 1622
1622 
Чем хороша Python-библиотека FastStream и как ее использовать для потоковой публикации данных в Apache Kafka: практический пример асинхронной отправки JSON-сообщений.
О библиотеке FastStream
Для Python-разработчиков есть довольно много библиотек, позволяющих взаимодействовать с Apache Kafka: kafka-python, confluent-kafka, Quix Streams и другие клиенты. О сравнении kafka-python и confluent-kafka я писала здесь, а о Quix Streams – здесь. Сегодня хочу рассказать о FastStream — еще одной интересной библиотеке для создания потоковых конвейеров на Python. Этот простой, но очень мощный фреймворк облегчает разработку продюсеров и потребителей, предоставляя унифицированный API для работы с несколькими брокерами сообщений: Kafka, RabbitMQ, NATS и Redis. Взаимодействие с Apache Kafka реализуется на основе библиотек AIOKafka и Confluent. Однако, в отличие от AIOKafka и Confluent, в FastStream основным объектом, вокруг которого строится потоковый конвейер, является брокер.
Брокеры FastStream предоставляют удобные декораторы функций: @broker.subscriber(…) и @broker.publisher(…), которые автоматизируют следующие функции при разработке кода:
- публикация и потребление сообщений в очереди событий;
- кодирование и декодирование сообщений в формате JSON;
- генерация документации AsyncAPI, о чем я подробно рассказываю в новой статье.
Эти декораторы брокеров упрощают определение логики обработки для продюсеров и потребителей, позволяя сосредоточиться на основной бизнес-логике потокового приложения. Также FastStream использует Pydantic трансформации входных данных в формате JSON в объекты Python, что упрощает работу со структурированными данными, позволяя сериализовать входные сообщения, просто используя аннотации типов.
FastStream позволяет обрабатывать большие объемы данных с минимальными задержками, а также поддерживает многопоточность и параллельную обработку данных, что значительно ускоряет выполнение задач на многоядерных системах. Кроме того, фреймворк можно можно использовать как часть библиотеки FastAPI для быстрого создания веб-приложений в стиле REST. Для этого нужно всего лишь импортировать необходимый StreamRouter и объявить обработчик сообщений с теми же параметрами и декораторами: @router.subscriber(…) и @router.publisher(…). Об этом я расскажу в другой раз, а пока рассмотрим пример публикации данных в топик Kafka с помощью FastStream.
Пример публикации данных в Kafka
Как обычно, в качестве примера возьму публикацию клиентских обращений в топик InputsTopic: заявки на покупку продуктов в интернет-магазине от физических или юридических лиц или вопросы покупателей. Топик InputsTopic разделен на 3 раздела, маршрутизация сообщений по которым зависит от типа обращения:
- корпоративные заявки от юрлиц публикуются в раздел 0;
- заявки от частных лиц публикуются в раздел 1;
- все вопросы публикуются в раздел 2.
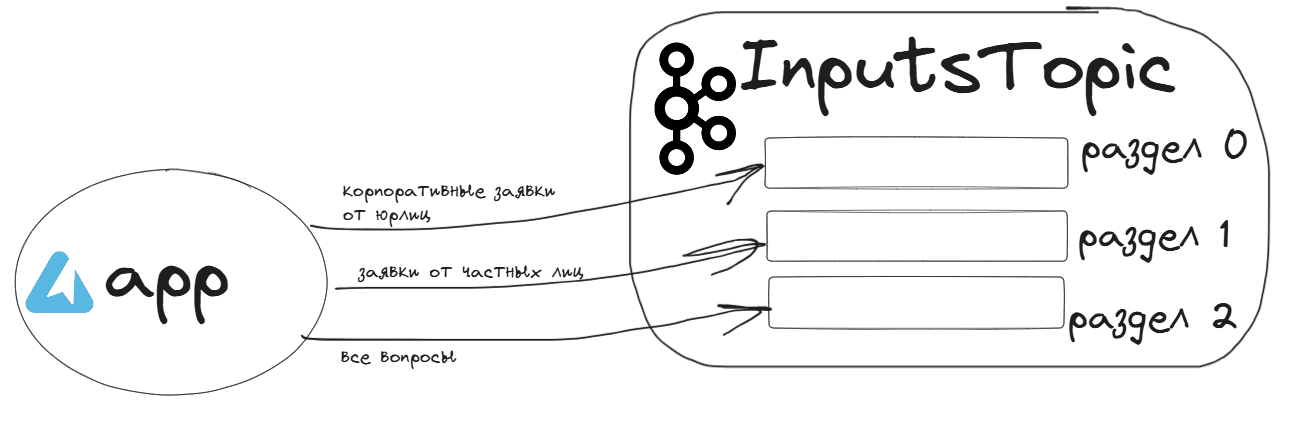
Данные обращений в формате JSON имеют похожий, но немного отличающийся набор полей.

