 782
782 
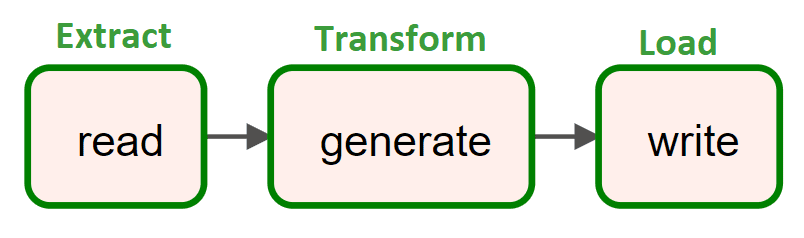
Сегодня реализуем простой ETL-конвейер для реляционной СУБД PostgreSQL, запустив Apache AirFlow в интерактивной среде Google Colab. Пример DAG из 3-х задач: получить количество строк в одной из таблиц БД, сгенерировать новые строки и записать их, не нарушив ограничений уникальности первичного ключа.
Постановка задачи
Возьмем в качестве примера базу данных для интернет-магазина, пример проектирования которой от концептуальной до физической модели для PostgreSQL я рассматривала здесь. Интернет-магазин продает товары от разных поставщиков. Клиент может забрать каждый заказ самостоятельно или оформить платную доставку от магазина. В магазине действует программа лояльности для покупателей с присвоением им различных статусов в зависимости от общей суммы покупок.
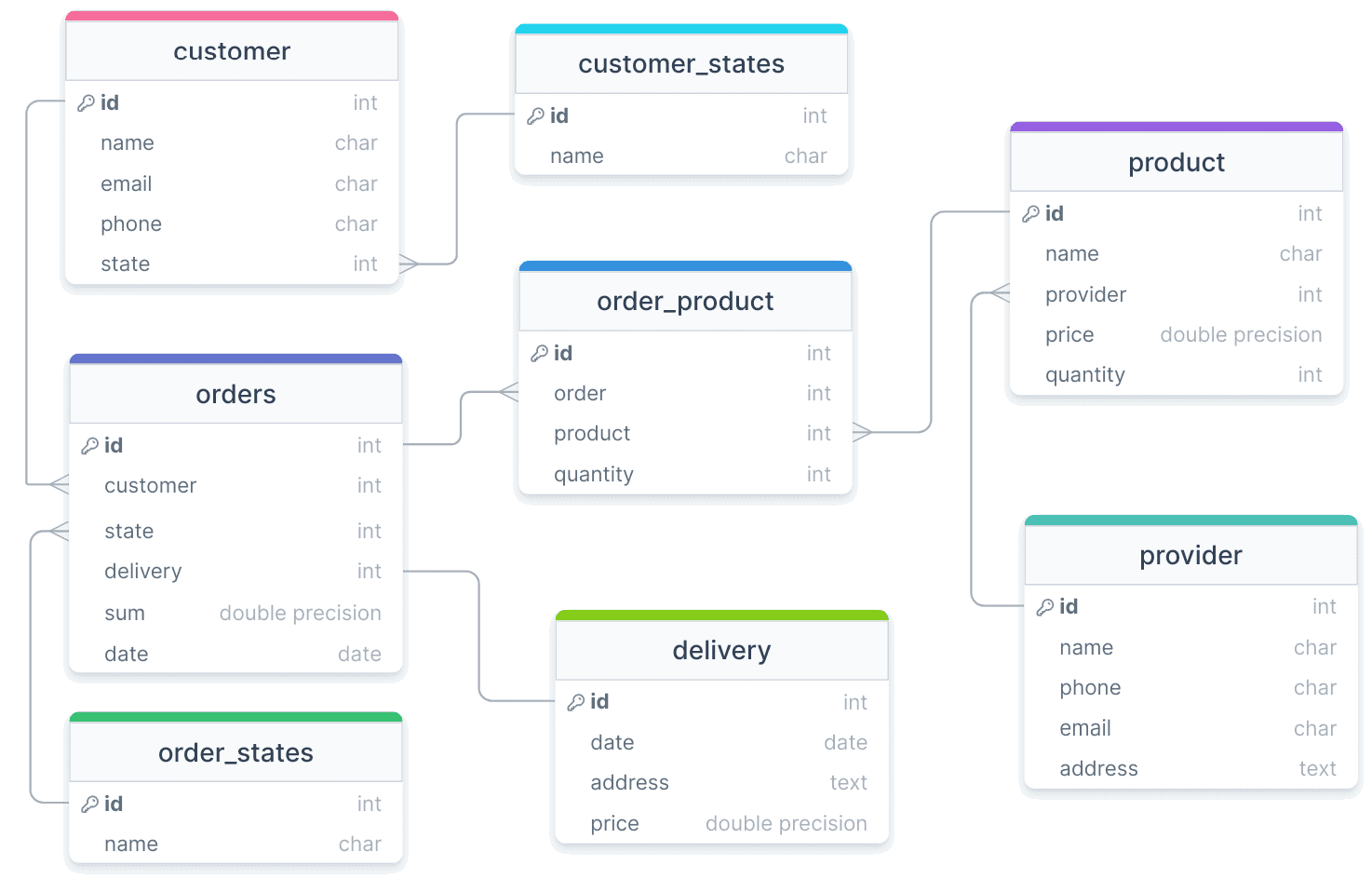
Согласно проведенному анализу предметной области, был выполнен ряд итераций проектирования моделей данных. В результате создания физической модели и генерации DDL-скриптов в базе данных, развернутой в облачном экземпляре PostgreSQL на serverless-платформе Neon, были созданы следующие таблицы.
