Как Apache Beam распараллеливает потоковые и пакетные конвейеры обработки данных, добавляя собственные операции к пользовательским преобразованиям. Смотрим на примере простого пакетного конвейера с ограниченным параллелизмом.
Распараллеливание операций в Apache Beam
Напомним, Apache Beam представляет собой унифицированную модель определения пакетных и потоковых конвейеров параллельной обработки данных, которую можно запустить в любой среде исполнения: Flink, Spark, AirFlow и пр., используя соответствующий движок (Runner). Конвейер в Beam – это последовательность шагов извлечения, преобразования или выгрузки данных во внешний источник. Чтобы ускорить выполнение этих операций, необходимо понимать, как именно движок выполняет модель конвейера, определенную в Beam.
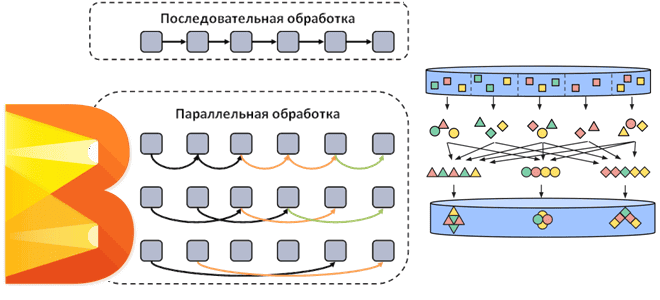
Будучи изначально спроектированным для параллельной обработки информации, Apache Beam реализует подход embarrassingly parallel. Этот термин из параллельных вычислений означает, что очень простое разделение задачи на независимые подзадачи, выполняемые параллельно без необходимости взаимодействия между ними. В Apache Beam этот подход позволяет эффективно масштабировать обработку данных, поскольку каждую подзадачу можно выполнять независимо на разных узлах кластера.
Однако, такая параллельная обработка элементов затрудняет некоторые последовательные действия, например, упорядочивание элементов в PCollection – основной абстракции Beam, с которой выполняются операции обработки данных. PCollection в Apache Beam – это неупорядоченная коллекция элементов, потенциально распределенный однородный набор или поток элементов одного типа данных, который создан для конкретного объекта конвейера Pipeline и принадлежит ему. Несколько конвейеров не могут совместно использовать PCollection. Конвейеры Beam обрабатывают PCollection, а исполнитель отвечает за хранение этих элементов. PCollection обычно содержит слишком много данных, чтобы поместиться в памяти на одной машине. Хотя на практике небольшой образец данных или промежуточный результат может поместиться в памяти на одном узле, вычислительные шаблоны и преобразования Beam ориентированы на ситуации, когда требуются распределенные параллельные вычисления данных. Поэтому элементы PCollection обрабатываются не по отдельности, а равномерно и параллельно.
У каждой PCollection есть кодер, представляющий собой спецификацию двоичного формата элементов. В Beam конвейер пользователя может быть написан на языке, отличном от языка исполнителя. Часто используются методы сериализации, специфичные для языка, но есть несколько общих форматов ключей, например, пары ключ-значение и временные метки, которые исполнитель может понимать. Впрочем, исполнитель не выполняет десериализацию пользовательских данных. Модель Beam работает в основном с закодированными данными, просто байтами.
Хотя все элементы PCollection должны быть одного типа, для распределенной обработки Beam должен иметь возможность кодировать каждый отдельный элемент как строку байтов, чтобы передавать распределенным рабочим процессам. SDK Beam включают механизмы кодирования часто используемых типов данных, а также поддерживают пользовательские сериализации по мере необходимости. Обычно тип элемента PCollection имеет интроспектируемую структуру со схемой данных, например, JSON, protobuf, AVRO и записи базы данных.
Будучи неизменяемой коллекцией данных, PCollection не позволяет добавлять, удалять или изменять его элементы после создания. Преобразования Beam могут обрабатывать каждый элемент и генерировать новые данные конвейера как новый PCollection, не изменяя исходную коллекцию. Чтобы избежать ненужного копирования элементов, содержимое PCollection неизменяемо логически, а не физически. Изменения входных элементов могут быть видны другим UDF-функциям, т.е. DoFn, выполняемым в том же пакете, что потенциально опасно.
Как уже было отмечено, PCollection не поддерживает случайный доступ к отдельным элементам, хотя преобразования Beam рассматривает каждый элемент индивидуально. Кроме того, параллельная обработка всех элементов делает невозможным пакетирование любых операций, таких как запись элементов в приемник или создание контрольной точки во время обработки. Вместо того, чтобы обрабатывать все элементы одновременно, элементы в PCollection обрабатываются в пакетах. Разделение PCollection на пакеты делается исполнителем произвольно с учетом компромисса между сохранением результатов после каждого элемента и необходимостью повтора всех операций в случае сбоя. Например, потоковый исполнитель обычно обрабатывает и фиксирует небольшие пакеты, а пакетный работает с более крупными.
