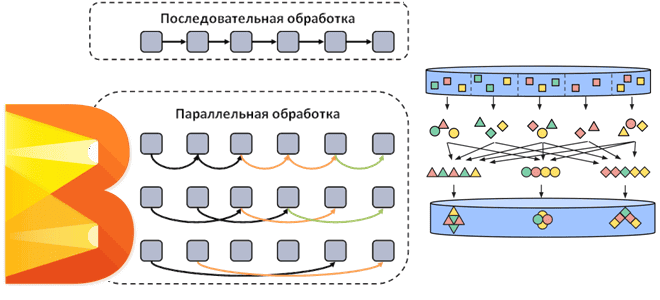
Как Apache Beam распараллеливает потоковые и пакетные конвейеры обработки данных, добавляя собственные операции к пользовательским преобразованиям. Смотрим на примере простого пакетного конвейера с ограниченным параллелизмом. Распараллеливание операций в Apache Beam Напомним, Apache Beam представляет собой унифицированную модель определения пакетных и потоковых конвейеров параллельной обработки данных, которую можно запустить в любой...

Мы уже писали о том, как Trino работает с удаленными объектными хранилищами и файловыми системами. Сегодня поговорим о том, какие изменения выпущены в февральском релизе 2025 года, почему в Trino удалена поддержка доступа к Azure Storage, Google Cloud Storage, S3 и S3-совместимым файловым системам через Hive и что использовать вместо...

7 февраля 2025 года вышел очередной релиз ClickHouse. Знакомимся с его главными новинками: ускорение параллельного хэш-соединения, индексы MinMax на уровне таблицы, автоинкременты полей и улучшенное объединение таблиц с табличной функцией merge. Улучшение параллельного хэш-соединения в ClickHouse 25.1 В ClickHouse 25.1 добавлено 15 новых функций, 36 улучшений и 77 исправлений ошибок....
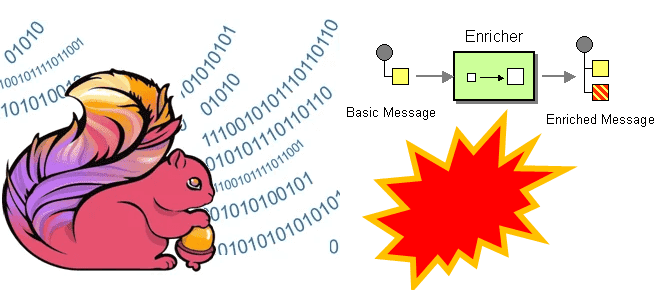
Как FLIP-304 помогает понять причину сбоя и повысить надежность Flink-приложения: обогащение типовых сообщений об ошибках пользовательскими метаданными. Зачем нужен FLIP-304 и как это позволяет дополнять сообщения об ошибках при сбоях заданий Apache Flink Хотя Apache Flink имеет встроенные механизмы обеспечения отказоустойчивости, такие как контрольные точки и точки сохранения, а также...

Особенности хранения и аналитической обработки JSON-документов в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL: объяснение бенчмаркингового теста. JSON в ClickHouse Недавно мы писали про бенчмаркинговое сравнение хранения и обработки JSON-данных в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL. В этом тесте, проведенном самими разработчиками ClickHouse, эта СУБД показала максимальную эффективность, которая обоснована...

Почему ClickHouse требует меньше места для хранения JSON-документов и быстрее выполняет аналитические запросы к ним по сравнению с MongoDB, Elasticsearch, DuckDB и PostgreSQL: бенчмаркинговый тест от разработчиков колоночной СУБД. Как Clickhouse делает быстрее агрегации в JSON-данных Хотя бенчмаркинговые тесты от вендоров редко бывают объективными, просматривать их довольно интересно. Недавно мне...
Почему Trino не заменит Flink, Spark и Airflow: границы применимости MPP-движка распределенного выполнения SQL-запросов к реляционным и нереляционным источникам данных. Почему Trino не заменит Flink, Spark и Airflow Хотя Trino отлично подходит для быстрой ad-hoc аналитики, позволяя SQL-запросами в реальном времени обращаться к различным базам данных, включая нереляционные хранилища и...

Как устроен механизм отказоустойчивого выполнения в Trino, чем политика повтора QUERY отличается от TASK, зачем настраивать диспетчер обмена на внешнее S3-совместимое хранилище и задавать коэффициент задержки перед повторными попытками выполнить SQL-запрос. 2 политики отказоустойчивого выполнения в Trino Будучи движком online-обработки больших объемов данных с помощью распределенных SQL-запросов, Trino должен иметь...
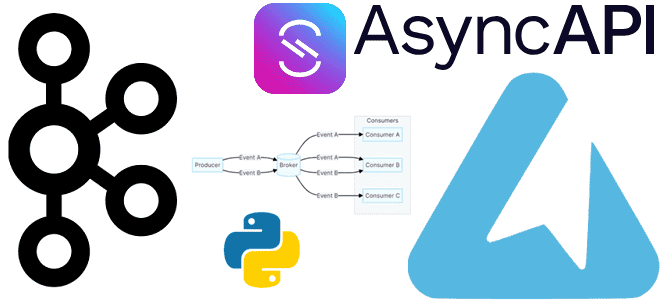
Как получить спецификацию AsyncAPI из кода с помощью декораторов функций публикации и потребления сообщений средствами Python-библиотеки FastStream: простой пример потокового конвейера на Apache Kafka. Еще раз про FastStream и спецификацию AsyncAPI Вчера я рассказывала про Python-библиотеку FastStream для разработки потоковых конвейеров на Apache Kafka, RabbitMQ, NATS и Redis. Помимо мощного,...

Чем хороша Python-библиотека FastStream и как ее использовать для потоковой публикации данных в Apache Kafka: практический пример асинхронной отправки JSON-сообщений. О библиотеке FastStream Для Python-разработчиков есть довольно много библиотек, позволяющих взаимодействовать с Apache Kafka: kafka-python, confluent-kafka, Quix Streams и другие клиенты. О сравнении kafka-python и confluent-kafka я писала здесь, а...