|
Таблица |
Сущность домена |
Поле |
Назначение |
Тип данных |
|
customer |
Клиент |
id |
Уникальный идентификатор, первичный ключ (PRIMARY KEY) |
int (целочисленный) |
|
name |
Имя |
сhar (символьный) |
||
|
|
Емейл |
сhar (символьный) |
||
|
phone |
Телефон |
сhar (символьный) |
||
|
state |
Ссылка на Статус Клиента, внешний ключ (FOREIGN KEY) |
int (целочисленный) |
||
|
|
||||
|
order |
Заказ |
id |
Уникальный идентификатор, первичный ключ (PRIMARY KEY) |
int (целочисленный) |
|
date |
Дата |
date (дата YYYY-MM-DD) |
||
|
sum |
Сумма |
Double precision (вещественное двойной точности) |
||
|
state |
Ссылка на Статус Заказа, внешний ключ (FOREIGN KEY) |
int (целочисленный) |
||
|
customer |
Ссылка на Клиент, внешний ключ (FOREIGN KEY) |
int (целочисленный) |
||
|
product |
Ссылка на Товары В Заказе, внешний ключ (FOREIGN KEY) |
int (целочисленный) |
||
|
|
||||
|
product |
Товар |
id |
Уникальный идентификатор, первичный ключ (PRIMARY KEY) |
int (целочисленный) |
|
name |
Название |
сhar (символьный) |
||
|
provider |
Ссылка на Поставщик, внешний ключ (FOREIGN KEY) |
int (целочисленный) |
||
|
price |
Цена |
Double precision (вещественное двойной точности) |
||
|
quantity |
Количество |
int (целочисленный) |
||
|
|
||||
|
provider |
Поставщик |
id |
Уникальный идентификатор, первичный ключ (PRIMARY KEY) |
int (целочисленный) |
|
name |
Название |
сhar (символьный) |
||
|
|
Емейл |
сhar (символьный) |
||
|
phone |
Телефон |
сhar (символьный) |
||
|
address |
Адрес |
text (текстовый) |
||
|
|
||||
|
delivery |
Доставка |
id |
Уникальный идентификатор, первичный ключ (PRIMARY KEY) |
int (целочисленный) |
|
date |
Дата |
date (дата YYYY-MM-DD) |
||
|
address |
Адрес |
text (текстовый) |
||
|
price |
Стоимость |
Double precision (вещественное двойной точности) |
||
|
|
||||
|
customer_states |
Статус Клиента |
id |
Уникальный идентификатор, первичный ключ (PRIMARY KEY) |
int (целочисленный) |
|
name |
Название |
сhar (символьный) |
||
|
|
||||
|
order_states |
Статус Заказа |
id |
Уникальный идентификатор, первичный ключ (PRIMARY KEY) |
int (целочисленный) |
|
name |
Название |
сhar (символьный) |
||
|
|
||||
|
order_product |
Товары в Заказе |
id |
Уникальный идентификатор, первичный ключ (PRIMARY KEY) |
int (целочисленный) |
|
order |
Ссылка на Заказ, внешний ключ (FOREIGN KEY) |
