 1049
1049 
Почему ClickHouse требует меньше места для хранения JSON-документов и быстрее выполняет аналитические запросы к ним по сравнению с MongoDB, Elasticsearch, DuckDB и PostgreSQL: бенчмаркинговый тест от разработчиков колоночной СУБД.
Как Clickhouse делает быстрее агрегации в JSON-данных
Хотя бенчмаркинговые тесты от вендоров редко бывают объективными, просматривать их довольно интересно. Недавно мне попалось сравнительное тестирование эффективности хранения и производительности операций с JSON-документами в разных базах данных: ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL. Хотя первичная модель хранения данных в этих базах отличается, все они поддерживают работу с JSON-документами. В документо-ориентированных MongoDB и Elasticsearch это основной формат хранения данных, а в реляционной PostgreSQL и колоночных ClickHouse с DuckDB – один из возможных типов данных.
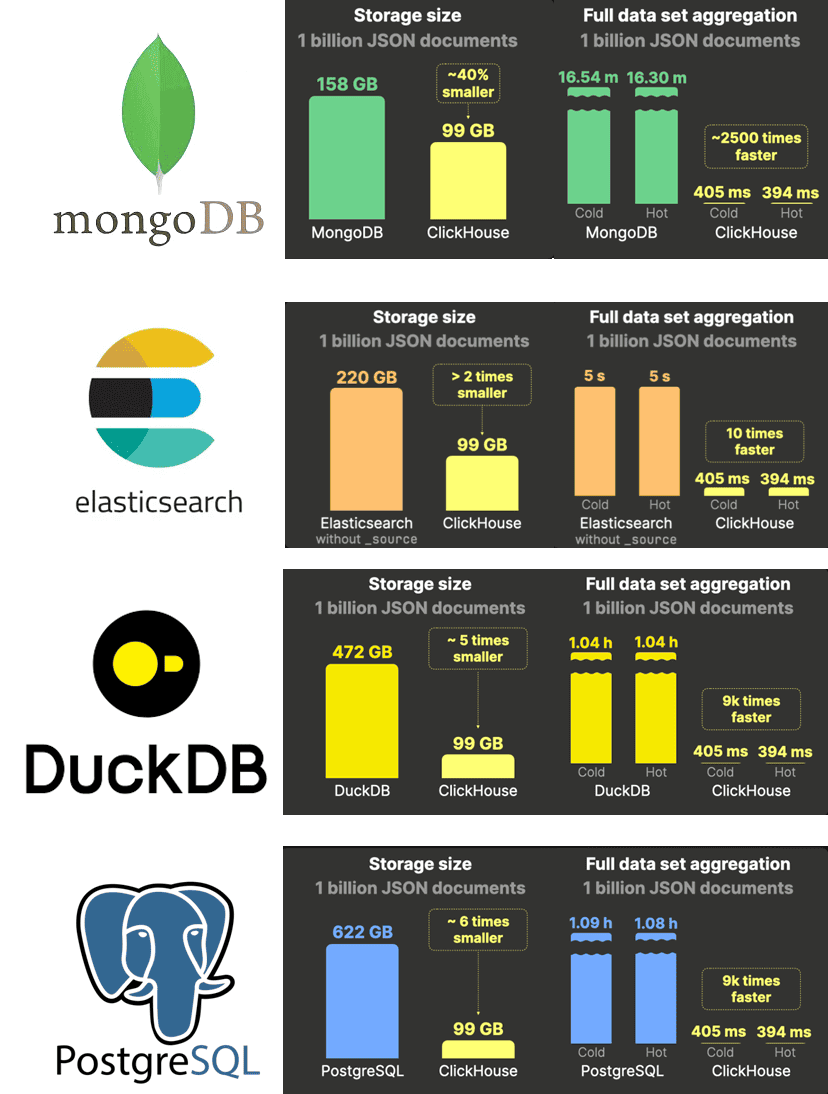
Поскольку тест проводился разработчиками ClickHouse, неудивительно, что именно эта СУБД показала наилучшую производительность. В качестве тестового набора данных использовался 1 миллиард JSON-документов. При этом ClickHouse
- оказался на 40% эффективнее в плане хранения и в 2500 раз быстрее в агрегации, чем MongoDB;
- требует в 2 раза меньше места для хранения и выполняет агрегации в 10 раз быстрее, чем Elasticsearch;
- потребляет в 5 раз меньше места на диске и выполняет аналитические запросы в 9000 раз быстрее, чем DuckDB;
- использует в 6 раз меньше места на диске и выполняет аналитические запросы в 9000 раз быстрее, чем PostgreSQL;
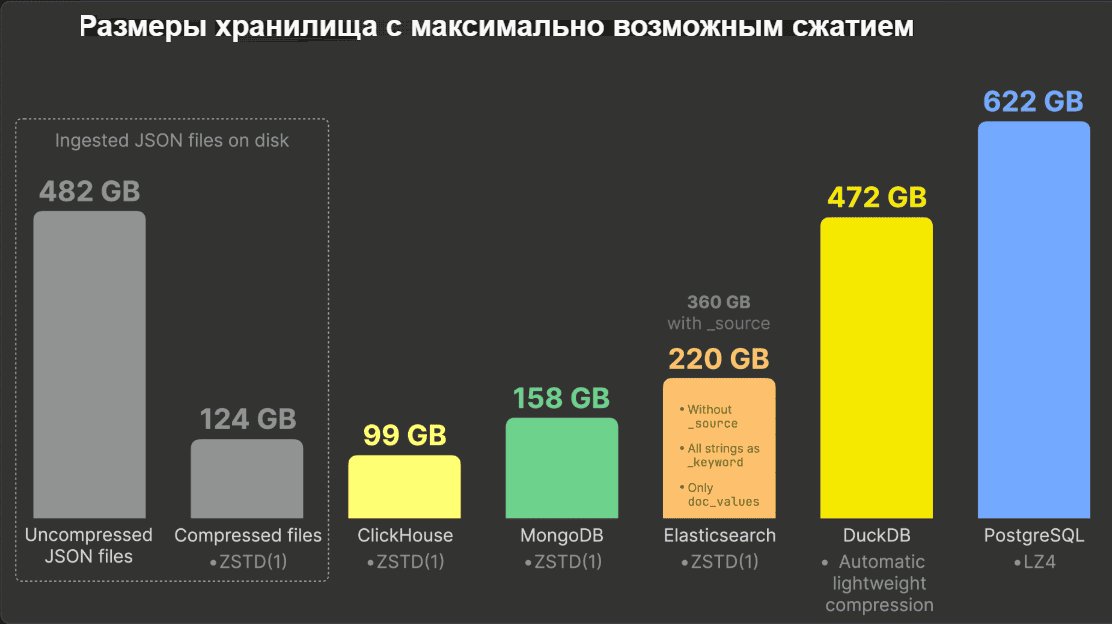
- хранит JSON-документы на 20% компактнее, сохраняя их в формате compressed files on disk, даже при использовании того же алгоритма сжатия.
Такие впечатляющие результаты объясняются внедрением в релизе 24.8 нового типа данных JSON в ClickHouse с поддержкой динамически изменяющихся структур данных без унификации типов и возможностью очень быстрого запроса отдельных путей. ClickHouse хранит значения каждого уникального пути JSON как собственные столбцы, обеспечивая высокую степень сжатия данных и сохраняя высокую производительность запросов. Значения из каждого уникального пути JSON хранятся на диске в отдельных сильно сжатых файлах столбцов внутри части данных. К этим столбцам можно обращаться независимо, сокращая операции ввода-вывода для запросов, ссылающихся только на несколько путей JSON.
ClickHouse хранит значения каждого уникального пути JSON аналогично традиционным типам данных (integer, string и пр.), обеспечивая высокопроизводительную агрегацию данных JSON. При этом СУБД генерирует разреженный первичный индекс для автоматического ускорения запросов, которые фильтруют по этим столбцам первичного ключа. Кроме того, ClickHouse эффективно утилизирует все доступные ресурсы, обеспечивая полную параллелизацию более 90 встроенных агрегатных функций, обрабатывая N неперекрывающихся диапазонов данных параллельно по N ядрам ЦП на одном сервере. Эти диапазоны данных не зависят от ключа группировки и динамически балансируются для оптимизации распределения рабочей нагрузки.
Если исходные JSON-данные агрегатного запроса распределены по нескольким узлам кластера в виде фрагментов таблицы, ClickHouse распараллеливает агрегатные функции по всем доступным ядрам ЦП на всех узлах. Такая параллелизация возможна благодаря использованию частичной агрегации состояний, когда вместо непосредственного вычисления окончательных агрегатов на всех данных сразу, ClickHouse использует агрегатные функции, которые возвращают промежуточные состояния. Эти состояния содержат необходимую информацию для последующего объединения. Сперва данные обрабатываются независимо на разных узлах или частях данных, и для каждой части вычисляются промежуточные состояния агрегатов. После этого выполняется финальная агрегация, когда промежуточные состояния объединяются для получения окончательных результатов. Этот этап обычно требует передачи меньшего объёма данных по сети, поскольку агрегаты уже частично вычислены. Таким образом, разделение агрегации на частичные состояния позволяет сократить общий объём данных, передаваемых между узлами и использовать параллельную обработку в кластере, снижая нагрузку на конечные узлы при вычислении финальных агрегатов.
Наконец, при выполнении запросов ClickHouse использует различные встроенные кэши, а также кэш страниц операционной системы. Это дополнительно ускоряет выполнение запросов.
Хранение JSON-документов
Как уже было отмечено, ClickHouse хранит значения каждого уникального пути JSON аналогично традиционным типам данных (integer, string и пр.), позволяя использовать их в качестве столбцов первичного ключа. Это гарантирует, что JSON-документы будут храниться на диске в каждой части таблицы, упорядоченные по значениям этих путей. Использование подстолбцов JSON в качестве столбцов первичного ключа позволяет лучше размещать схожие данные в каждом файле столбцов, повышая коэффициент сжатия, если эти столбцы расположены в порядке возрастания кардинальности. Порядок данных на диске также предотвращает ненужную операцию сортировки, когда порядок сортировки поиска запроса совпадает с физическим порядком данных. По умолчанию ClickHouse применяет lz4-сжатие и поддерживает zstd в облачной версии к каждому файлу столбца данных поблочно. Также можно определить кодеки сжатия для каждого отдельного столбца в запросе создания таблицы CREATE TABLE. ClickHouse поддерживает универсальные и специализированные кодеки шифрования, которые можно объединять в последовательность. Для типа данных JSON сейчас ClickHouse поддерживает определение кодеков для всего поля JSON. В будущем разработчики обещают указание кодеков для пути JSON.
В Elasticsearch все конечные значения пути JSON автоматически сохраняются в нескольких структурах данных для ускорения выполнения запросов. В MongoDB все документы изначально хранятся в формате BSON, оптимизированном для ее документо-ориентированной архитектуры. При этом эти документо-ориентированные БД активно используют индексы для ускорения поиска по JSON-документам, что увеличивает объем хранения. DuckDB и PostgreSQL также используют вторичные индексы для JSON-данных, потребляя ресурсы хранилища.
Наконец, ClickHouse строго типизирует данные, что позволяет более эффективно использовать пространство хранения. В отличие от MongoDB и Elasticsearch, где типы данных могут быть более гибкими и, как следствие, менее оптимизированными для сжатия.
Подробнее о том, как именно хранятся и обрабатываются JSON-данные в каждой из рассматриваемых БД, читайте в новой статье.
Научиться работать с ClickHouse вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