Чтобы вы могли легко повторить это упражнение, буду писать и запускать Python-код в интерактивной среде Google Colab. Сперва установим нужные пакеты и импортируем модули:
!pip install faststream[kafka] !pip install faker !pip install nest_asyncio #импорт модулей import json import random import time import asyncio import nest_asyncio import logging import ssl from datetime import datetime from time import sleep from faststream import FastStream, Logger from faststream.kafka import KafkaBroker from pydantic import BaseModel, Field, PositiveInt, NonNegativeFloat from google.colab import userdata from typing import List from faststream.security import BaseSecurity, SASLScram256 from dataclasses import dataclass, asdict # Импорт модуля faker from faker import Faker from faker.providers.address.ru_RU import Provider # Настройка логирования logging.basicConfig(level=logging.INFO)
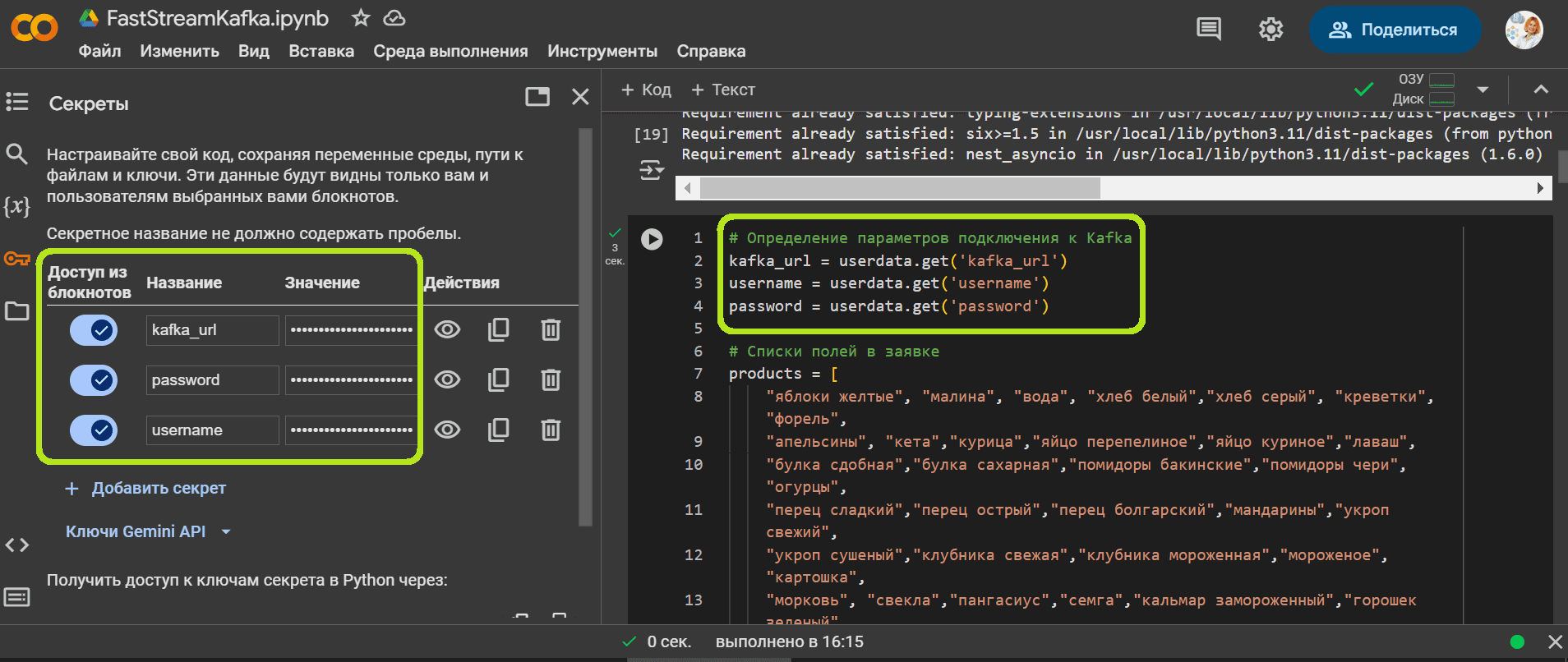
Затем зададим списки значений и определим параметры подключения к Kafka.
# Определение параметров подключения к Kafka
kafka_url = userdata.get('kafka_url')
username = userdata.get('username')
password = userdata.get('password')
# Списки полей в заявке
products = [
"яблоки желтые", "малина", "вода", "хлеб белый","хлеб серый", "креветки", "форель",
"апельсины", "кета","курица","яйцо перепелиное","яйцо куриное","лаваш",
"булка сдобная","булка сахарная","помидоры бакинские","помидоры чери","огурцы",
"перец сладкий","перец острый","перец болгарский","мандарины","укроп свежий",
"укроп сушеный","клубника свежая","клубника мороженная","мороженое","картошка",
"морковь", "свекла","пангасиус","семга","кальмар замороженный","горошек зеленый",