int (целочисленный) |
||
|
product |
Ссылка на Товар, внешний ключ (FOREIGN KEY) |
int (целочисленный) |
||
|
quantity |
Количество |
int (целочисленный) |
||
Схема физической модели данных выглядит следующим образом:
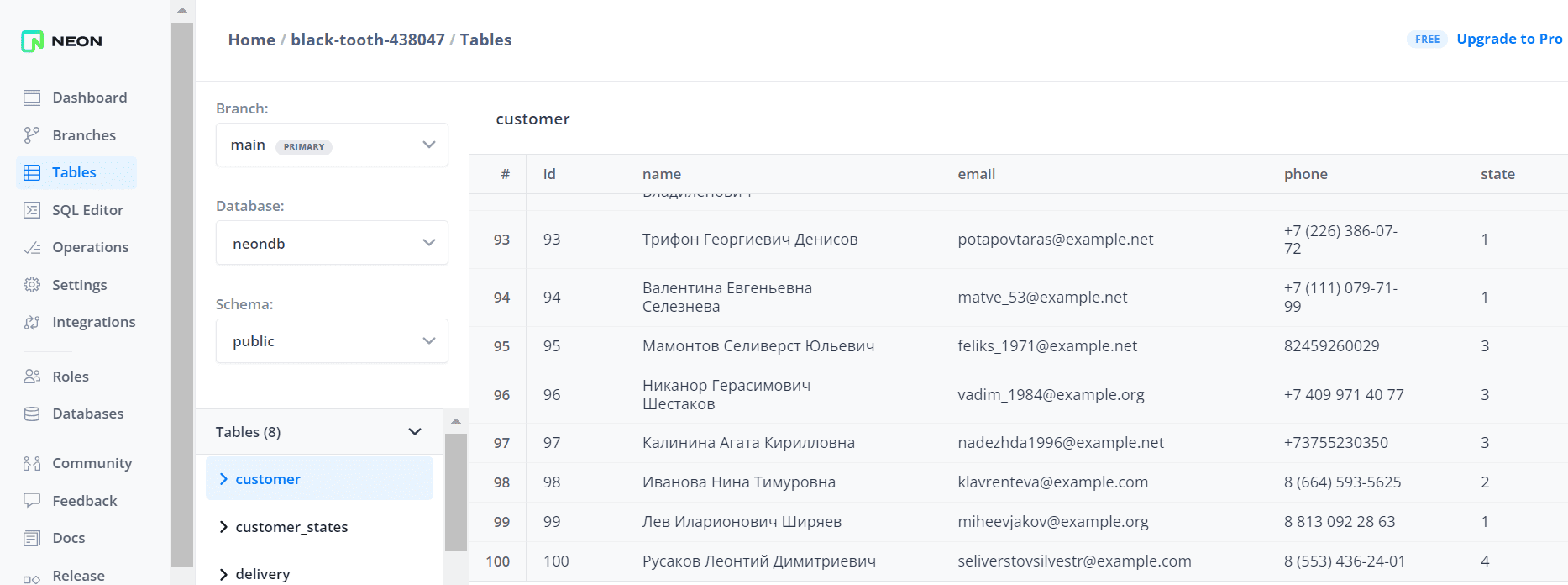
В таблице customer уже есть 100 записей, которые были добавлены туда заранее.
Для регистрации новой партии клиентов необходимо знать количество записей в таблице customer, чтобы соблюсти ограничения уникальности первичного ключа. Для этого необходимо сперва выполнить SQL-запрос к таблице customer
SELECT COUNT(*) FROM customer
Затем надо сгенерировать партию данных о клиентах и записать их в базу данных.
Рассмотрим эту последовательность действий как простой ETL-запрос, который можно представить в виде направленного ациклического графа (DAG) Apache AirFlow.
Генерировать данные о клиентах, как обычно, я буду с помощью Python-библиотеки Faker, разворачивать AirFlow в Google Cloud Platform, и запускать DAG-файлы из Colab, используя удаленный исполнитель, о чем ранее писала здесь и здесь.
Запуск AirFlow в Colab
Чтобы использовать AirFlow в Google Cloud Platform, и запускать DAG-файлы из Colab, следует пробросить туннель с локального хоста удаленной машины во внешний URl-адрес. Это можно сделать с помощью утилиты ngrok, которую нужно установить в Colab вместе с другими библиотеками. Для этого я написала и запустила в ячейке Colab следующий код:
!pip install apache-airflow
!airflow initdb
#Установка инструмента ngrok для создания безопасного туннеля для доступа к веб-интерфейсу Airflow из любого места
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
!unzip ngrok-stable-linux-amd64.zip
!pip install pyngrok
#импорт модулей
from pyngrok import ngrok
import sys
import os
import datetime
from airflow import DAG
from airflow.operators.bash import BashOperator
from google.colab import drive
drive.mount('/content/drive')
os.makedirs('/content/airflow/dags', exist_ok=True)
dags_folder = os.path.join(os.path.expanduser("~"), "airflow", "dags")
os.makedirs(dags_folder, exist_ok=True)
Затем запустим веб-сервер AirFlow на порту 8888 в виде демона — системной службы, которая запускает сервер в фоновом режиме, исполняя процесс без блокировки терминала, т.е. с возможностью запускать другие ячейки Colab.
