 1168
1168 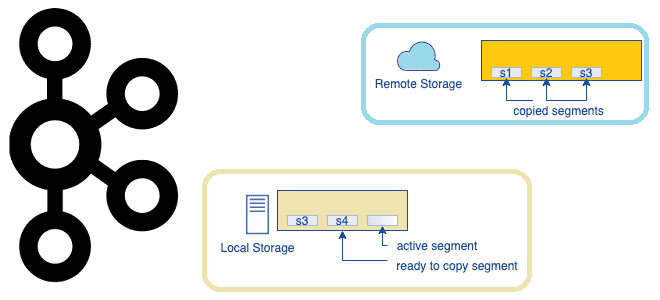
Содержание
Что представляет собой очередное предложение по улучшению проекта Apache Kafka, которое расширяет возможности этой распределенной платформы потоковой передачи событий, превращая ее в средство долговременного хранения данных.
Надежность vs скорость: вечный компромисс в Apache Kafka
Изначально Apache Kafka позиционировалась как middleware, т.е. сервисный слой для асинхронной интеграции нескольких информационных систем. Этот архитектурный паттерн не предполагает длительного хранения данных, отправленных приложением-продюсером в топик. Однако, в отличие от JMS-брокеров, которые обычно удаляют сообщение из очереди после его доставки приложению-потребителю, Kafka всегда пишет данные на жесткий диск брокера и хранит их в топике до тех пор, пока не будет достигнут его лимит емкости или не истечет время хранения, заданное в конфигурации retention. Подробнее об этом мы писали здесь.
Топик в Apache Kafka представляет собой не физическое, а логическое хранение данных, которое делится на разделы, состоящие из сегментов. Сообщение, опубликованное приложением-продюсером в топик Kafka, добавляется в конец лога и остается в нем, пока не будет достигнут предельный размер лога или не наступит время его сжатия/удаления согласно политике очистки, заданной в конфигурации log.cleanup.policy. По умолчанию сегменты лога хранятся неделю, что мы разбирали в этом материале.
Чтобы обеспечить долговременное хранение данных, необходимо реализовать конвейер их копирования из топиков в масштабируемое внешнее хранилище для долгосрочного использования, например HDFS. Это приводит к тому, что потребителям данных приходится создавать разные версии приложений для использования данных из разных систем в зависимости от возраста данных. Что касается кратковременного хранения, само хранилище кластера Kafka масштабируется путем добавления в кластер дополнительных узлов-брокеров. Такое горизонтальное масштабирования повышает общую стоимость эксплуатации кластера.
Когда брокер выходит из строя, отказавший узел заменяется новым, который должен скопировать все данные с отказавшего из других реплик. Аналогично, при добавлении нового узла в в кластер Kafka, происходит перебалансировка, новому узлу назначаются разделы, что обычно требует времени из-за копирования большого количества данных. Время восстановления и повторной балансировки пропорционально объему данных, хранящихся локально на брокере Kafka. В кластере на сотни брокеров, часто случаются сбои локальных узлов, и на восстановление их работоспособности уходит много времени, что снижает общую пропускную способность платформы.
Сократить время восстановления и перебалансировки можно, уменьшив объем данных, хранящихся на каждом брокере. Но это также потребует сокращения периода хранения журналов, что влияет на время, доступное для обслуживания приложений и восстановления после сбоев. В локальных развертываниях Kafka часто используются диски большой емкости, чтобы повысить пропускную способность ввода-вывода и хранить данные в течение периода хранения. Чтобы достичь компромисса между высокой пропускной способностью и длительным периодом хранения, еще в декабре 2018 года было предложена идея многоуровневого хранилища для Kafka, оформленная в виде KIP (Kafka Improvement Proposal) – предложения по улучшению этого проекта. Разбираемся, что оно собой представляет.
KIP-405: идея и проектирование
Данные Kafka в основном потребляются в потоковом режиме чтения с хвоста, которое использует кэш страниц операционной системы для обслуживания данных вместо чтения с диска. Старые данные обычно считываются с диска для обратной засыпки или восстановления после сбоя, и это происходит нечасто. При многоуровневом подходе к хранилищу кластер Kafka настраивается с двумя уровнями хранения: локальным и удаленным. Локальный уровень остается прежним, используя локальные диски брокеров Kafka для хранения сегментов журнала. Новый удаленный уровень использует внешние надежные системы, такие как HDFS или S3, для хранения завершенных сегментов журнала. Для каждого из уровней определены два отдельных периода хранения. При включенном удаленном уровне период хранения для локального уровня может быть значительно сокращен с нескольких дней до нескольких часов. Период хранения для удаленного уровня, наоборот, намного дольше: дни или даже месяцы. При свертывании сегмента журнала на локальном уровне он копируется на удаленный уровень вместе с соответствующими индексами. Чувствительные к задержке приложения выполняют чтение с хвоста и обслуживаются с локального уровня, используя существующий механизм Kafka использования кэша страниц для обслуживания данных. Заполнение и другие приложения, восстанавливающиеся после сбоя, которым требуются данные старше, чем те, что находятся на локальном уровне, обслуживаются с удаленного уровня.