Разделение и распараллеливание обработки элементов в конвейере Beam зависит от реализации источника данных и межэтапного параллелизма ключей. Конвейеры Beam считывают данные из источника, который реализует разделяемую UDF-функцию (Splittable DoFn). При выполнении операций на основе ключей в Beam, например, GroupByKey, Combine, Reshuffle.perKey и stateful-функции DoFn, исполнители Beam выполняют перемешивание – сериализацию и передачу данных по сети, чтобы обрабатывать элементы данных одного и того же ключа вместе. Способы перемешивания данных могут отличаться для пакетного и потокового режимов выполнения.
Shuffle-операции всегда являются наиболее затратными в любом конвейере обработки данных из-за накладных расходов на сериализацию и сетевую передачу. Движок исполнения передает данные по сети между преобразованиями конвейера в следующих ситуациях:
- маршрутизация элементов к рабочему процессу для выполнения агрегации, что может включать сериализацию элементов и группировку или сортировку их по ключу;
- перераспределение элементов между рабочими узлами для настройки параллелизма, включая сериализацию элементов их сетевую передачу;
- использование элементов в побочном входе в ParDo – преобразовании для параллельной обработки как в MapReduce, что требует сериализации элементов и их трансляции всем рабочим процессам;
- передача элементов между преобразованиями, которые выполняются на одном и том же рабочем объекте, чтобы вместо сериализации элементов хранить их в памяти и считывать оттуда, избегая операций ввода-вывода.
Сериализация и сохранение элементов обычно выполняются при реализации stateful-функций DoFn и при фиксации результатов обработки в качестве контрольной точки.
Вспомнив теоретические основы обработки данных в конвейерах Apache Beam, далее рассмотрим практический пример, запустив модель в Google Colab.
Пример выполнения конвейера
Последовательные преобразования могут быть зависимо параллельными, если исполнитель выбирает выполнение потребляющего преобразования на выходных элементах производящего преобразования без изменения объединения. Это позволяет исполнителю избегать перераспределения элементов между исполнителями, сокращая накладные расходы на сетевую передачу данных. Однако, максимальный параллелизм теперь зависит от максимального параллелизма первого из зависимо параллельных шагов.
Рассмотрим пример зависимо-параллельных последовательных преобразований в Apache Beam, где исполнитель может выполнять потребляющие преобразования без перераспределения данных между исполнителями. Сперва установим библиотеки и импортируем модули:
#установка библиотек !pip install apache-beam[interactive] !pip install graphviz #импорт модулей import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions from google.colab import files
Рассмотрим набор последовательных ParDo-преобразований, которые могут выполняться последовательно на одних и тех же исполнителях без необходимости перераспределения данных, так как структура данных не меняется существенно между шагами. Максимальный параллелизм, ограниченный первым преобразованием ExtractWords, означает, что количество одновременно выполняемых задач определяется способностью этого преобразования обрабатывать данные параллельно:
class ExtractWords(beam.DoFn):
def process(self, element):
return element.split()
class ToUpperCase(beam.DoFn):
def process(self, word):
yield word.upper()
if __name__ == "__main__":
# Опции пайплайна для использования RenderRunner и указания файла вывода
options = PipelineOptions([
'--runner=apache_beam.runners.render.RenderRunner',
'--render_output=pipline_1.png'
])
with beam.Pipeline(options=options) as pipeline:
(
pipeline
| 'Читаем строки' >> beam.Create([
'Привет, как дела?',
'Примеры преобразований Apache Beam'
])
| 'Извлекаем слова' >> beam.ParDo(ExtractWords())
| 'Переводим в верхний регистр' >> beam.ParDo(ToUpperCase())
| 'Выводим преобразованные слова на печать' >> beam.Map(print)
)
Запустив эту ячейку, получим PNG-файл, визуализирующий шаги выполнения конвейера в виде графа.