#запуск веб-сервера Apache Airflow на порту 8888. Веб-сервер Airflow предоставляет пользовательский интерфейс для управления DAGами, #просмотра логов выполнения задач, мониторинга прогресса выполнения !airflow webserver --port 8888 --daemon
Пробросим туннель с локального хоста удаленной машины Colab ко внешнему URL с помощью ngrok, используя свой (ранее полученный) токен аутентификации:
#Задание переменной auth_token для аутентификации в сервисе ngrok.
auth_token = "……….ваш токен аутентификации……….." #@param {type:"string"}
# Since we can't access Colab notebooks IP directly we'll use
# ngrok to create a public URL for the server via a tunnel
# Authenticate ngrok
# https://dashboard.ngrok.com/signup
# Then go to the "Your Authtoken" tab in the sidebar and copy the API key
#Аутентификация в сервисе ngrok с помощью auth_token
os.system(f"ngrok authtoken {auth_token}")
#Запуск ngrok, который создаст публичный URL для сервера через туннель
#для доступа к веб-интерфейсу Airflow из любого места.
#addr="8888" указывает на порт, на котором запущен веб-сервер Airflow, а proto="http" указывает на использование протокола HTTP
public_url = ngrok.connect(addr="8888", proto="http")
#Вывод публичного URL для доступа к веб-интерфейсу Airflow
print("Адрес Airflow GUI:", public_url)
Далее инициализируем базу данных метаданных AirFlow, которой по умолчанию является легковесная СУБД SQLite. Она резидентная, т.е. хранится в памяти, а не на жестком диске. Для доступа в веб-интерфейс AirFlow, доступном по URL-адресу, полученному с помощью ngrok, нужно создать пользователя, под логином и паролем которого можно будет войти в веб-интерфейс ETL-оркестратора:
#############################ячейка №3 в Google Colab######################### !airflow db init #Инициализация базы данных Airflow !airflow upgradedb #Обновление базы данных Airflow #Создание нового пользователя в Apache Airflow с именем пользователя anna, именем Anna, фамилией Anna, адресом электронной почты anna@example.com и паролем password. #Этот пользователь будет иметь роль Admin, которая дает полный доступ к интерфейсу Airflow. !airflow users create --username anna --firstname Anna --lastname Anna --email anna@example.com --role Admin --password password
Теперь можно войти в GUI веб-сервера Apache AirFlow, указав логин и пароль ранее созданного пользователя.
Пока не запущен планировщик AirFlow в разделе DAGs пусто, т.е не отображается ни один конвейер. Лучше всего запустить планировщик AirFlow тоже в фоновом режиме с помощью аргумента —daemon:
!airflow scheduler --daemon
После выполнения этой команды в ячейке Colab, в веб-интерфейсе AirFlow в разделе DAGs будут показаны демонстрационные цепочки задач, которые создаются автоматически. Однако, нас интересует не обучающий типовой материал, а запуск собственного ETL-процесса для своей базы данных. Для этого напишем соответствующий пользовательский DAG.
ETL для PostgreSQL
Чтобы сократить количество ручных операций с Python-файлами, таких как копирование и загрузка, сегодня я решила оформить код конвейера в виде текста, который генерируется кодом, запускаемым в Colab. Для этого сначала следует установить необходимые пакеты: Faker – для генерации случайных данных и psycopg2 — адаптер PostgreSQL для Python, нужный для автоматической подстройки типов при составлении SQL-запросов и получении ответов.
!pip install psycopg2 import random import datetime from faker import Faker from google.colab import files from faker.providers.address.ru_RU import Provider
Наконец, напишем код, который записывает DAG в файл, копирует его в соответствующий каталог в установке AirFlow, а также активирует его выполнение.
