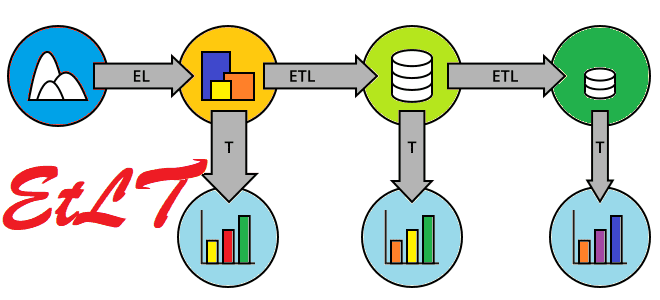
На данном этапе развития архитектуры данных уже зародились идеи EtLT (Extract, transform, Load, and Transform), включая разделение ролей, когда сложные процессы извлечения и структурирования данных, а также использование CDC-подходов и стандартизация всех этих операций выполняются дата-инженерами. Цель таких предварительных преобразований данных перед их загрузкой в хранилище в том, чтобы переместить данные из исходной системы на нижележащий уровень подготовки или атомарный уровень данных DWH. Впрочем, обработка сложных атомарных слоев данных с бизнес-атрибутами и агрегирование данных часто выполняется дата-аналитиками или BI-специалистами с помощью средств SQL-запросов.
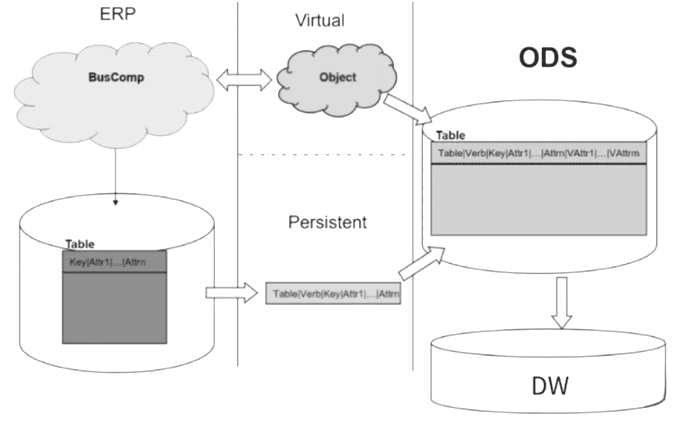
Кроме того, современные архитектуры типа Data LakeHouse объединяют черты традиционных ODS (Operational Data Store) и хранилищ данных, сочетая лучшее из этих подходов с технологиями, которые обеспечивают вычисления в реальном времени (Apache Hudi, Iceberg, Pinot, Apache Doris, Databricks Delta Lake, ClickHouse), о чем мы писали здесь. В результате ODS-архитектура постепенно исчезает из-за увеличения объема данных и популяризации принципов принятия принципов EtLT.
Data Pipeline на Apache Airflow
Код курса
AIRF
Ближайшая дата курса
2 июня, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Архитектура данных EtLT: появление и развитие
Таким образом, архитектуру EtLT, можно считать повторным открытием ETL с ориентацией на современные вызовы: работа со множеством различных источников данных в реальном времени. Популяризации архитектуры EtLT с 2020 года послужили следующие факторы:
- распространение SaaS-решений, облачных и гибридных источников данных;
- ориентация корпоративных хранилищ и озер данных на обработку в реальном времени;
- федерализация больших данных нового поколения;
- распространение приложений ИИ;
- фрагментация сообщества корпоративных данных.
В современной архитектуре данных появилось новое поколение технологий, направленных на ускорение загрузки данных, исключение их перемещения между различными хранилищами данных и выполнение сложных запросов напрямую через коннекторы. Например, TrinoDB и OneHouse на базе Apache Hudi. Эти инструменты отлично подходят для кэширования данных и оперативных запросов к различным источникам.
