Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем здесь потоковая обработка событий с Apache Kafka и Spark Streaming.
Проблемы микросервисной архитектуры в ML-системах на практическом примере
В настоящее время микросервисная архитектура стала стандартом де-факто, который чаще всего применяется для построения различных информационных систем, от небольших приложений до крупных Big Data Платформ. Благодаря автономности каждого микросервиса от других компонентов решения, общая скорость разработки, тестирования и развертывания продукта существенно возрастает, чего и требует основная идея Agile. Обратной стороной этого преимущества является увеличение нагрузки на архитектора при проектировании системы и разделении ее на отдельные сервисы. Кроме того, слишком частые вызовы сервиса, могут привести к перегрузке системы.
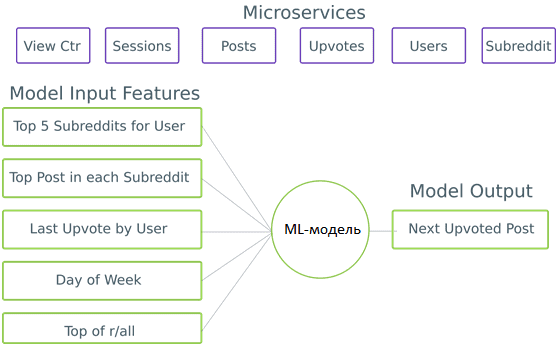
В частности, микросервисы очень сложно применять при построении моделей машинного обучения (Machine Learning, ML) на сложных источниках данных, таких как поведение пользователей. В этих случаях, чтобы сделать прогноз, нужно множество взаимозависимых микросервисов, чтобы получить всю необходимую им контекстную информацию. Например, нужно создать персонализированный канал Reddit – социальном новостном сайте, где зарегистрированные пользователи могут размещать ссылки на понравившуюся информацию. Для этого требуется знать обо всех сообществах, в которых участвует пользователь, о самых популярных сообщениях в этих группах, о любых сообщениях, которые он прочитал, и они ему понравились, а также прочая подробная информация. Добавление дополнительных входов даст больше данных для обучения ML-модели, позволяя ей уловить важные тенденции и сделать прогноз точнее.
Каждый логический вход в ML-модель называется признаком/предиктором или фичей (от англ. feature). Feature-engineering считается одной из самых трудоемких задач Machine Learning: много времени уходит на поиск нужных данных, изучение их особенностей и крайних случаев. Также сюда входит построение конвейеров данных (data pipeline) для их очистки и преобразования в пригодную для использования форму.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
21 апреля, 2025
Продолжительность
24 ак.часов
Стоимость обучения
54 000 руб.
В микросервисной архитектуре сбор данных выполняется через API. Одна ML-модель может иметь много разных фичей, требующих соответствующих вызовов API. Например, модели нужно запросить пользовательский сервис для сообществ, в которые входит пользователь, затем получить самые популярные сообщения в каждом из них, а после определить его отношение к этим записям через отметки «нравится» (лайк от англ. like). Такая сложная последовательность действий приведет к эффекту домино сетевых вызовов. В отличие от веб-интерфейса, ML-модель не обладает гибкостью в отношении недостающих фичей: ей придется дождаться завершения всех запросов или использовать некорректные входные данные [1]. Последнее может привести к некачественным результатам, т.к. один из принципов Data Science вообще и Machine Learning в частности гласит: «мусор на входе дает мусор на выходе» (garbage in – garbage out).
3 альтернативы микросервисной архитектуре
Для обучения ML-модели нужен набор данных наблюдаемых результатов и входные данные в момент времени наблюдения. Создание датасета в микросервисной архитектуре не просто. В рассматриваемом примере с Reddit требуется набор пользовательских оценок вместе с набором фичей на этот момент. Технически можно получать оценки пользователей и все данные о публикациях с помощью микросервисов. Однако в этом случае теряется точность на определенный момент времени. В частности, для обучения нужно знать, какой ранг занимает пост в одном тематическом подразделе (subreddit), однако здесь необходима обратные вызовы, что вряд ли будет поддерживать микросервис.
При полном отказе от микросервисов нарушится инкапсуляцию и чтение из дампов СУБД. Однако, теперь возможны обратные вызовы API и подключение датасетов непосредственно к Apache Spark или другому Big Data приложению пакетной или потоковой обработки. Можно объединять таблицы и удобнее работать с данными, создавая обучающие датасеты со такой скоростью, с какой Spark Streaming и MLLib могут обрабатывать их.
При этом стоит помнить, что ML-сервисы зависят от схемы необработанных данных, которые обучно хранятся в корпоративном озере (Data Lake) на базе Apache Hadoop. Но, как мы разбирали вчера, схемы данных меняются со временем, микросервисы выводятся из эксплуатации и заменяются новыми решениями, накапливаются несоответствия, ошибки и прочие проблемы. Кроме того, каждая команда ML-разработки должна поддерживать собственные data pipeline’ы, чтобы они не превратились в архаичный спагетти-код. На это уходит много времени и ресурсов.