import psycopg2
from google.colab import files
code = '''
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Connection
from datetime import datetime, timedelta
from faker import Faker
from faker.providers import phone_number, person
import psycopg2
default_args = {
'owner': 'airflow',
'start_date': datetime.now() - timedelta(days=1),
'retries': 1
}
dag = DAG(
dag_id='ANNA_DAG_Generate_Customer',
default_args=default_args,
schedule_interval='@daily'
)
def read_postgres(**kwargs):
connection_string='postgres://Yor_user_name:your_password@your_host.neon.tech/neondb'
conn = psycopg2.connect(connection_string)
# Specify the table name
table_name = 'customer'
select_query = f"SELECT COUNT(*) FROM {table_name};"
# Create a cursor object
cur = conn.cursor()
# Execute the SQL query
cur.execute(select_query)
# Get the result of the query
result = cur.fetchone()
# Close the cursor and connection
cur.close()
conn.close()
# Return the count of records
return result[0]
def generate_faker_data(**kwargs):
# Получение аргумента 'of' из контекста
of = kwargs['ti'].xcom_pull(task_ids='read')
# Creating a Faker object with Russian locale
fake = Faker('ru_RU')
fake.add_provider(phone_number)
fake.add_provider(person)
# Specify the table name
table_name = 'customer'
# Specify the column names of the table
column_names = ('id', 'name', 'email', 'phone', 'state')
# Specify the number of rows to generate
k = 10
# Create the string of column names
columns_str = ', '.join(f'"{column}"' for column in column_names)
insert_queries = []
for i in range(k):
# Generate values for each column
name = f"'{fake.unique.name()}'" # Generate a unique random name
email = f"'{fake.unique.email()}'" # Generate a unique random email
phone = f"'{fake.phone_number()}'" # Generate a random phone number
state = fake.random_int(min=1, max=4) # Generate a random value for the foreign key
# Create a list of values
values = [int(of) + i + 1, name, email, phone, state]
# Create a string of values
values_str = ', '.join(str(value) for value in values)
# Create and append the DML query
insert_query = f"INSERT INTO {table_name} ({columns_str}) VALUES ({values_str});"
insert_queries.append(insert_query)
print(insert_query) # Print to console for debugging
return insert_queries
def write_to_postgres(**kwargs):
insert_queries = kwargs['ti'].xcom_pull(task_ids='generate')
connection_string='postgres://Yor_user_name:your_password@your_host.neon.tech/neondb'
conn = psycopg2.connect(connection_string)
# Create a cursor object
cur = conn.cursor()
for insert_query in insert_queries:
# Execute the SQL query
cur.execute(insert_query)
# Commit the changes to the database
conn.commit()
# Close the cursor and connection
cur.close()
conn.close()
read_task = PythonOperator(
task_id='read',
python_callable=read_postgres,
provide_context=True,
dag=dag
)
generate_task = PythonOperator(
task_id='generate',
python_callable=generate_faker_data,
provide_context=True,
dag=dag
)
write_task = PythonOperator(
task_id='write',
python_callable=write_to_postgres,
provide_context=True,
dag=dag
)
read_task >> generate_task >> write_task
'''
with open('/root/airflow/dags/ANNA_generate_customer_data.py', 'w') as f:
f.write(code)
!cp ~/airflow/dags/ANNA_generate_customer_data.py /content/airflow/dags/ANNA_DAG_Generate_Customer.py
!airflow dags unpause ANNA_DAG_Generate_Customer
В этом коде определены 3 Python-функции для задач DAG:
- read_postgres — функция подключения к базе данных PostgreSQL, которая выполняет SELECT-запрос для подсчета количества записей в таблице customer и возвращает количество записей;
- generate_faker_data — функция генерации случайных данных о клиентах с помощью библиотеки Faker. Она получает количество записей из задачи read_postgres и генерирует 10 строк для таблицы customer согласно заданной схеме, т.е. названиям таблиц и их типам данных. В случае моей БД таблица с клиентами включает такие поля как идентификатор, имя, электронная почта, телефон и статус. Сгенерированные данные возвращаются в виде списка INSERT-запросов.
- write_to_postgres — функция записи данных в PostgreSQL, которая выполняет ранее INSERT-запросы, сгенерированные задачей generate_faker_data, для вставки данных в таблицу customer.
Вышеприведенный код создает экземпляры класса PythonOperator для каждой задачи с указанием ее идентификатора, вызываемой Python-функции (python_callable) и DAG, к которому принадлежит задача. За передачу данных между задачами отвечает параметр provide_context=True, позволяющий предоставлять контекстные переменные (dag_run, execution_date, task_instance, task и пр.), которые нужны для выполнения представленного конвейера.
После выполнения кода, создающего Python-файл с DAG, этот конвейер появится в веб-интерфейсе AirFlow.