"смородина черная","смородина красная","соль поваренная пищевая йодированная",
"чай черный байховый","чай зеленый","чай красный","кофе","кофе с молоком","какао",
"молоко","кефир","сыр с плесенью","сыр плавленый","сыр твердый","сыр мягкий",
"яблоки красные","яблоки зеленые","яблоки сушеные","икра красная", "икра черная",
"икра заморская баклажанная","масло сливочное","масло оливковое","масло подсолнечное",
"масло кокосовое","орех грецкий","орех бразильский", "лист лавровый","куркума",
"кукуруза","печенье сладкое","пряники сдобные","тесто слоеное","варенц",
"ряженка","снежок","шоколад молочный"
]
questions = ["оплата", "доставка", "скидки", "сервис", "персонал"]
# Сопоставление темы с приоритетом
priority_map = {
"оплата": 1,
"доставка": 2,
"скидки": 3,
"сервис": 4,
"персонал": 5
}
#Параметры подключения к Kafka
class SecurityConfig:
def __init__(self, sasl_mechanism, security_protocol, sasl_plain_username, sasl_plain_password, use_ssl):
self.sasl_mechanism = sasl_mechanism
self.security_protocol = security_protocol
self.sasl_plain_username = sasl_plain_username
self.sasl_plain_password = sasl_plain_password
self.use_ssl = use_ssl
ssl_context = ssl.create_default_context()
security = SASLScram256(
ssl_context=ssl_context,
username=username,
password=password,
)
#Определение топика Kafka
topic = "InputsTopic"
# Конструктор KafkaBroker с объектом безопасности
broker = KafkaBroker([kafka_url], security=security)
В этот раз параметры для подключения к Kafka (URL-адрес bootstrap-сервера, логин и пароль) я сохранила в хранилище секретов Google Colab, получая в коде значения этих ключей.