Такое решение позволяет масштабировать хранилище независимо от памяти и ЦП в кластере Kafka, превращая эту платформу потоковой передачи событий в действительно источник истины для интеграционного обмена за счет долгосрочного хранения событий. Это также уменьшает объем данных, хранящихся локально на брокерах Kafka, и объем данных, которые необходимо копировать во время восстановления и повторной балансировки. Сегменты журнала, доступные на удаленном уровне, не нужно восстанавливать на брокере, и они обслуживаются с удаленного уровня. При этом увеличение срока хранения больше не требует масштабирования хранилища кластера Kafka и добавления новых узлов. В то же время общее хранение данных может продолжаться намного дольше, что устраняет необходимость в отдельных конвейерах данных для копирования из Kafka во внешние хранилища.
Реализация KIP-405 предполагает добавление нового компонента — RemoteLogManager (RLM), который получает события обратного вызова для смены лидера и события остановки/удаления разделов топика на брокере. RLM делегирует копирование, чтение и удаление сегментов раздела топика подключаемому диспетчеру хранилища (RemoteStorageManager) и поддерживает соответствующие метаданные удаленного сегмента журнала через RemoteLogMetadataManager. RemoteLogManager — это внутренний компонент, а не общедоступный API, а RemoteStorageManager — это интерфейс, обеспечивающий жизненный цикл удаленных сегментов журнала и индексов. Реализация HDFS и S3 размещается во внешних репозиториях вне проекта Apache Kafka, аналогично подходу, используемому для коннекторов. RemoteLogMetadataManager представляет собой интерфейс для обеспечения жизненного цикла метаданных об удаленных сегментах журнала со строго последовательной семантикой. Реализация по умолчанию использует внутренний топик, но пользователи могут подключить свою собственную реализацию, чтобы использовать другую систему для хранения метаданных удаленного сегмента журнала.
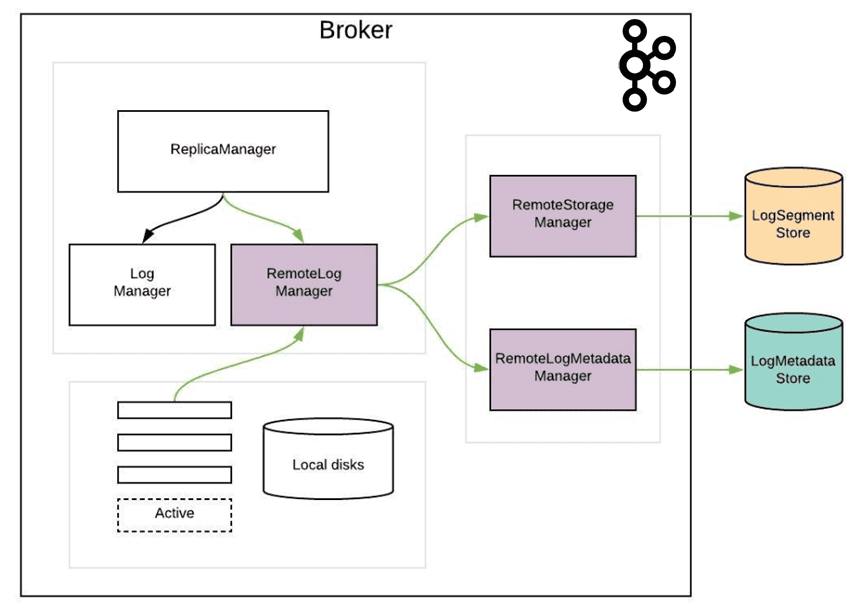
RLM создает задачи для каждого раздела топика. Лидер RLM проверяет пролонгированные сегменты журнала, у которых смещение последнего сообщения меньше, чем последнее стабильное смещение этого раздела топика, и копирует их вместе с их индексами смещения/времени/транзакции/моментального снимка продюсера и кэшем эпохи лидера на удаленный уровень. Также RLM обслуживает запросы на выборку старых данных с удаленного уровня. Локальные журналы не очищаются до тех пор, пока эти сегменты не будут успешно скопированы на удаленный сервер, даже если их время/размер хранения достигнуты. Подписчики RLM отслеживают сегменты и индексные файлы на удаленном уровне, просматривая RemoteLogMetdataManager. Также подписчик RLM может обслуживать чтение старых данных с удаленного уровня. RLM поддерживает ограниченный кэш индексных файлов удаленных сегментов журнала, чтобы избежать множественных выборок индекса из удаленного хранилища. Они хранятся в папке remote-log-index-cache в каталоге журнала. Эти индексы можно использовать так же, как и индексы локальных сегментов. В частности, настроить конфигурацию remote.log.index.file.cache.total.size.mb, чтобы установить общий размер, который можно использовать для этих индексных файлов.
