 1083
1083 
Содержание
В рамках продвижения нашего нового курса по графовой аналитике больших данных в бизнес-приложениях, сегодня разберем, как Airbnb использует графовые нейросети для улучшения машинного обучения. А также рассмотрим, как устроены GCN-нейросети и что определяет выбор между потоковым и пакетным ML-конвейером.
Анализ графов для обогащения ML-моделей
Многие проблемы машинного обучения могут быть сформулированы как задачи на графах. Например, на платформе Airbnb пользователи делятся фотографиями и взаимодействуют друг с другом через обмен сообщениями, бронирования, отзывы. Эти связи между пользователями естественным образом образуют ребра, которые можно использовать для создания графа. Но обычно специалисты по Data Science не используют эти соединения при построении моделей машинного обучения, а рассматривают узлы (в данном случае пользователей) как полностью независимые сущности. Хотя это упрощает ситуацию, отсутствие информации о соединениях узла может снизить производительность модели из-за игнорирования того, где этот узел находится в контексте общего графа.
Чтобы улучшить клиентский опыт своих пользователей, специалисты по Data Science в Airbnb решили применить отдельные методы графовой аналитики, в частности, сверточные сети графов, для улучшения своих моделей машинного обучения. Рассмотрим сценарий, когда новый арендодатель присоединяется к платформе бронирования и заполняет типовую форму, оставляя первичные данные о себе: локацию объекта недвижимости, номер телефона и пр. Эти прямые атрибуты, хотя и необходимы, являются относительно поверхностными и не обязательно позволяют понять их надежность и репутацию арендодателя. Чтобы узнать о новом арендодателе больше информации, можно обратиться к его окружению, рассмотрев связи с другими пользователями. Например, с кем он поделился фотографиями своего объекта недвижимости или обменялся сообщениями.
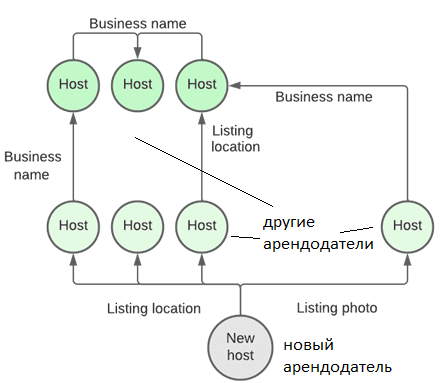
Визуализировав это, можно увидеть, например, что несколько арендодателей с привязкой к одной локации связаны друг с другом через ее общее название. Можно сделать выводы, что этот новый пользователь хозяин относится к существующей группе арендодателей, которые сдают квартиры в том же доме, но еще не обновили свой профиль, чтобы отразить это. Эта задача относится к анализу социальных связей, о чем мы писали здесь. Таким образом, анализ графов дает новые знания без необходимости прямого запроса сведений у самого пользователя. Так можно обогатить существующие ML-модели, что особенно важно в сценариях, где мало исторических данных или наблюдений, относящихся к пользователю. Хотя семантическая информация, получаемая из графа, выводится, а не сообщается пользователем напрямую, может дать базовый уровень знаний в условиях недостатка фактической информации. Как объединить графовую аналитику с методами машинного обучения, рассмотрим далее.
Графовые нейросети
Чтобы модели машинного обучения могли получать информацию из графов, нужно предоставить им эти данные в соответствующем виде. Одним из простых вариантов является вычисление статистики об узлах и использование ее в качестве числовых характеристик. Например, подсчитать количество пользователей, к которым общался конкретный пользователь, или количество фотографий, которыми он поделился. Эти метрики легко вычислить, и они дают общее представление о роли узла в общей структуре графа. Однако, эти метрики не используют возможности узла. Нужно иметь возможность производить агрегацию окрестности узла в графе, которая фиксирует как структурную роль узла в графе, так и его характеристики. Например, чтобы понять тип пользователей, с которыми общался рассматриваемый (срок действия их учетной записи или количество прошлых бронирований), потому что это дает больше подсказок об исходном пользователе, чем простые подсчеты.
Чтобы зафиксировать как структуру графа, так и функции узлов, можно использовать тип архитектуры графовой нейросети, называемый графовой сверточной сетью (Graph Convolutional Networks, GCN). Эти нейронные сети обычно принимают в качестве входных данных матрицу признаков узла в дополнение к матрице смежности графа и выводят выходные данные на уровне узла. Такой тип сетевой архитектуры предпочтительнее простого соединения предварительно вычисленных структурных признаков с узлами, поскольку он может совместно представлять два типа информации, что, вероятно, дает лучшее обогащение.
Графовые сверточные сети состоят из нескольких слоев:
- один слой предназначен для изучения представления узла, которое собирает информацию из своего окружения и объединяет информацию о своем соседстве со своими собственными функциями. В примере с новой учетной записью арендодателя, один слой GCN будет соседством с одним переходом.
