 1039
1039 
Содержание
Как и большинство Big Data фреймворков, Apache Flink имеет Python API, позволяя разработчикам высоконагруженных потоковых приложений писать код на этом популярном языке программирования. Однако, Flink-задание выполняется в JVM, поэтому сам фреймворк транслирует Python-код в Java. Разбираемся, в чем особенности этого многоступенчатого процесса.
Из Python в Java: как устроен API PyFlink
PyFlink является Python-интерфейсом для Apache Flink, предоставляя пользователям среду для разработки Flink-приложений на Python и их развертывания в кластере Flink. Этот API появился во Flink относительно недавно: в версии фреймворка 1.9, выпущенной в 2019 году. С тех пор сообщество Apache Flink стремится постоянно улучшать PyFlink, выпуская очередные обновления. Сегодня PyFlink включает большинство функций фреймворка, доступных в Java API, а также поддерживает UDF-функции, написанные на Python. Примеры PyFlink-приложений мы приводили здесь и здесь.
Flink предлагает два разных API: процедурный низкоуровневый API потока данных (DataStream) и реляционный/декларативный API таблиц (Table). Они оба могут применяться как для потоковой, так и для пакетной обработки, в т.ч. с помощью Python-кода. Оба API предоставляют множество различных способов определения источников и приемников, и одно Flink-задание может сочетать оба API, например, выполняя преобразование между операциями чтения с помощью функций Table API и записи средствами DataStream API или чтения с DataStream API и записи с Table API. Будучи распределенным вычислительным движком, Flink потребляет данные из внешнего источника и передает их в систему-приемник. Поэтому для любого задания Flink требуется как минимум один источник и приемник данных, соединение с которыми выполняется через коннекторы. Подробнее об API-интерфейсах Flink читайте в нашей новой статье.
Обычно Table API определяет свойства источника/приемника как пары ключ-значение. Все коннекторы Table API следуют этому шаблону. Коннекторы API DataStream более разнообразны и каждый из них предоставляет набор совершенно разных API. Чтобы использовать свой собственный коннектор или тот, который официально не поддерживается в PyFlink, разработчику следует настроить соответствующие пары ключ-значение или написать Python-оболочку для соответствующего API Java.
Сперва пользовательские Python-функции выполняются в отдельных процессах Python, которые запускаются при запуске Flink-задания в кластере. Это довольно неудобно при отладке, поскольку приходится вносить изменения в UDF, чтобы включить удаленную отладку. Начиная с Flink 1.14 пользовательские Python-функции стали выполняться в том же процессе Python на стороне клиента в локальном режиме. Благодаря этому можно устанавливать точки останова в любых местах, и использовать логирование внутри UDF-функций для отладки. При этом сообщения будут отображаться в файле лога менеджеров задач, а не в консоли. Также лог-файл содержит системные метрики пользовательских функций Python, что полезно для долго работающих программ и пригодится для мониторинга статистики и настройки предупреждений.
Выполнение PyFlink-задания фактически состоит из двух основных частей:
- компиляция, когда Python-код преобразуется в JobGraph;
- непосредственное выполнение, когда созданный JobGraph преобразуется в граф операторов Flink, которые выполняются распределенным образом.