Далее напишем код асинхронной публикации сообщений в Kafka, используя API FastStream на основе AIOKafka – python-клиента, который базируется на библиотеке kafka-python. Но, в отличие от kafka-python, AIOKafka работает асинхронно благодаря использованию asyncio, что позволяет выполнять операции без блокировки основного потока. Это особенно полезно для приложений, требующих высокой производительности и параллельности. AIOKafka предоставляет асинхронные интерфейсы для продюсеров и потребителей, что требует использования синтаксиса async/await.
Для типизации публикуемых данных будем использовать классы, чтобы избежать дублирования кода и поддерживать единообразие между различными типами клиентских обращений.
# Определение классов
# Базовый класс для запросов
@dataclass
class RequestData:
moment: str
name: str
subject: str
content: str
# Класс для корпоративных запросов
@dataclass
class CorporateRequest(RequestData):
inn: str
# Класс для частных запросов
@dataclass
class PrivateRequest(RequestData):
phone_number: str
age: int
# Класс для заявок с темой "question"
@dataclass
class QuestionRequest(RequestData):
priority: int
# Инициализация FastStream приложения
app = FastStream(broker)
# Создание продюсера для топика InputsTopic
publisher = broker.publisher(topic)
# Инициализация Faker
fake = Faker("ru_RU")
def generate_fake_data() -> RequestData:
now = datetime.now()
moment = now.strftime("%m/%d/%Y %H:%M:%S")
corp = random.choice([1, 0])
if corp == 1:
name = fake.company()
else:
name = fake.name()
subject = random.choice(["app", "question"])
if subject == "question":
theme = random.choice(questions)
content = f"Здравствуйте, у меня вопрос про {theme}"
part = 2 # все вопросы в раздел 2
else:
theme = "app"
content = f"{random.choice(products)} {random.randint(0, 100)}"
if corp == 1:
part = 0 # корпоративные заявки в раздел 0
else:
part = 1 # частные заявки в раздел 1
if theme == "app":
if corp == 1:
inn = fake.businesses_inn()
request = CorporateRequest(
moment=moment,
name=name,
subject=subject,
content=content,
inn=inn
)
else:
phone_number = fake.phone_number()
age = random.randint(18, 100)
request = PrivateRequest(
moment=moment,
name=name,
subject=subject,
content=content,
phone_number=phone_number,
age=age
)
else:
# Вычисление приоритета
priority = priority_map.get(theme, 0) # 0 - значение по умолчанию, если тема не найдена
# Преобразуем в QuestionRequest, используя ранее определённые переменные
request = QuestionRequest(
moment=moment,
name=name,
subject=subject,
content=content,
priority=priority
)
return request, part
# Публикация данных в Kafka
async def publish_data():
while True:
try:
request, part = generate_fake_data()
msg = json.dumps(asdict(request), ensure_ascii=False)
await publisher.publish(msg, partition = part) # Используем publisher для публикации
print(f"В раздел {part} опубликовано {msg}")
except Exception as e:
logging.error(f"Ошибка при публикации данных: {e}")
await asyncio.sleep(2) # Задержка перед следующим сообщением (5 секунд)
async def main():
try:
# Устанавливаем соединение с брокером
await broker.connect()
print("Соединение с Kafka установлено.")
# Запускаем процесс публикации данных
await publish_data()
except Exception as e:
logging.error(f"Ошибка при подключении или публикации: {e}")
if __name__ == "__main__":
import nest_asyncio
nest_asyncio.apply()
try:
asyncio.run(main())
except RuntimeError as e:
if "asyncio.run() cannot be called from a running event loop" in str(e):
loop = asyncio.get_event_loop()
loop.create_task(main())
else:
raise
В этом коде асинхронная функция publish_data() постоянно в бесконечном цикле каждые 2 секунды генерирует фейковые данные и вычисляет номер раздела топика Kafka, преобразует сообщение в JSON-строку, выводит информацию о публикации данных и, при возникновении ошибки логирует её.