- второй уровень, представляющий соседство хоста с двумя переходами, может быть введен для сбора дополнительной информации. Поскольку выходные данные уровня N GCN используются для создания представлений, используемых на уровне N+1, добавление слоев увеличивает диапазон агрегации, используемой для создания представлений узлов.
Таким образом, в рассматриваемом примере понадобится GCN с двумя слоями, чтобы создать эмбеддинг графа, который захватывает иллюстрированный подграф. На практике часто достаточно небольшого количества слоев, например, 2–4, поскольку соединения за пределами этой точки обычно зашумлены и вряд ли имеют отношение к исходному пользователю.
Приняв решение использовать GCN, следует подумать, насколько сложным должен быть метод каждого слоя для агрегирования функций соседних узлов. Есть множество методов агрегирования: объединение средних, объединение сумм, а также более сложные агрегаторы, включающие механизмы внимания. Кроме того, стоит помнить про частое переобучение модели из-за дрейфа концепций. Ограничив сложность алгоритма и количества моделей, которые необходимо переобучить, можно упростить процессы обслуживания ML-системы.
Примечательно, что не всегда GCN со сложными функциями агрегирования работают лучше. Например, архитектура Simplified GCN (SGC) показала, что можно достичь производительности, сравнимой с более сложными агрегаторами, используя слои GCN, которые не имеют обучаемых весов. Архитектура Scalable Graph Inception Network (SIGN) показала, что можно предварительно вычислить несколько агрегаций без обучаемых весов и использовать их параллельно в качестве входных данных для последующей модели. SIGN и SGC очень связаны: SIGN предоставляет общую платформу для предварительного вычисления агрегации графов, а SGC предоставляет самый простой агрегатор для использования в рамках SIGN.
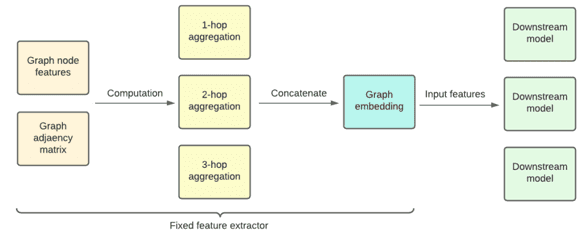
Используя SIGN и SGC, GCN становится чисто фиксированным экстрактором признаков, которому не нужно ничего изучать самому — у него нет весов, подлежащих настройке во время обучения. В этом случае можно принципиально рассматривать GCN как фиксированную математическую формулу, применяемую к ее входным данным, не беспокоясь об обучении с учителем или предварительном обучении самой GCN.
MLOps и работа модели в производстве
При обслуживании графовой нейросети основное внимание уделяется свежести данных и тому, как получить входные данные для модели в производственных условиях. Выбор между методами реального времени или пакетными методами влияет на то, насколько актуальна информация. Частично вопросы мониторинга дрейфа данных и модели решает концепция MLOps, которая сочетает машинное обучение, DevOps и управление данными для обеспечения надежного и эффективного цикла разработки, развертывания и обслуживания ML-систем в производстве согласно потребностям бизнеса. Подробнее об этом мы писали здесь.
Обработка в режиме реального времени позволяет предоставлять модели последующих стадий самой актуальной информации. Но это требует больше усилий для обслуживания эмбеддингов. Кроме того, здесь часто используется версия графа с пониженной дискретизацией для обработки узлов с большим количеством ребер, например, в алгоритме GraphSAGE. Автономные пакетные методы могут вычислять все вложения узлов одновременно, что снижает сложность реализации.
Учитывая компромиссы и требования, Data Science специалисты Airbnb в конечном итоге выбрали периодический автономный конвейер, который использует метод SIGN для начальной реализации. Простота обслуживания пакетных конвейеров и относительная простота SIGN позволяют изначально оптимизировать обучение, а не производительность. Хотя многие ML-модели работают в реальном времени, графовая модель стартовала в автономном режиме. Фичи вычисляются с использованием моментального снимка графа и узловых фич. При онлайн-извлечении этих фич нижестоящая модель просто ищет выходные данные предыдущего запуска в хранилище фич (Feature Store), вместо того, чтобы вычислять эмбеддинг в режиме реального времени. Альтернативное решение для внедрения графов в реальном времени потребовало бы значительной дополнительной сложности реализации.
Реализация пакетного конвейера позволила ML-инженерам Airbnb получить доступ к новой информации в виде фич для последующих моделей, что значительно улучшило их качества. Интерпретация результатов моделирования с помощью SAHP-подхода показала, что компоненты эмбеддинга входят в число ТОП-10 лучших фичей в последующих моделях. Поэтому Data Science специалисты компании решили продолжать исследовать другие типы графов, чтобы еще более повысить качество своих моделей Machine Learning.
Освойте инструменты графовой аналитики больших данных для машинного обучения и других бизнес-задач на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков больших данных в Москве:
- Графовые алгоритмы. Бизнес-приложения
- Графовые алгоритмы в Apache Spark
- Машинное обучение в Apache Spark
- Разработка и внедрение ML-решений
[elementor-template id=»13619″]
Источники