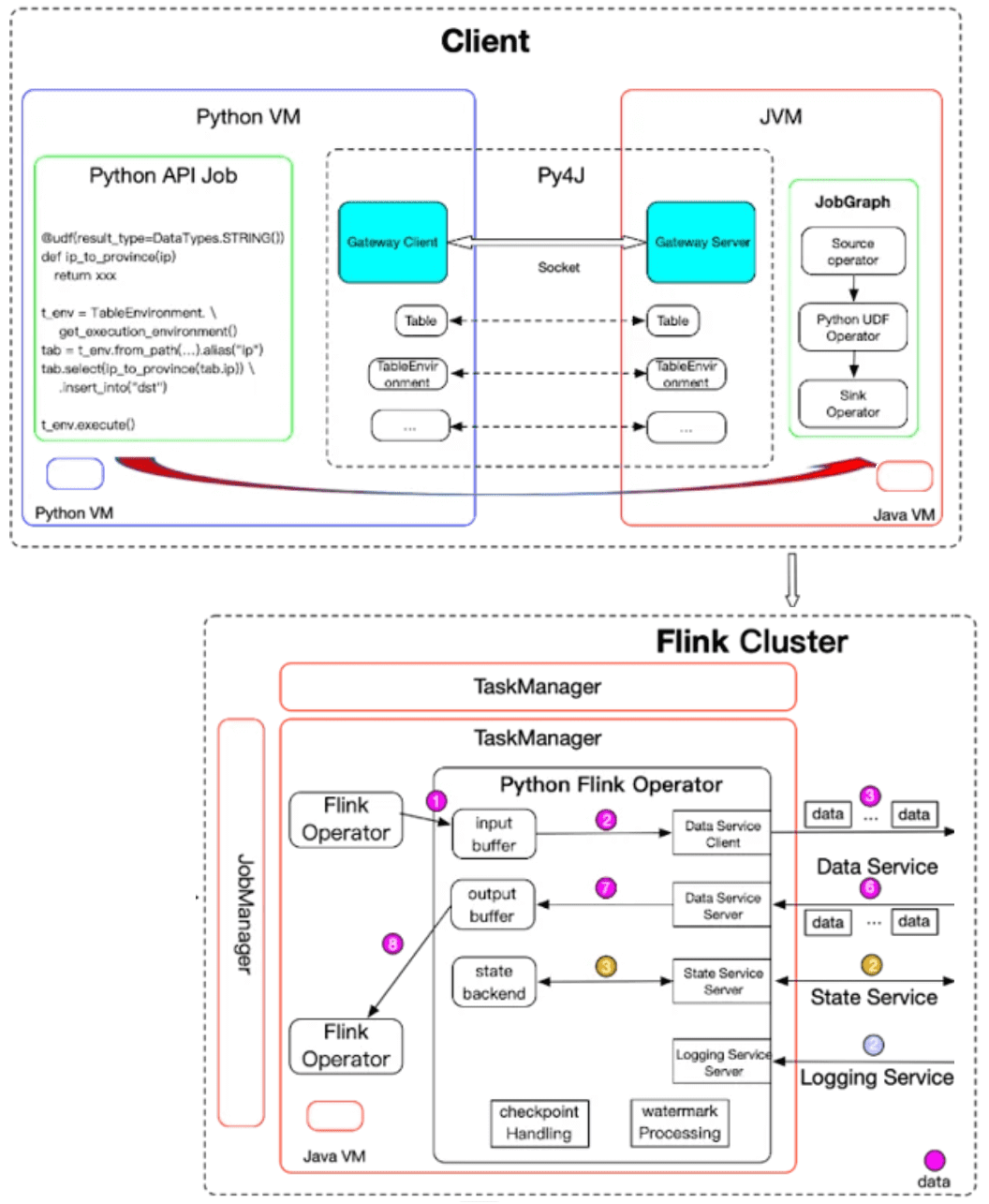
Можно рассматривать JobGraph как протокол между клиентом (Python-приложением) и кластером Apache Flink. Он содержит всю необходимую информацию для выполнения задания: график преобразований, представляющий логику обработки, название и конфигурацию задания, а также все необходимые зависимости Python и JAR-файлы.
В настоящее время JobGraph поддерживает только Java. PyFlink повторно использует существующий стек компиляции заданий Java API, с помощью Java-библиотеки Py4J, которая позволяет динамически взаимодействовать с объектами JVM. Благодаря этому Python-программы, работающие в процессе Python, могут получать доступ к объектам Java в JVM. Методы вызываются так, будто объекты Java находятся в процессе Python. Каждый API Java обернут соответствующим API Python.
Компиляция и выполнение Python-кода в Apache Flink
Когда программа Python вызывает API-интерфейс PyFlink, в JVM создается соответствующий объект Java, и для него вызывается метод. Таким образом, повторно используется тот же стек компиляции заданий, что и Java API. Поэтому при использовании Table API в коде PyFlink и выполнении кода Java, производительность должна быть такой же, как у Java Table API. В случае отсутствия в PyFlink классов, соответствующих классам в Java, например, настраиваемые коннекторы, разработчику придется самостоятельно обернуть его.
На этапе выполнения тоже выполняется аналогичное сопоставление Python-классов с классами Java. В случае лямбда-функций такое соответствие может быть не обнаружено, поэтому придется разработчику сериализовать лямбда-функцию и обернуть ее объектом-оболочкой Java, который порождает процесс Python для его выполнения во время выполнения задания.
