 881
881 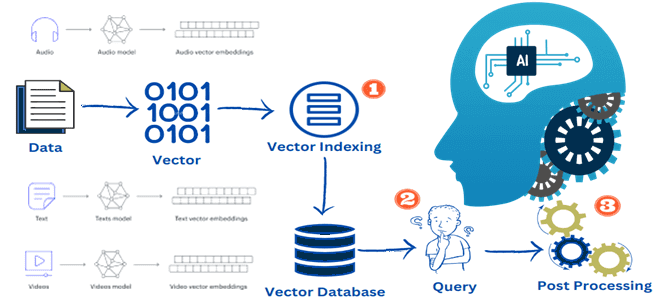
Как устроены векторные базы данных и почему они стали так популярны с распространением ИИ. Архитектура, алгоритмы, принципы работы и примеры векторных СУБД.
Что такое векторная СУБД и при чем здесь ИИ
Как и следует из названия, векторная база хранит данные в виде векторов. Это понятие из математики означает специализированное представление объектов в пространстве и представляет собой одномерную структуру данных, кортеж из одного или нескольких значений. Векторы являются основой линейной алгебры и используются в Data Science при описании целевой переменной для реализации модели машинного обучения. Благодаря своему одномерному характеру, векторное представление обучающих характеристик для ML-модели, т.н. фичей, занимает меньше места в памяти, что особенно важно для современных ИИ-приложений, от которых пользователей ожидает оперативного ответа. Именно распространение ИИ, особенно связанное с появлением генеративных нейросетей (ChatGPT и пр.) в конце 2022 г. и их внедрением в различные сферы деятельности, стимулировало интерес к векторным СУБД.
Большие языковые модели, генеративный ИИ и семантический поиск основаны на векторном встраивании, типе представления данных, которое несет семантическую информацию для понимания контекста и поддержке долговременной памяти. Встраивания (embedding) генерируются ИИ-моделями ИИ и имеют очень много атрибутов (фичей), которые представляют различные измерения данных, нужные для понимания закономерностей, взаимосвязей и лежащих в их основе структур. Чтобы эффективно управлять такими данными, нужен специализированный инструмент, которым и стали векторные СУБД.
Векторные базы данных оптимизированы для хранения векторных встраиваний и запросов к ним. Традиционные скалярные базы данных не могут справиться со сложностью и масштабом векторных данных в реальном времени. А векторные базы данных специально разработаны для обработки данных такого типа и обеспечивают производительность, масштабируемость и гибкость, необходимые для максимально эффективного использования данных, в т.ч. в ИИ-приложениях. Они могут быстро и точно искать похожие элементы и анализировать огромные объемы данных, отлично масштабируются и подходят для использования в любом домене. Подробнее о том, как RAG-приложения позволяют дообучить LLM с использованием векторного встраивания, читайте в нашей новой статье. А про графовый RAG для LLM и систем агентского ИИ мы рассказываем здесь.
Как работает векторная база данных
Последовательность применения векторной СУБД в ИИ-приложении можно представить таким образом:
- для создания векторных вложений контента, который надо проиндексировать, используется модель встраивания (embedding model);
- встраивание вектора вставляется в векторную базу данных со ссылкой на исходный контент, из которого было создано встраивание;
- когда приложение выдает запрос, используется ранее определенная модель встраивания для создания встраиваний для запроса к векторной базе данных похожих вложений, которые, в свою очередь, связаны с другим исходным контентом.
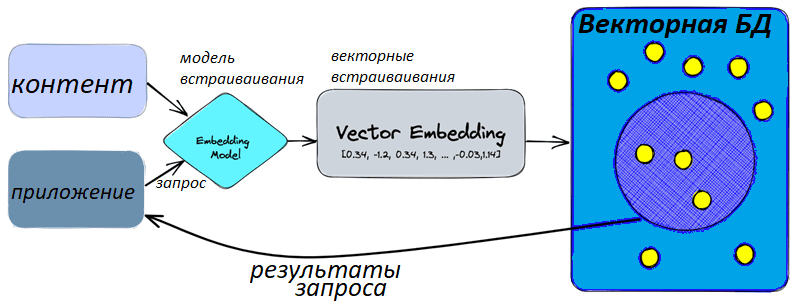
Примечательно, что векторные БД могут предотвращать «галлюцинации» генеративных ИИ-моделей, когда чат-бот несет правдоподобный бред. Для этого векторные базы данных объединяются с генеративными ИИ-моделями для создания интеллектуальных агентов, которые обеспечивают диалоговый поиск различного характера: текстовый, визуальный, семантический и мультимодальный. В этом случае процесс разработки начинается с создания модели встраивания, предназначенной для кодирования корпуса, например, изображение объекта, в векторы. После наполнения (импорта) данных разработчик ИИ-приложения может использовать векторную базу для поиска похожих объектов, кодируя его изображение и применяя вектор, чтобы выполнить запрос похожих изображений. Для этого часто применяется алгоритмы поиска k-ближайшего соседа (kNN), о которых мы писали здесь, обеспечивая эффективное извлечение векторов с ранжированием результатов по сходству на основе значения функции расстояния, например, косинус или евклидова мера.