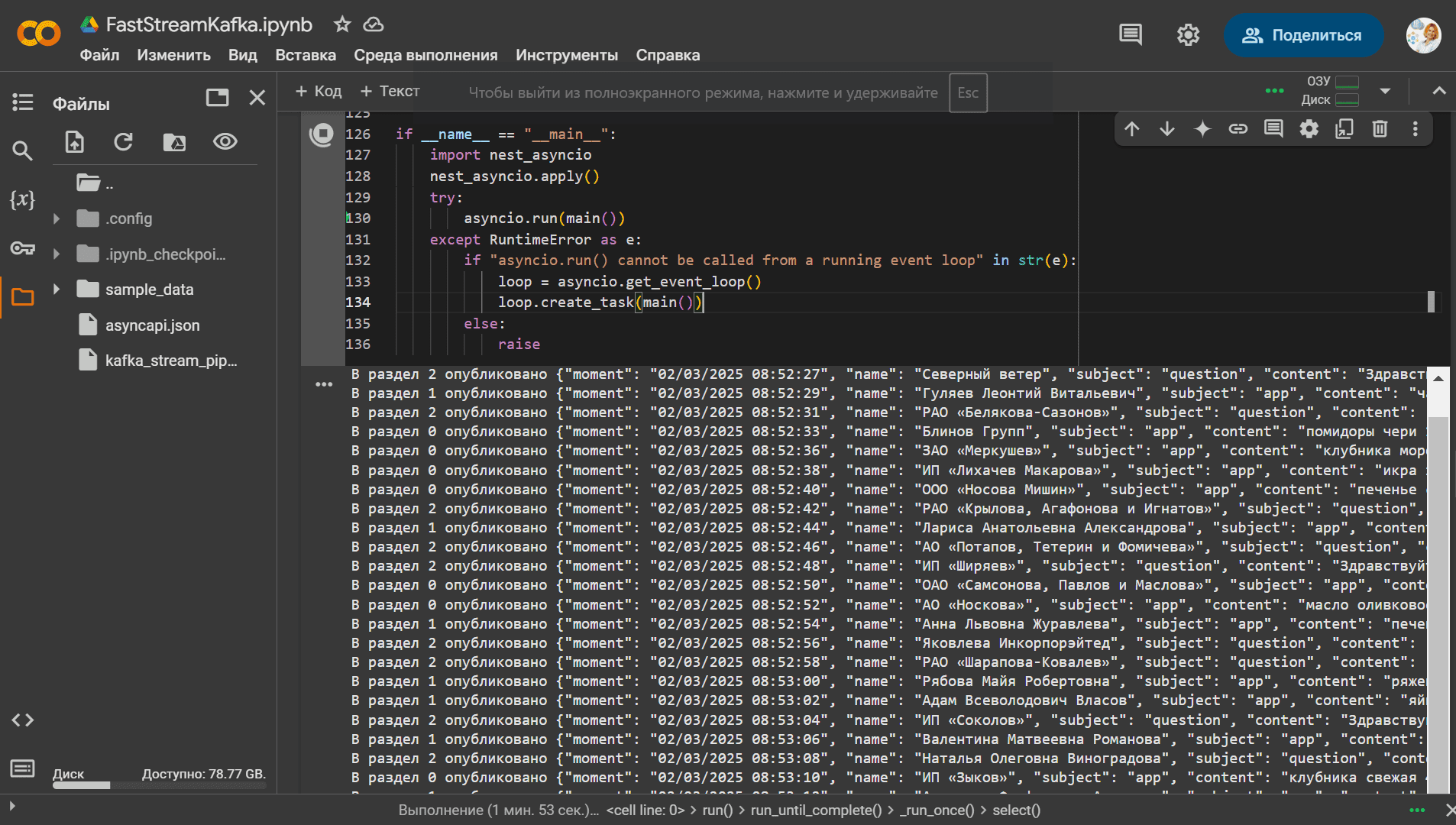
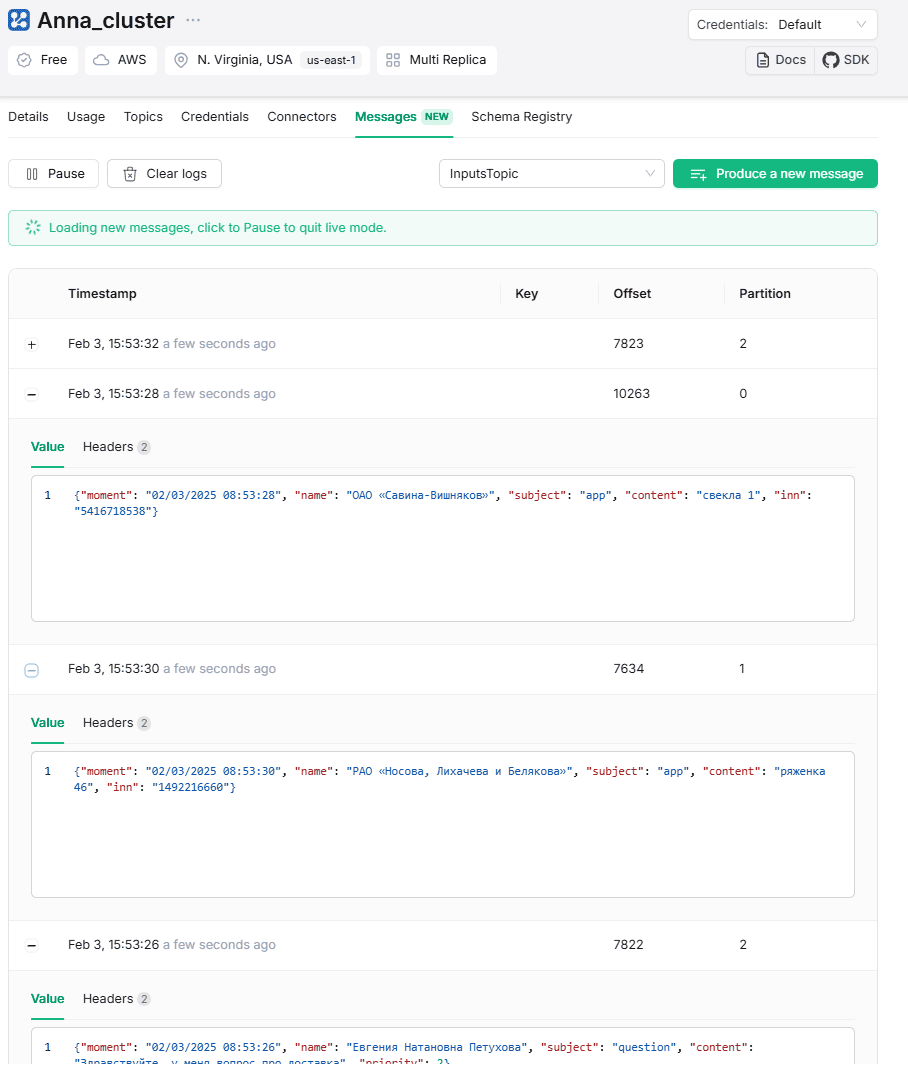
Благодаря методу asdict из модуля dataclasses, объекты классов легко преобразуются в словари, что упрощает их сериализацию в формат JSON для отправки в брокер. Аннотации типов в @dataclass также используются для автоматической генерации спецификации AsyncApi, что я показываю здесь. А в заключение отмечу, что сообщения успешно опубликованы в Kafka.
Научитесь администрированию и эксплуатации Apache Kafka на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- Apache Kafka для инженеров данных
- Администрирование кластера Kafka
- Администрирование Apache Kafka в Kubernetes
Источники