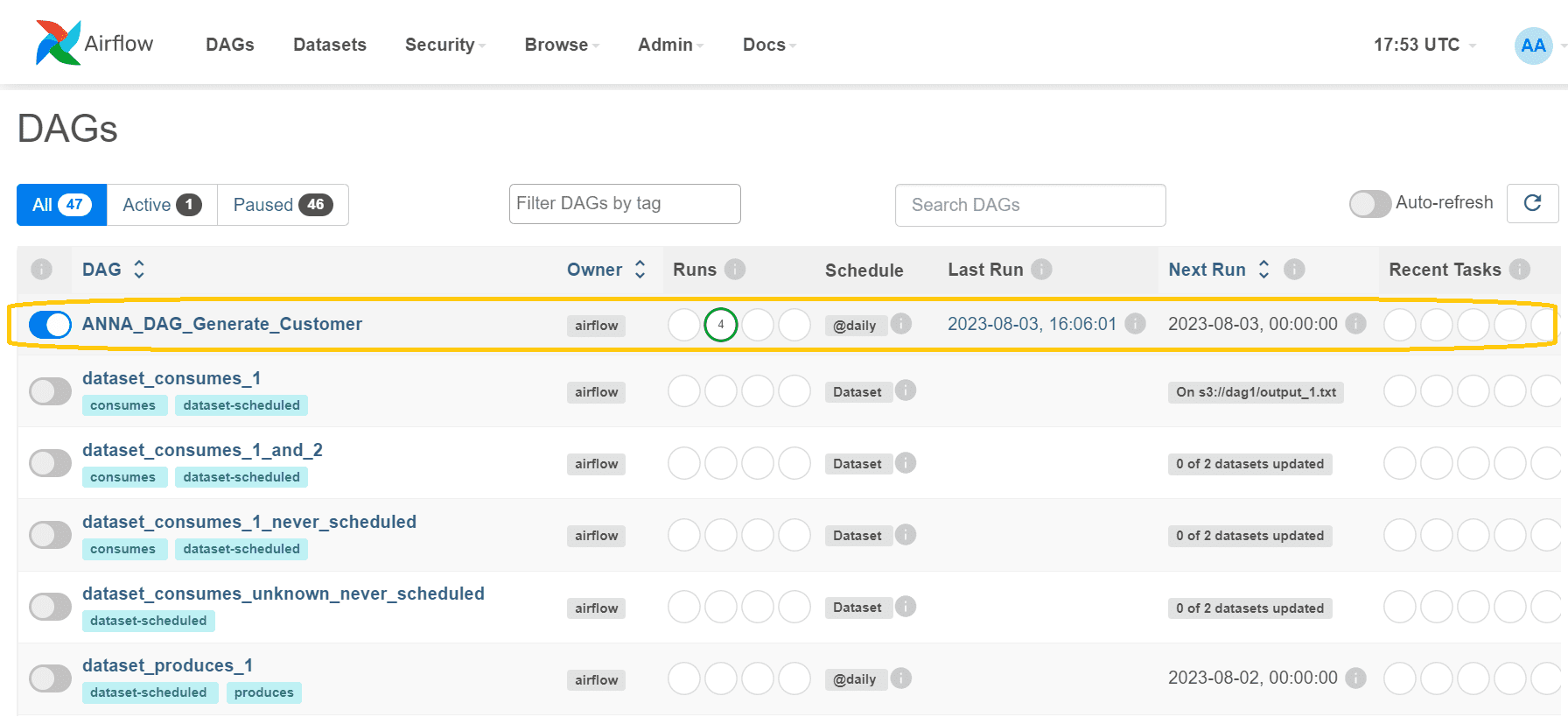
Запустив свой DAG с помощью команды Trigger, можно посмотреть, как каждая задача успешно выполняется. В табличном виде запуски выглядят так:
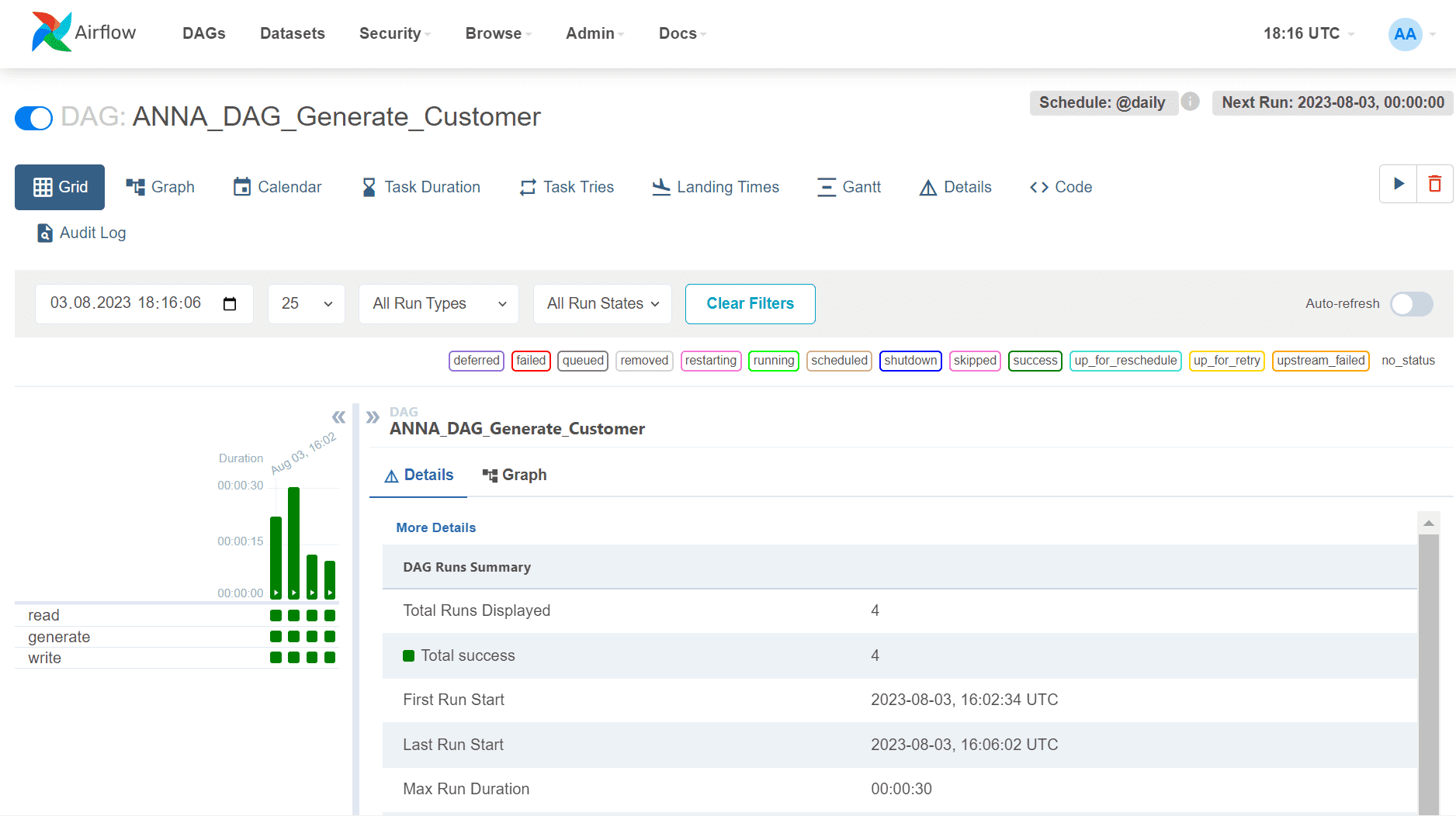