Предыдущий подход состоит в извлечении метаданных удаленного сегмента журнала из API-интерфейсов удаленного хранилища журналов, как упоминалось в предыдущем разделе RemoteStorageManager_Old . Этот подход отлично работал для таких хранилищ, как HDFS. Одна из проблем использования удаленного хранилища для поддержки метаданных заключается в том, что многоуровневое хранилище должно быть строго согласованным, с влиянием не только на сами метаданные (например, LIST в S3), но и на данные сегмента (например, GET после DELETE). Кроме того, необходимо учитывать стоимость (и, в меньшей степени, производительность) хранения метаданных в удаленном хранилище. В случае с S3 частые API-интерфейсы LIST требуют огромных затрат. Удаленное хранилище отделено от хранилища метаданных удаленного журнала, чтобы обеспечить согласованность метаданных как между собой, так и с данными сегмента. Причем это должно быть универсальным решением для всех распределенных файловых и объектных хранилищ. Например, API-вызовы к HDFS работают быстро, но в случае с S3 частые вызовы LIST, чтобы перечислить набор объектов в каталоге, требуют огромных затрат. Поэтому KIP-405 предполагает введение RemoteStorageManager и RemoteLogMetadataManager.
Практическая реализация
KIP-405 реализован и доступен в Kafka 3.6 как функция раннего доступа, рекомендуемая для тестирования в непроизводственных средах, о чем мы рассказываем здесь. Помимо этого, некоторые провайдеры представляют собственную реализацию этого улучшения. Например, в Amazon MSK есть внутренняя функция многоуровневого хранилища поверх официальной версии Kafka 2.8.2 в рамках специального релиза AWS 2.8.2.tiered Kafka.
На платформе Confluent тоже есть подобная возможность начиная с версии 6.0, о чем мы рассказываем здесь. Однако, до версии Confluent Platform 6.0.1 многоуровневое хранилище нельзя было отключить после его включения. С версии Confluent Platform 6.0.1 и позже многоуровневое хранилище можно отключить. Включение многоуровневого хранилище выполняется с помощью установки набора конфигураций, например, для AWS это выглядит так:
confluent.tier.feature=true confluent.tier.enable=true confluent.tier.backend=S3 confluent.tier.s3.bucket=<BUCKET_NAME> confluent.tier.s3.region=<REGION>
Эти конфигурации можно задавать прямо при создании топика с помощью команды CLI-интерфейса create. При этом не рекомендуется не устанавливать политику хранения в облачном хранилище, например, в корзине AWS S3, поскольку это может противоречить ранее установленной политике хранения топика Kafka. Примечательно, что одна и та же корзина должна использоваться во всех брокерах в кластере с многоуровневым хранилищем. Это относится ко всем поддерживаемым платформам.
Реализации Kafka, поддерживаемые в различных платформах предлагают ряд рекомендаций по повышению эффективности многоуровневого хранилища. В частности, Confluent советует увеличить значение конфигураций TierFetcherNumThreads и TierArchiverNumThreads, чтобы повысить производительность многоуровневого хранилища. Также можно задать собственный интервал, в течение которого происходит удаление этих файлов, в параметре confluent.tier.topic.delete.check.interval.ms, по умолчанию равном 3 часа. Также рекомендуется уменьшить конфигурацию размера сегмента log.segment.bytes для топиков с включенным разделением по уровням. По молчанию этот размер равен 1 ГБ. Архиватор ожидает закрытия сегмента журнала, прежде чем пытаться загрузить его в хранилище объектов. Использование сегмента меньшего размера, например 100 МБ, позволяет сегментам закрываться чаще. Загрузка меньшего по размеру файла занимает меньше времени, а также улучшает поведение кэша страниц, повышая производительность архиватора.
В заключение отметим, что многоуровневое хранилище не заменяет ETL-конвейеры и задания извлечения, преобразования и загрузки данных. Раздел, для которого конфигурация remote.storage.enable установлена в значение true, не может изменить свою политику очистки с удаления на сжатие. А, чтобы лучше отслеживать производительность, устранять и предотвращать проблемы с многоуровневым хранилищем Kafka, в выпуске 3.7 поддерживаются дополнительные метрики этой функции.
Впрочем, хотя многоуровневое хранилище может сократить некоторые расходы на хранение за счет выгрузки холодных данных неактивных сегментов в объектное хранилище, пользователям по-прежнему необходимо выделять значительное локальное дисковое пространство для горячих данных и обработки пиковых нагрузок. Это означает, что высокие затраты на облачные диски сохраняются, а плата за сетевой трафик (особенно в зонах доступности) остается основной статьей расходов. Поэтому в 2025 году компания Aiven, которая является провайдером Kafka как сервиса, а также предоставляет еще множество других систем, предложила KIP-1150, чтобы сократить расходы на инфраструктуру, записывая данные непосредственно в недорогое объектное хранилище вместо репликации от брокера к брокеру и асинхронной записи на локальные диски. Подробнее об этом читайте в нашей новой статье.
Освойте администрирование и эксплуатацию Apache Kafka для потоковой аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