Во время выполнения задание Flink состоит из ряда операторов Flink. Каждый оператор принимает входные данные от вышестоящих операторов, преобразует их и выдает выходные данные нижестоящим операторам. Для преобразований, где логикой обработки является Python, будет сгенерирован специальный оператор Python: На этапе инициализации оператор запускает процесс Python и отправляет метаданные, т. е. функции Python, которые должны быть выполнены, в процесс Python. Получив данные от вышестоящих операторов, оператор отправит их процессу Python для выполнения. Данные отправляются в процесс Python асинхронно; оператор не ждет получения результатов выполнения для одного элемента данных перед отправкой следующего. Оператор поддерживает доступ к состоянию Python, но Python-оператор работает в JVM. В отличие от передачи данных, доступ к состоянию является синхронным. Состояние может кэшироваться в процессе Python для повышения производительности. Оператор Python также поддерживает логирование UDF-функций Python. Сообщения отправляются Python-оператору, который работает в JVM, и появляются в файле журнала диспетчеров задач. Функции Python сериализуются во время компиляции задания и десериализуются во время его выполнения. Поэтому не рекомендуется использовать ресурсы, чтобы избежать их постоянной сериализации и десериализации. Вместо этого лучше использовать только сериализуемые переменные экземпляра и функцию open() для инициализации UDF. Это свяжет несколько Python-функций и позволит избежать ненужной сериализации/десериализации, а также накладных расходов на передачу данных по сети.
Запуск функций Python в отдельном процессе работает хорошо в большинстве случаев, но djpvj;ys некоторые исключения. Дополнительные накладные расходы на сериализацию/десериализацию и сетевую передачу данных могут стать проблемой при больших объемах данных, например, в случае обработки изображений или при работе с длинными строками. Взаимодействие между процессами повышает задержку. Кроме того, Python-оператору часто требуется буферизовать данные для повышения производительности сетевой передачи, что также увеличивает задержку. Дополнительный процесс и межпроцессное взаимодействие ухудшают стабильность.
Чтобы решить эти проблемы, в Apache Flink 1.15 введен режим потока в качестве опции для выполнения Python-функций в JVM. По умолчанию режим потока отключен; чтобы использовать его, надо задать конфигурации python.execution-mode значение thread. При включенном режиме потока Python-функции выполняются иначе, чем в режиме процесса: данные обрабатываются по одной строке за раз, что увеличивает задержку. Но исключаются накладные расходы на сериализацию и десериализацию данных, а также их передачу по сети.
Режим потока не включен по умолчанию из-за ограничений: он поддерживает только интерпретатор CPython и зависит от среды выполнения CPython для выполнения Python-кода. Поскольку среда выполнения CPython может быть загружена только один раз в процессе, режим потока не подходит для сеансовой работы, когда для нескольких заданий нужны разные интерпретаторы Python.
Разумеется, API PyFlink можно использовать для создания stateful-приложений с сохранением состояния, доступ к которым поддерживается и для Python-функций. Источником истины для состояния является оператор Python, работающий в JVM. Доступ к состоянию является синхронным с точки зрения пользователя. Для повышения производительности доступа к состоянию возможна асинхронная запись, которая поддерживает кэш LRU последних состояний и изменений состояния, которые асинхронно записываются обратно в оператор Python. Также поддерживается отложенное чтение для MapState, выполняемое только в момент фактического вызова, а не объявления, чтобы избежать ненужных запросов состояния.
