 142
142 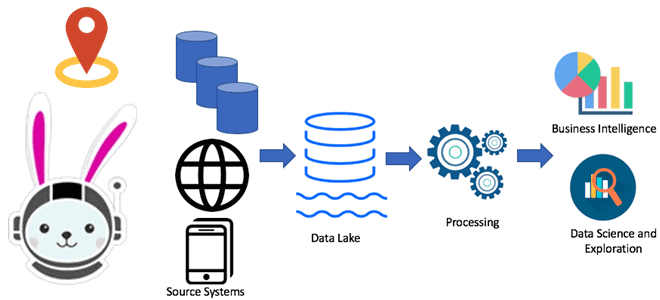
Почему Trino не заменит Flink, Spark и Airflow: границы применимости MPP-движка распределенного выполнения SQL-запросов к реляционным и нереляционным источникам данных.
Почему Trino не заменит Flink, Spark и Airflow
Хотя Trino отлично подходит для быстрой ad-hoc аналитики, позволяя SQL-запросами в реальном времени обращаться к различным базам данных, включая нереляционные хранилища и потоковые платформы, он не заменит Flink, Spark и Airflow. Это обусловлено разницей в назначении и различными границами применимости.
Прежде всего, Trino ориентирован на аналитические запросы (OLAP) к уже существующим данным во внешних хранилищах, обеспечивая их агрегацию. Apache Flink и Spark представляют собой фреймворки для разработки распределенных аналитических приложений над большими объемами данных, включая пакетную и потоковую обработку, машинное обучение и графовые вычисления. Они поддерживают stateful-вычисления и оконную агрегацию с высокой отказоустойчивостью благодаря сохранению состояния. Flink и Spark предлагают собственные механизмы для обработки данных, которые выходят за рамки просто выполнения SQL-запросов, включая поддержку различных типов вычислений и интеграцию с разнообразными внешними системами. Trino работает в пакетной парадигме, не имея встроенных средств оркестрации заданий и сложной обработки потоковых данных.
Несмотря на возможность определить параметры повторного выполнения неудачных запросов, в Trino отсутствуют возможности автоматизированного запуска рабочих нагрузок, которые есть в Apache Airflow – мощном оркестраторе рабочих пакетных процессов. Поэтому Airflow необходим в дата-инженерии для автоматизации и управления последовательностями задач, обеспечивая их выполнение в нужном порядке и с необходимыми зависимостями.
Таким образом, место Trino в конвейере обработки и визуализации данных – это так называемая «последняя миля» перед BI-системами и дашбордами для конечных пользователей, выступая в качестве источника данных.
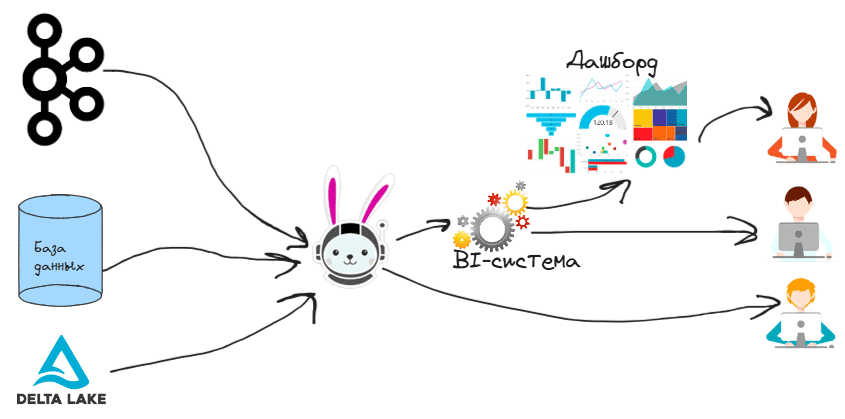
Технологически интеграция Trino с BI-системами осуществляется путем подключения через JDBC- и ODBC-драйверы. Большинство BI-инструментов (Tableau, Power BI, Looker, и пр.) поддерживают подключение к различным базам данных и движкам обработки данных через стандартные драйверы JDBC или ODBC. Trino предоставляет собственные JDBC- и ODBC-драйверы, которые позволяют BI-системам устанавливать соединение с этим MPP-движком как с источником данных. После настройки подключения BI-система может отправлять SQL-запросы к Trino, который обращается к внешним источникам данных, обрабатывает запрос и возвращает результаты для визуализации. Для оптимальной работы BI-систем с Trino рекомендуется настраивать параметры подключения, учитывая особенности нагрузки и требований к производительности.
Благодаря наличию механизмов аутентификации и авторизации в Trino можно ограничить доступ BI-инструментов к определенным данным или операциям, чтобы обеспечить их безопасность. А масштабируемость и распределенная MPP-архитектура движка позволяет BI-системам эффективно работать с большими объемами данных без значительных задержек, обеспечивая плавное взаимодействие и быстрые ответы на ситуативные запросы пользователей. Таким образом, Trino может использоваться как мощное средство интеграции между различными источниками данных и BI-системами, обеспечивая гибкую, масштабируемую и эффективную платформу для анализа и визуализации данных.
Однако, в такой архитектуре с использованием Trino стоит помнить об ограниченных возможностях этого движка для масштабных ETL-процессов. Хотя в целом Trino хорошо справляется с ad-hoc запросами, он не предназначен для сложных ETL-операций и потоковой обработки. Для решения этих задач как раз и могут пригодиться Flink или Spark, а также Airflow. Кроме того, не все коннекторы обеспечивают одинаковую производительность и надежность. В частности, некоторые источники данных не поддерживают режим отказоустойчивого выполнения, что мы разбирали вчера.
Подробнее познакомиться с Trino, Flink, Spark и Airflow вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