Альтернативой является использование платформы потоковой обработки событий, такой как Apache Kafka, чтобы ML-команды подписывались на нужные потоки событий. В отличие от дампов Data Lake, потоки событий обычно содержат данные более высокого качества. Но здесь появляется проблема холодного запуска, т.к. платформы потоковой передачи событий обычно редко предназначены для длительного хранения событий. Проблема холодного запуска проявляется при создании новой фичи с отслеживанием состояния, которая требует агрегации событий за определенный промежуток времени. Например, количество сообщений, опубликованных пользователем за последние 7 дней. В таких ситуациях создание обучающего датасета может занять несколько недель. А при том, что Feature-engineering – итеративный процесс, общее время разработки продукта растягивается еще больше.
Чтобы решить проблему микросервисной архитектуры в Machine Learning, многие data-driven компании независимо друг от друга пришли к одному и тому же выводу: AirBnB построил Zipline, Uber создал Michelangelo, а Lyft разработал Dryft. Сюда же можно отнести StreamSQL [2]. Все эти системы называются хранилищами фичей (Feature Store), которые предоставляют стандартизированный способ их определения. Feature Store обрабатывает создание обучающих данных и предоставляет фичи онлайн для различных сервисов, абстрагируя инжиниринг данных от рабочего ML-процесса. Под капотом Feature Store координирует несколько Big Data систем для беспрепятственной обработки событий, как недавно случившихся, так и исторических [1].
Машинное обучение в Apache Spark
Код курса
MLSP
Ближайшая дата курса
по запросу
Продолжительность
16 ак.часов
Стоимость обучения
48 000 руб.
Что такое Feature Store: пример использования StreamSQL
Возвращаясь к рассматриваемому кейсу с персонализацией канала Reddit, в исходной микросервисной архитектуре каждая служба владела своими данными: микросервис сообщений — это источник данных о сообщениях, микросервис пользователя – о пользователях и т.д. Здесь используется StreamSQL, которое ускоряет разработку машинного обучения за счет [2]:
- создание фичей ML-модели с использованием декларативных определений;
- генерация обучающих датасетов с теми же определениями фичей, что и в использовании;
- управление версиями, мониторинг и управление фичами;
- возможность совместного и повторного использования, а также обнаружения фичей в разных командах и ML-моделях.
StreamSQL создает собственные представления этих данных в своих внутренних структурах путем обработки потока доменных событий в материализованном состоянии. События домена – это логические события, например, когда пользователь голосует за статью или создается новый пост. Материализованное представление – это результат выполнения запроса к потоку событий. К примеру, если нужно, чтобы ML-модель знала количество сообщений, за которые пользователь проголосовал, можно создать материализованное представление с помощью SQL-запроса:
SELECT user, COUNT(DISTINCT item) FROM upvote_stream GROUP BY user;
Все материализованные представления существуют в одном хранилище фичей и предварительно обрабатываются для использования ML. Объедение данных микросервисов в одно монолитное хранилище устраняет проблемы, связанные с получением фичей в реальном времени. Теперь фичи можно получить за один раз. Дополнительным преимуществом Feature Store является устойчивость к сбоям, поскольку материализованные представления хранятся в высокодоступном и в конечном итоге согласованном хранилище данных. Таким образом, фичи согласованы с входящими событиями. По сути, Feature Store является зеркалом таблиц микросервисов, храня уже предварительно обработанные данные для машинного обучения в одном месте. В отличие от микросервисов, Feature Store сохраняет каждое входящее событие в логе на неопределенное время. Так журнал событий становится источником истины для системы, что соответствует шаблону проектирования называется Event Sourcing, позволяя генерировать обучающий датасет для ML-моделей.
В качестве иллюстративного примера с соцсетью Reddit, рассмотрим предсказание следующего пост, за который пользователь проголосует. Соответствующие события домена передаются в хранилище фичей, которое затем обновляет входные фичи модели Machine Learning. Наблюдаемые результаты также должны быть переданы в Feature Store:
feature_store.append_observation (userId, postId, now ());
Поскольку в Feature Store ведется журнал каждого события и логика для преобразования потока событий в состояние, оно может получать состояние фичей в любой момент времени:
def generate_training_set(): for observed in observations: feature_store.process_events_until(observed.time) features = feature_store.get_features(observed.userId) yield (features, observed.postId)
Таким образом, хранилище фичей позволяет отделиться от микросервисной архитектуры, обеспечивая долговременное хранение и своевременное использование признаков для ML-модели, как это сделано в Airbnb, о чем мы рассказываем здесь. Однако, практическое внедрение Feature Store требует определенных условий [1], о которых мы поговорим в следующий раз. А о том, как Feature Store используется в микросервисной системе бразильской фудтех-компании Ifood, читайте в нашей новой статье.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
19 мая, 2025
Продолжительность
24 ак.часов
Стоимость обучения
72 000 руб.
Освоить на практике эти и другие приемы проектирования ML-систем, а также особенности применения Apache Kafka и Spark для аналитики больших данных вы сможете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
- https://medium.com/analytics-vidhya/why-microservices-suck-for-machine-learning-and-how-a-feature-store-makes-it-better-c34fa0d00b92
- https://docs.streamsql.io/