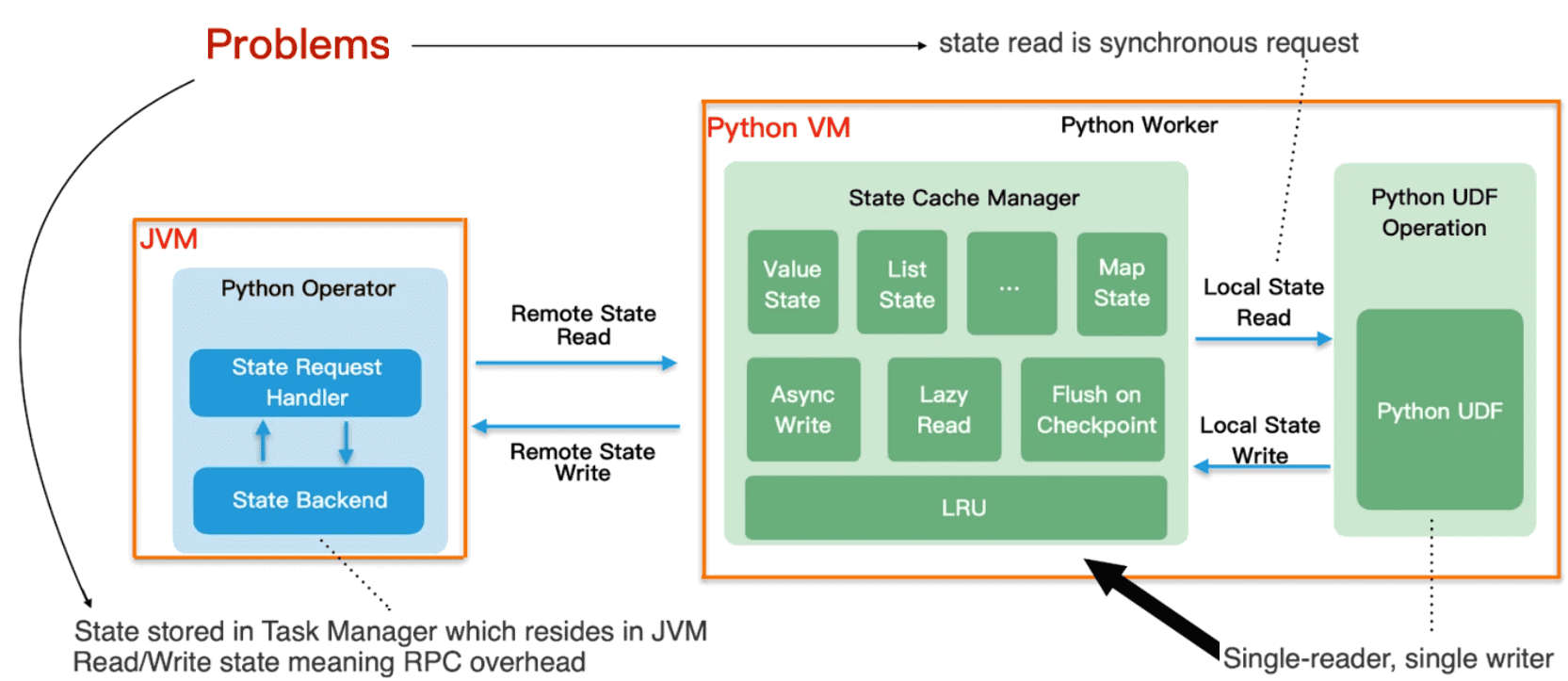
В заключение рассмотрим настройку заданий PyFlink, которая в целом аналогична настройке Flink-заданий Java, кроме оптимизации производительности оператора Python. Поскольку операторы Python запускают отдельный процесс Python для выполнения Python-функций, это может потреблять много памяти при обработке большого объема данных. Если для процесса Python настроено слишком мало памяти, задание может быть нестабильным и потерпеть сбой. Если задание PyFlink запускается в развертывании Kubernetes или Apache YARN, которые строго ограничивают использование памяти, процесс Python может аварийно завершать работу, если его требования к памяти превышают установленный предел. Поэтому разработчику PyFlink-приложения придется тщательно проектировать свой код Python. Также, для дополнительной оптимизации рекомендуется настроить следующие параметры конфигурации для эффективного использования памяти Python:
- memory.process.size — общий объем памяти процесса для TaskExecutors;
- memory.managed.fraction — доля общей памяти, которая будет использоваться в качестве управляемой памяти, к которой также относится память процесса Python;
- memory.jvm-overhead.fraction — доля общей памяти, которая зарезервирована для служебных данных JVM, но не используется явно;
- taskmanager.memory.managed.consumer—weights — управляемые веса памяти для разных типов потребителей. Эту конфигурацию можно использовать для настройки доли управляемой памяти, выделенной процессу Python.
В пакетном режиме оператор Python отправляет данные в процесс Python пакетами. Для повышения производительности сети он буферизует данные перед отправкой. Во время контрольной точки выполняется обработка всех буферизованных данных. Если в пакете много элементов и логика обработки Python неэффективна, время контрольной точки будет увеличено. Поэтому при обнаружении очень длительных или неудачных контрольных точек рекомендуется настроить конфигурацию размера пакета python.fn-execution.bundle.size. Потоковый режим может повысить производительность в случаях, когда размер данных велик или когда нужно уменьшить задержку. Для этого следует установить конфигурацию python.execution-mode в значение thread. Подробнее об этом режиме выполнения пользовательских Python-функций в JVM смотрите здесь.
Читайте в нашей новой статье про возможности взаимодействия Apache Flink с локальными и удаленными файловыми системами.
Узнайте больше про использование Apache Flink для потоковой обработки событий в распределенных приложениях аналитики больших данных и машинного обучения на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