Кроме того, появление ChatGPT в 2022 году привело к использованию ИИ-моделей в различных бизнес-приложениях. Однако, узким местом для развертывания таких приложений стало предоставление данных, которое было решено озерами данных и федерализацией больших данных для хранения данных и запросов. Однако традиционные ETL, ELT и потоковая обработка не могут быстро интегрировать различные источники данных, не поддерживают разнообразные требования к данным, необходимые для обучения ИИ. Наконец, растет разнообразие пользователей данных от дата-инженеров до аналитиков различных категорий и специалистов по ИИ.
EtLT улучшает классические архитектуры ETL и ELT, сочетая обработку данных в реальном времени с пакетной обработкой для соответствия требованиям к хранилищам и озерам данных в реальном времени с учетом многообразия пользователей и потребности в использовании приложений ИИ.
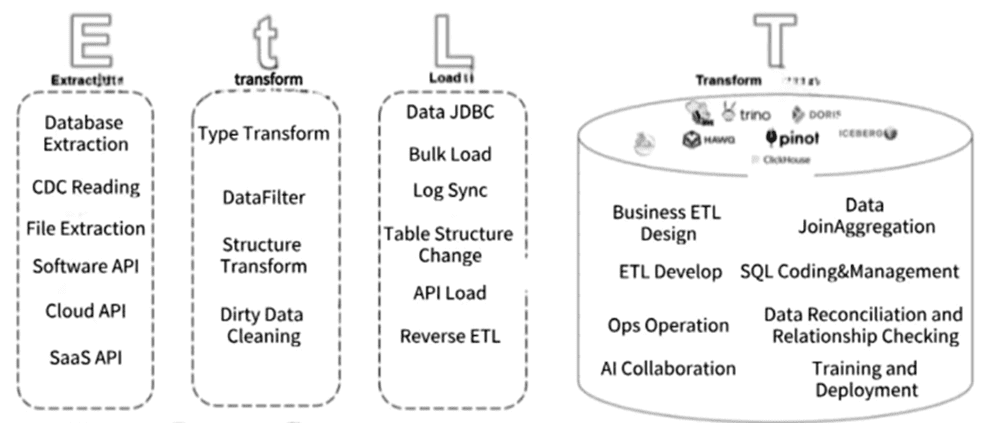
На этапе извлечения (Extract) EtLT поддерживает традиционные локальные базы данных, файловые хранилища, а также API SaaS и бессерверные источники данных. Эта архитектура может выполнять CDC в реальном времени для реляционной базы данных и потоковой обработки в реальном времени, например, Kafka Streams, а также поддерживает многопоточное чтение разделов. Этап нормализации данных и их предварительного преобразования (t, transform) быстро изменяет сложные и разнородные данные, извлеченные из разных источников, в структурированный вид, чтобы загрузить их в целевое хранилище. CDC реализуется через разделение, фильтрацию и изменение форматов полей, поддерживая пакетную и потоковую парадигмы.
Этап загрузки (Load) связан не только с загрузкой данных: он также включает в себя адаптацию структур и содержимого источника данных в соответствии с целевым объектом данных. На этом этапе обрабатываются изменения структуры данных (Schema Evolution) в исходном коде и выполняются эффективные методы загрузки пакетных и потоковых данных, такие как массовая загрузка, Reverse ETL и JDBC. Этап преобразования (Transform) обычно реализуется с помощью SQL в реальном времени или в пакетном режиме с использованием сложных бизнес-правил, характерных для бизнес-приложений или ИИ.
Существует несколько реализаций EtLT с открытым исходным кодом, например, dbt, Apache Dolphin и SeaTunnel. В частности, SeaTunnel включает поддержку крупномасштабных моделей, что позволяет им напрямую взаимодействовать с более чем 100 поддерживаемыми источниками данных, начиная от традиционных баз данных и SaaS. Также SeaTunnel поддерживает обучение крупномасштабных моделей и векторных баз данных, обеспечивая беспрепятственное взаимодействие между большими языковыми моделями, позволяя использовать ChatGPT для прямого создания SaaS-коннекторов.
Узнайте больше про использование современные архитектуры данных в проектах дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники