 1091
1091 
Особенности хранения и аналитической обработки JSON-документов в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL: объяснение бенчмаркингового теста.
JSON в ClickHouse
Недавно мы писали про бенчмаркинговое сравнение хранения и обработки JSON-данных в ClickHouse, MongoDB, Elasticsearch, DuckDB и PostgreSQL. В этом тесте, проведенном самими разработчиками ClickHouse, эта СУБД показала максимальную эффективность, которая обоснована особенностями хранения JSON-данных. ClickHouse представляет пути ключей JSON-документов в виде отдельных подстолбцов. Это обеспечивает высокую степень сжатия данных и поддерживая производительность запросов, характерную для классических типов. JSON-данные (по частям таблицы) хранятся на диске, упорядоченные по подстолбцам JSON, которые используются в качестве столбцов первичного ключа. К этим столбцам можно обращаться независимо, что сводит к минимуму ненужный ввод-вывод для запросов, ссылающихся только на несколько путей JSON.
Кроме того, ClickHouse создает файл первичного индекса для автоматического ускорения запросов, которые фильтруют по столбцам первичного ключа. А использование подстолбцов JSON в качестве столбцов первичного ключа обеспечивает оптимальные коэффициенты сжатия для bin-файлов данных подстолбцов при условии, что столбцы первичного ключа расположены в порядке возрастания кардинальности.
Наконец, ClickHouse по максимуму использует возможности своей кластерной архитектуры с помощью распараллеливания агрегатных функций по всем доступным ядрам ЦП на всех узлах и частичной агрегации состояний. Для дополнительного ускорения при выполнении запросов ClickHouse использует встроенные кэши, а также кэш страниц операционной системы.
MongoDB
MongoDB изначально хранит все данные в виде коллекций BSON-документов (бинарный JSON). Механизм хранения MongoDB по умолчанию, WiredTiger, организует данные на диске как блоки, которые представляют страницы B-дерева. Корневые и внутренние узлы хранят ключи и ссылки на другие узлы, а конечные узлы содержат блоки данных для сохраненных BSON-документов. MongoDB позволяет пользователям создавать вторичные индексы на путях JSON для ускорения запросов, фильтрующих эти пути. Эти индексы структурированы как B-деревья, где каждая запись соответствует принятому JSON-документу и хранит значения индексированных путей JSON. Индексы загружаются в память, позволяя планировщику запросов быстро обходить дерево для поиска документов, которые загружаются с диска для обработки. Если запрос ссылается только на индексированные пути JSON, MongoDB может удовлетворить его полностью, используя индекс B-дерева в памяти, без загрузки документов с диска. WiredTiger по умолчанию использует блоковое сжатие с помощью библиотеки snappy для коллекций и префиксное сжатие для индексов B-дерева. В качестве альтернативы для коллекций можно включить zstd, чтобы достичь более высоких показателей сжатия. MongoDB поддерживает кластеризованные коллекции, которые хранят документы в порядке указанного кластеризованного индекса, помогая размещать похожие данные и улучшать сжатие. Однако, ключи кластеризованного индекса должны быть уникальными и ограничены максимальным размером 8 МБ.
MongoDB использует внутренний кэш WiredTiger и кэш страниц операционной системы, но не имеет кэша результатов запросов. Кэш WiredTiger, в котором хранятся недавно использованные данные и индексы, работает независимо от кэша страниц ОС. По умолчанию его размер составляет 50 % от доступной оперативной памяти минус 1 ГБ. Этот кэш можно очистить только через перезапуск сервера MongoDB.
В отличие от ClickHouse, который обрабатывает наносекунды, MongoDB поддерживает только точность в миллисекундах. Кроме того, в агрегационной структуре MongoDB отсутствует встроенный оператор COUNT DISTINCT для подсчёта количества уникальных значений в указанном столбце. Она игнорирует повторяющиеся записи и учитывает только уникальные значения. Это особенно полезно, когда необходимо определить, сколько различных элементов присутствует в наборе данных. В MongoDB есть менее эффективный $addToSet — оператор обновления, который добавляет указанное значение в массив только в том случае, если это значение еще не присутствует в массиве. Это полезно для предотвращения дублирования элементов.
Практическая архитектура данных
Код курса
PRAR
Ближайшая дата курса
6 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Elasticsearch
Elasticsearch — поисковая и аналитическая система, которая получает все полученные данные в исходном формате в виде JSON-документов. Полученные данные JSON в Elasticsearch индексируются и хранятся в различных структурах данных, оптимизированных для определенных шаблонов доступа. Эти структуры находятся в сегменте , основном индексирующем блоке Lucene — библиотеки Java, которая обеспечивает возможности поиска и аналитики Elasticsearch.
Сохраненные поля служат хранилищем документов для возврата исходных значений полей в ответах на запросы. По умолчанию они также хранят поле _source, которое содержит исходные принятые JSON-документы. Сохраненные поля сжимаются с использованием алгоритма, определенного настройкой index.codec: lz4 по умолчанию или zstd для более высоких коэффициентов сжатия с пониженной производительностью. Поле _source необходимо в Elasticsearch для переиндексации и обновления индекса до новой основной версии, а также полезно для запросов, возвращающих исходные документы. Отключение поля _source значительно снижает использование диска, но удаляет эти возможности. В корпоративной версии Elasticsearch функция синтетического источника _source_source позволяет выполнять реконструкцию по запросу из других структур данных Lucene.
Значения из принятых документов JSON хранятся в doc_values – колоночной структуре на диске, оптимизированной для аналитических запросов, которые агрегируют и сортируют данные. При этом doc_values не сжимаются с помощью кодеков lz4 или zstd. Вместо этого каждый столбец кодируется индивидуально с помощью специализированных кодеков на основе типа данных значений столбца, кардинальности и т. д. Для улучшения коэффициентов сжатия для хранимых полей и doc_values в Elasticsearch можно настроить сортировку данных на диске перед сжатием. Подобно ClickHouse, эта сортировка также повышает производительность запросов, позволяя выполнять их раньше.
Elasticsearch обрабатывает запросы, используя кэш страниц операционной системы, а также два кэша результатов запросов на уровне сегмента. Кроме того, Elasticsearch выполняет все запросы в JVM, обычно выделяя половину доступной физической памяти при запуске, вплоть до ограничения размера кучи в 32 ГБ. Этот предел допускает эффективные с точки зрения памяти указатели объектов. Любая оставшаяся физическая память сверх этого предела используется косвенно для кэширования загруженных на диск данных в кэше страниц операционной системы.
Рабочие нагрузки запросов, обычно присутствующие в сценариях использования крупномасштабной аналитики данных и наблюдения, почти всегда используют count(*) и count_distinct(…), агрегируя более миллиардов строк таблиц. В отличие от ClickHouse, который вычисляет полностью точные результаты для count(*) и count_distinct(…), в Elasticsearch агрегации всегда являются приблизительными, если данные охватывают несколько сегментов. Аналогично работает агрегатная функция COUNT_DISTINCT, использующая алгоритм HyperLogLog++ .
Подобно MongoDB, в Elasticsearch функции даты и времени имеют точность до миллисекунды, хотя поддерживает временные метки хранятся в типе date_nanos. Функции ClickHouse для работы с датами и временем могут обрабатывать даты с точностью до наносекунд.
DuckDB
DuckDB — это колоночная аналитическая база данных для сред с одним узлом. Она поддерживает постоянное хранилище и хранит базу данных как один файл, включающий все таблицы, представления, индексы, макросы и пр., присутствующие в базе данных. Формат хранения DuckDB использует сжатое столбчатое представление, которое компактно, но позволяет эффективно выполнять массовые обновления. DuckDB также может работать в режиме in-memory, когда никакие данные не сохраняются на диске.
DuckDB может использоваться для интерактивного анализа данных и в качестве компонента конвейера для их автоматизированной обработки. Эта БД может быть развернута в браузерах с использованием клиента WebAssembly и на смартфонах. Расширения DuckDB поддерживают геопространственный анализ и интеграцию с другими хранилищами данных.
DuckDB поддерживает тип данных JSON с 2022 года. Однако, в отличие от ClickHouse, DuckDB хранит JSON-данные как простые строки, без оптимизации для колоночного хранения. Поэтому хранение JSON-документов и агрегации по ним менее эффективны, чем в колоночной MPP-СУБД.
Чтобы ускорить запросы фильтрации и агрегации, DuckDB автоматически создает индексы min-max для столбцов данных общего назначения, сохраняя минимальные и максимальные значения для каждой группы строк. Он также генерирует ART-индексы (Adaptive Radix Tree) для столбцов с ограничениями первичного и внешних ключей, а также уникальных значений. ART-индексы можно явно добавлять в другие столбцы, которые хранят вторичную копию данных и их эффективность ограничена точечными запросами или высокоселективными фильтрами, которые охватывают примерно 0,1% или менее строк.
DuckDB автоматически применяет легкие алгоритмы сжатия к данным столбцов на основе типов, мощности и других факторов. DuckDB рекомендует предварительно упорядочивать данные во время вставки для группировки схожих значений, улучшения коэффициентов сжатия и повышения эффективности min-max индексов. DuckDB не обеспечивает автоматического упорядочивания данных. DuckDB использует кэш страниц операционной системы и ее менеджер буферов для кэширования страниц из своего постоянного хранилища.
PostgreSQL
PostgreSQL изначально поддерживает JSON-данные в типах JSON и JSONB. Представленный в PostgreSQL 9.2 с 2012 года, тип JSON хранит JSON-документы в виде текста, требуя функций обработки для повторного анализа документа при каждом выполнении. В 2014 году PostgreSQL 9.4 представил тип JSONB, который использует декомпозированный двоичный формат, аналогичный BSON как в MongoDB. Именно JSONB рекомендуется для работы с JSON-данными в PostgreSQL.
PostgreSQL хранит данные в строковом виде, поэтому JSON-документы хранятся в виде кортежей JSONB последовательно на диске. Чтобы ускорить поиск, пользователи могут создавать вторичные индексы на определенных путях JSON для ускорения фильтрации запросов по ним. По умолчанию PostgreSQL создает структуры данных индекса B-Tree, содержащие одну запись для каждого JSON-документа, где каждая запись B-Tree хранит значения индексированных путей JSON в документе. PostgreSQL поддерживает сканирование только индексов с индексами B-tree, аналогично MongoDB, для запросов, ссылающихся только на пути JSON, сохраненные в индексе. Однако эта оптимизация не является автоматической и зависит от стабильности данных таблицы, а также от строк, помеченных как видимые, в таблице visibility map. Это позволяет считывать данные напрямую из индекса без необходимости дополнительных проверок в основной таблице.
PostgreSQL хранит данные построчно на 8-килобайтных страницах на диске, стремясь заполнить каждую страницу кортежами. Для оптимального хранения кортежи в идеале должны быть размером менее 2 КБ. Любой кортеж размером более 2 КБ обрабатывается с помощью TOAST (The Oversized-Attribute Storage Technique), который сжимает и разбивает данные на более мелкие фрагменты. Поддерживаемые методы сжатия для TOAST-кортежей включают pglz и lz4, тогда как кортежи размером менее 2 КБ остаются несжатыми.
PostgreSQL поддерживает кластеризованные таблицы, где данные физически переупорядочиваются на основе кортежей индекса. Однако, в отличие от ClickHouse и Elasticsearch, сортировка данных в таблице не повышает коэффициент сжатия в PostgreSQL, т.к. сжатие применяется только к кортежу размером более 2 КБ, независимо от порядка данных. Кроме того, построчное хранение данных в PostgreSQL предотвращает совместное размещение схожих данных в столбцах, что могло бы улучшить сжатие за счет группировки схожих значений.
PostgreSQL использует внутренние кэши для ускорения доступа к данным, включая кэширование планов выполнения запросов и часто используемых блоков данных таблиц и индексов. Как и другие рассмотренные базы данных, она также использует кэш страниц операционной системы. Однако PostgreSQL не предоставляет выделенный кэш для результатов запросов, что снижает скорость их выполнения.
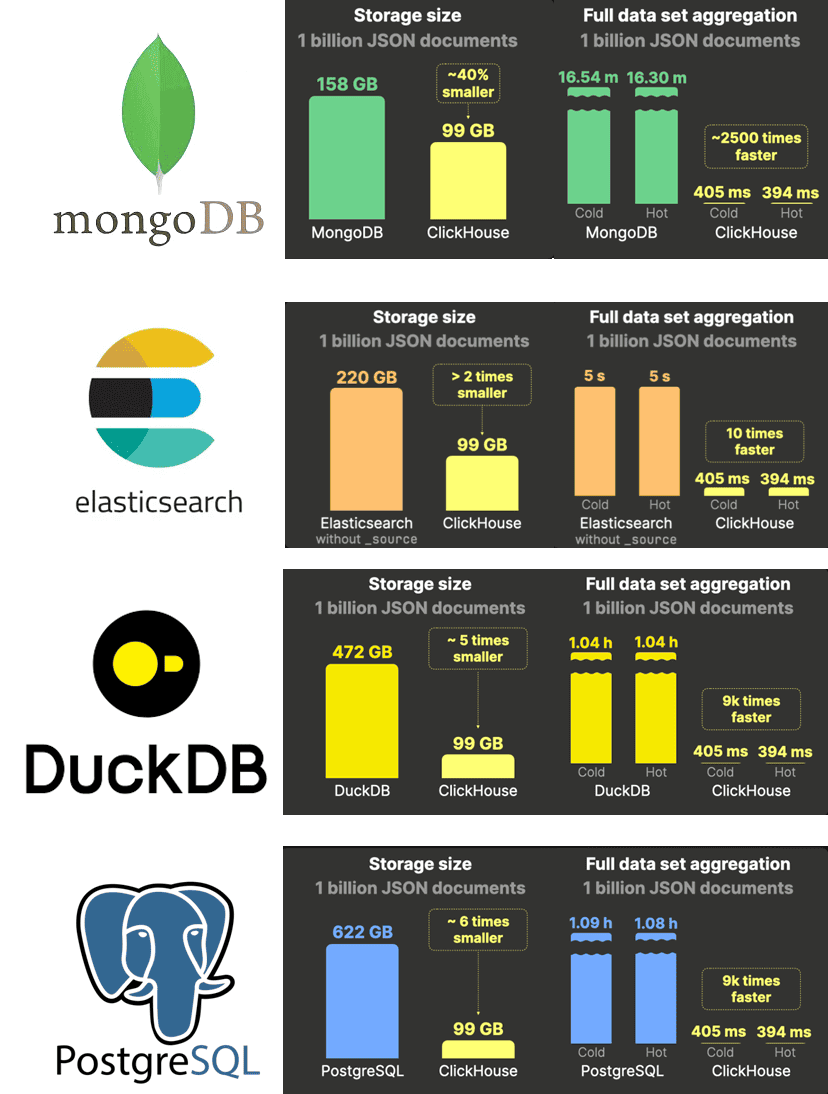
Таким образом, при большом объеме JSON-документов их хранение и аналитическая обработка более эффективна в ClickHouse благодаря оптимальному хранению сжатых данных за счет представления значений каждого уникального пути JSON как отдельного столбца и его индивидуального сжатия. А использование первичного ключа и группировки похожих данных по столбцам с их сортировкой дополнительно повышает степень сжатия, сокращая потребление дисковых ресурсов.
Научиться работать с ClickHouse вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