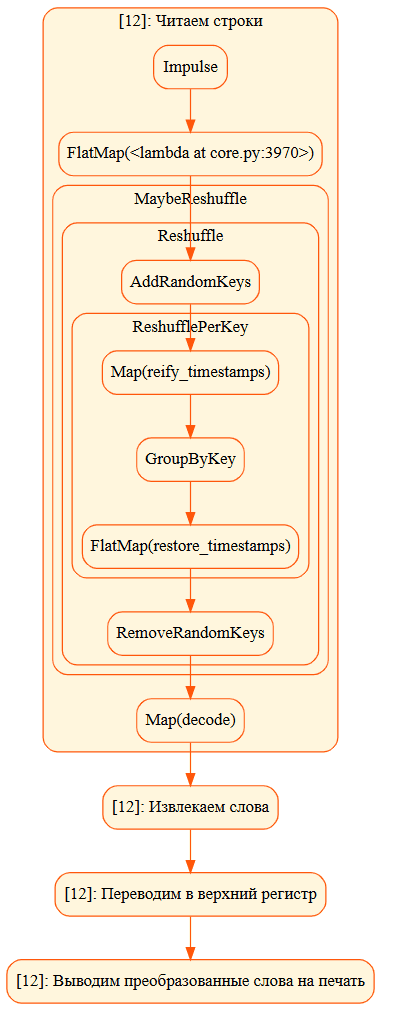
Визуализация конвейера отображает не только те этапы, которые явно указаны в коде, но и внутренние операции, которые выполняет сам Beam для обработки данных:
- Impulse – начальная точка конвейера, которая генерирует начальные элементы, что соответствует первому шагу чтения строк, где создается начальный набор строк с помощью beam.Create. Это внутренний источник данных Apache Beam, начинающий конвейер. Он генерирует начальные (импульсные) данные для дальнейшей обработки и запускает поток обработки данных, действуя как точка входа в конвейер.
- FlatMap(<lambda at core.py:3970>) – функция ExtractWords, используемая для разбиения строк на слова, преобразуется в операцию FlatMap внутри Beam, поскольку ParDo часто реализуется как FlatMap для обработки и преобразования элементов потока.
- вершины MaybeReshuffle, Reshuffle, ReshufflePerKey связаны с оптимизацией распределения данных по рабочим узлам для обеспечения параллельной обработки и балансировки нагрузки. Beam вводит их автоматически в процессе выполнения конвейера для повышения эффективности. MaybeReshuffle – это условная операция перестановки данных, если это необходимо с учетом текущего состояния данных или оптимизаций, чтобы улучшить производительность и уменьшить задержки. Reshuffle – это полная перестановка данных, обеспечивающая перераспределение элементов между различными исполнителями или узлами. Необходимо для операций, требующих рандомизации или перераспределения данных, чтобы обеспечить масштабируемость и параллельную обработку. ReshufflePerKey – это специализированная перестановка данных по ключам для операций, требующих перераспределения записей с одинаковыми ключами на один и тот же рабочий узел. Это обеспечивает, что все записи с одинаковыми ключами обрабатываются одним исполнителем, что необходимо для операций агрегации или объединения.
- GroupByKey – хотя в исходном конвейере явно нет группировки по ключам, некоторые операции, такие как ParDo, могут автоматически требовать группировки данных для правильного распределения и обработки, что приводит к появлению такой вершины графа. GroupByKey группирует элементы данных по ключам, что может соответствовать этапу извлечения или преобразования данных, где требуется агрегация или объединение элементов. Эта функция объединяет все элементы с одинаковыми ключами, позволяя выполнять агрегации, такие как подсчет количества, суммирование и пр.
- вершины Map(reify_timestamps), FlatMap(restore_timestamps) – операции связаны с обработкой временных меток элементов данных, что нужно для точного управления временем обработки и временными окнами для потоковой обработки в Beam. Map(reify_timestamps) – этап, на котором временные метки данных преобразуются или закрепляются (reify), что может быть необходимо для корректной обработки временных окон или событий. FlatMap(restore_timestamps) восстанавливает временные метки после определенных преобразований, возвращая их к исходному состоянию для дальнейшей обработки или агрегирования. Этот шаг необходим, если временные метки были изменены или сохранены в промежуточных шагах.
- RemoveRandomKeys, AddRandomKeys – шаги для управления уникальностью ключей или для оптимизации распределения данных по ключам. AddRandomKeys добавляет случайные ключи к каждой записи данных для распределения данных по разным узлам в кластере, обеспечивая балансировку нагрузки при параллельной обработке. RemoveRandomKeys удаляет ранее добавленные случайные ключи из данных. Этот шаг восстанавливает исходные данные к их первоначальному состоянию после распределения.
- Map(decode) – этап декодирования данных, который преобразует сырые байты или строки в более структурированный формат для последующей обработки.
Таким образом, эти шаги в визуализации отражают не только пользовательские преобразования, явно заданные в коде, но и внутренние операции Apache Beam для оптимизации и управления потоком данных, которые пытаются обеспечить высокую производительность и масштабируемость конвейера.
Узнайте больше про Apache Beam на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