Также доступен сам граф задач.

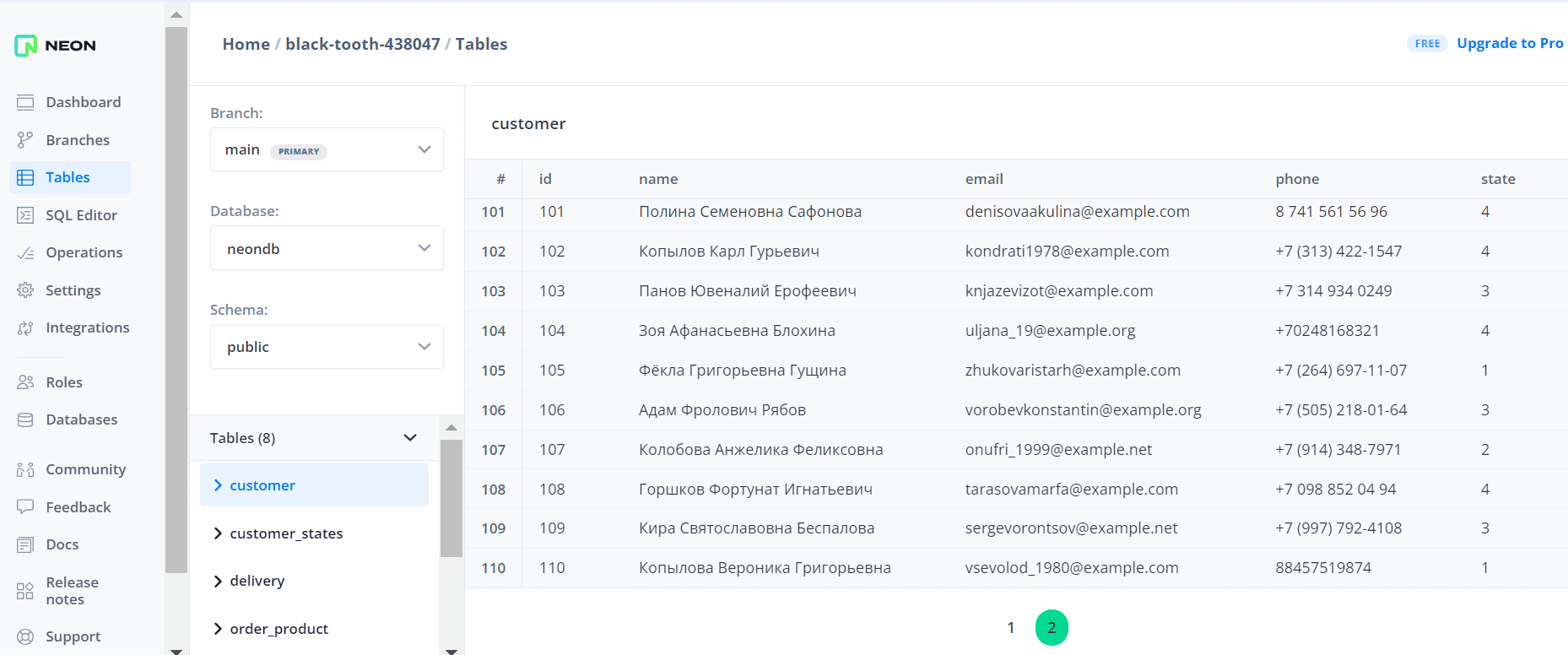
В интерфейсе платформы Neon, где развернут экземпляр PostgreSQL, можно проверить, что новые записи в таблицу успешно добавлены.