В традиционных базах данных запрос возвращают строки, значения которых точно ему соответствует. В векторных базах данных используется метрика подобия, чтобы найти вектор, наиболее похожий на запрос. Для этого используется комбинация различных алгоритмов, которые участвуют в поиске по методу приближенного ближайшего соседа (ANN). Эти алгоритмы оптимизируют поиск с помощью хеширования, квантования или поиска на основе графа. Алгоритмы собраны в конвейер, обеспечивающий быстрый и точный поиск соседей запрашиваемого вектора. В общем случае такой конвейер включает следующие этапы:
- индексация, когда векторная СУБД индексирует векторы с использованием таких алгоритмов, как квантование произведения (PQ), хеширование с учетом местоположения (LSH) или иерархические навигационные графы малого мира (HNSW). На этом шаге векторы сопоставляются со структурой данных, чтобы ускорить поиск.
- запрос, когда векторная СУБД сравнивает индексированный вектор запроса с индексированными векторами в датасете, чтобы найти ближайших соседей с использованием меры сходства для этого индекса.
- постобработка, когда векторная СУБД извлекает окончательных ближайших соседей из набора данных и обрабатывает их для получения окончательных результатов, применяя повторное ранжирование ближайших соседей с использованием другой меры сходства.

Поскольку векторная база данных предоставляет приблизительные результаты, точность и скоростью поиска являются главными критериями оценки эффективности этого решения. Однако, чем точнее результат, тем медленнее будет запрос. Следует искать компромисс, который будет удовлетворять требованиям пользователей. Впрочем, многие современные векторные СУБД уже могут обеспечить сверхбыстрый поиск с почти идеальной точностью.
Поскольку векторные базы данных используются в ИИ-приложениях, они должны быть отказоустойчивыми, надежными и быстро реагировать на запросы в условиях высокой нагрузки. Для этого большинство векторных СУБД поддерживают репликацию и шардирование, имеют развитые средства мониторинга и резервного копирования. Также, для удобства разработчиков ИИ-приложений, многие векторные СУБД предоставляют гибкий API и SDK. Для обеспечения информационной безопасности используются различные механизмы контроля доступа.
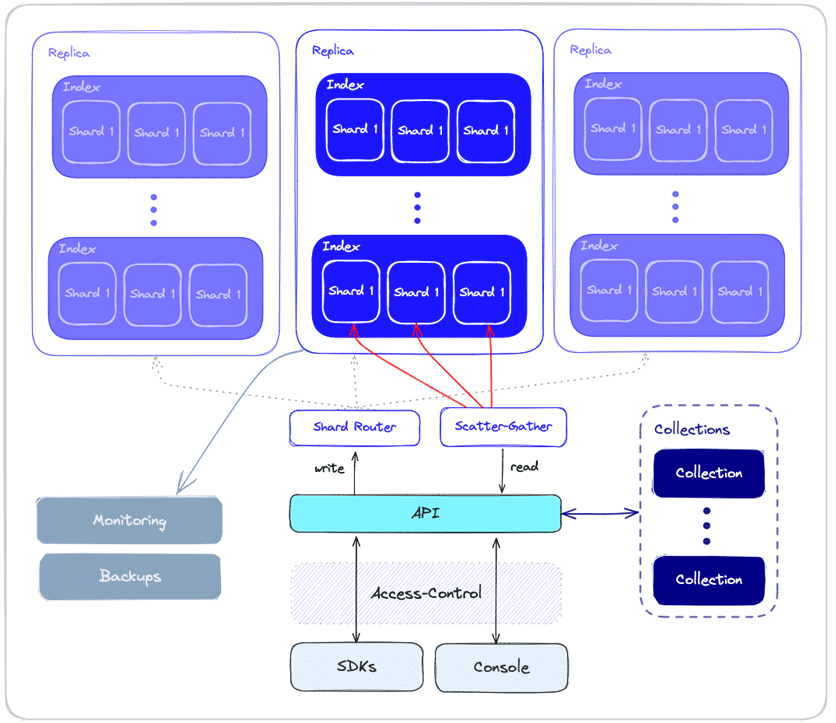
В заключение перечислим наиболее зрелые на сегодня векторные СУБД: Pinecone, Milvus, Weaviate, Enterprise-редакция key-value базы Redis, SingleStore, Relevance AI, Qdrant, Vespa и др. Впрочем, используя специальные плагины, можно даже PostgreSQL и Greenplum превратить в векторную базу данных, о чем мы рассказываем в новой статье.
Узнайте больше про современные архитектуры данных в проектах дата-инженерии и аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