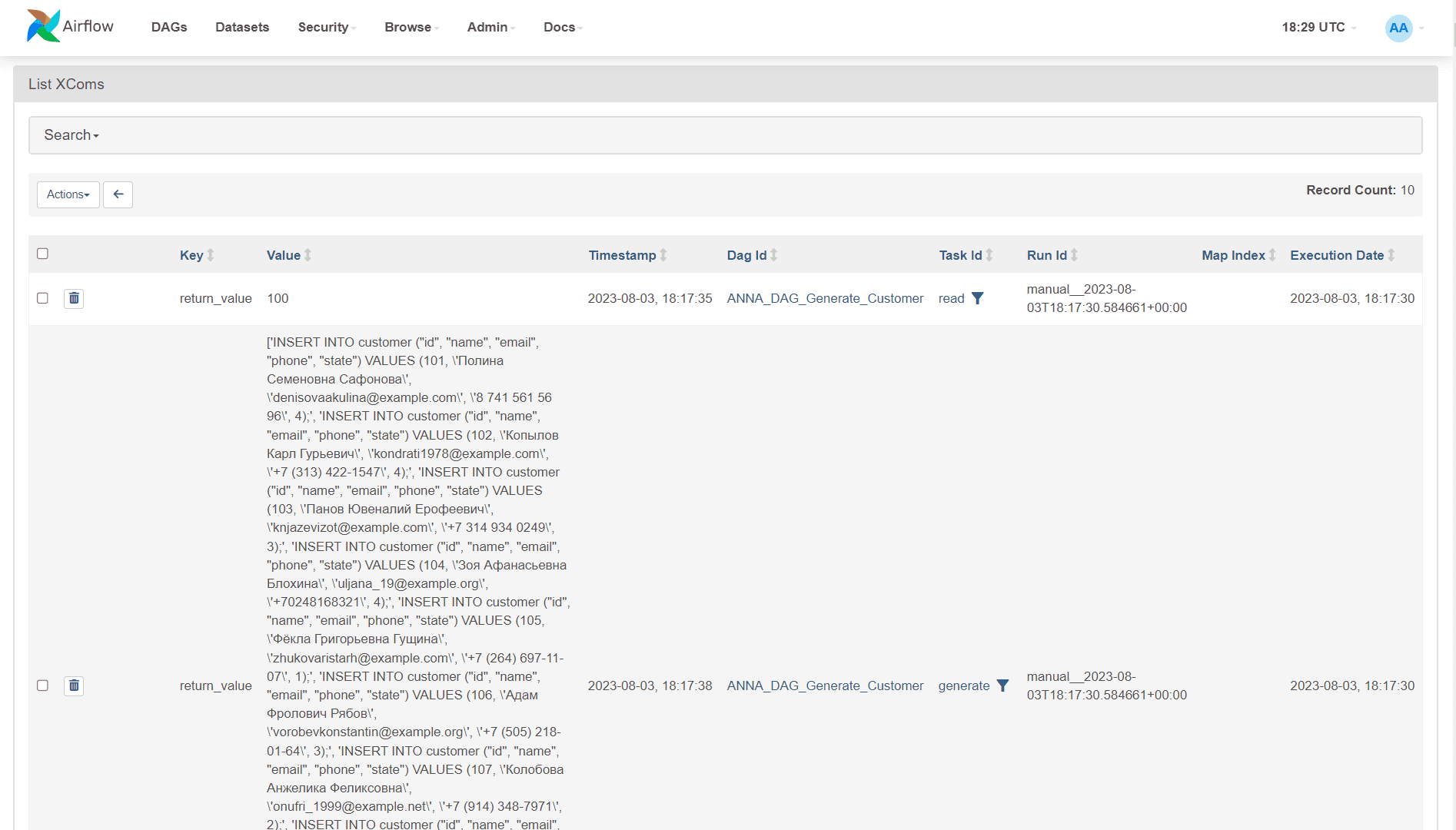
В заключение проверим, как данные между задачами передаются с помощью контекстных переменных, просмотрев список XCom-объектов. В частности, здесь отображается значение количество существующих записей в таблице БД и сгенерированные INSERT-запросы, которые используются для последней задачи DAG.
О том, как удалить из базы старые заказы, предварительно сохранив о них сведения в JSON-файл, читайте в новой статье.
Освойте применение Apache AirFlow для дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

