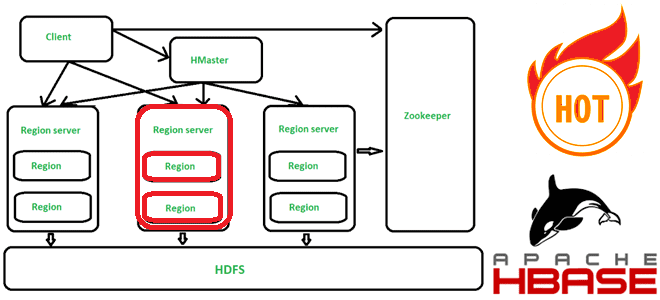
Что такое горячие точки в Apache HBase, почему они возникают, чем опасны и как их избежать. Для этого заглянем под капот NoSQL-хранилища, чтобы разобраться с особенностями хранения данных по ключу строки. Что такое горячие точки в кластере Apache HBase и почему они случаются Apache HBase представляет собой колоночно-ориентированное мультиверсионное хранилище...
Для продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим 5 самых известных языков запросов для управления данными графов. Что общего у GraphQL, Gremlin, Cypher, SPARQL и AOL, а также чем они отличаются. GraphQL Языки запросов, используемые для управления данными графов (GQL, Graph Query Language), определяют способ извлечения...
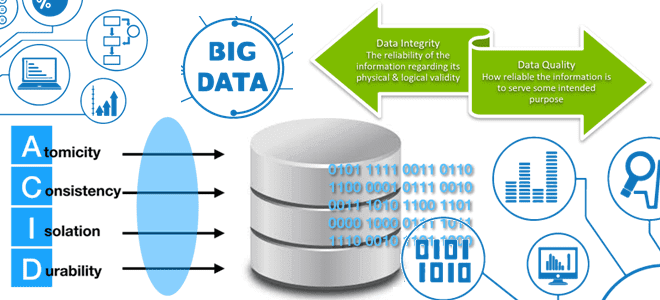
Чем целостность данных отличается от их качества и как реализуются ACID-свойства распределенных транзакций в Big Data системах. Разбираем понятия и технологии, важные для обучения ИТ-архитекторов и дата-инженеров. Целостность и качество данных: versus или вместе? Целостность данных и качество данных — связанные, но разные понятия, важные для дата-инженера. Целостность описывает точность...
Мы уже писали о важности резервного копирования данных в Apache HBase на примере ИТ-компании Clairvoyant. Сегодня рассмотрим опыт индийской компании Myntra, которая предложила простую методику создания инкрементных бэкапов для Apache HBase 2.1.4 и Hadoop 2.7.3, а также восстановления нужных данных из этих резервных копий в BLOB-хранилищах по требованию пользователя. 5...
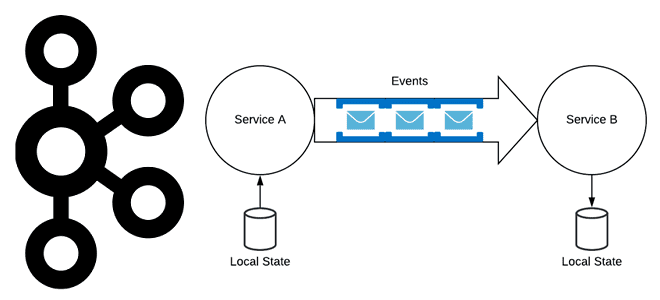
Хотя Apache Kafka часто используется в качестве шины обмена данными в микросервисной архитектуре, о чем мы писали здесь, не стоит воспринимать эту платформу как хранилище событий. В чем разница между событием и сообщением, а также другие тонкости построения микросервисной архитектуры, управляемой событиями. События vs сообщения Событие — это сообщение программной...

Использование СУБД вместо очереди сообщений считается антипаттерном, однако, команда разработки облачной системы организации конвейеров обработки данных Dagster Cloud выбрала PostgreSQL вместо Apache Kafka для регистрации событий. Разбираемся, почему плохой шаблон принес хорошие результаты и что нужно учитывать при выборе технологии. Почему не стоит использовать СУБД вместо очереди сообщений Dagster Cloud...
Недавно мы писали про сравнения технологий потоковой аналитики больших данных и аналитических баз данных реального времени на примере сравнения ksqlDB и Rockset. Продолжая этот разговор про архитектуру данных и приложений, сегодня рассмотрим сходства и отличия потоковых баз данных со stateful-приложениями обработки событий в реальном времени. 2 технологии потоковой обработки: stateful-приложения...
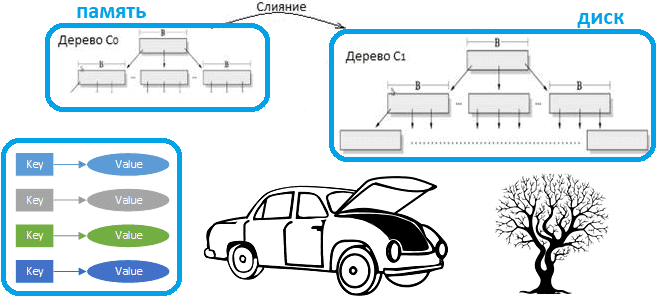
Что такое LSM-дерево и как эта структура данных, лежащая в основе многих NoSQL-баз с распределенным типом ключ-значение, позволяет им обеспечивать высокую скорость записи и чтения. Смотрим на примере Apache HBase. Зачем нужны LSM-деревья Типичная СУБД состоит из нескольких компонентов, каждый из которых отвечает за обработку различных аспектов хранения, поиска и...
Сегодня рассмотрим, чем отличаются подходы к представлению данных в глубоком машинном обучении и реляционной логике, как это связано с декларативной парадигмой логического программирования и при чем здесь графы. А в качестве примера реализации этих идей рассмотрим комбинацию принципов Deep Learning с реляционной логикой и GNN-нейросетями в Python-библиотеке PyNeuraLogic. Машинное обучение...

Хотя Apache Pig сегодня не самый актуальный инструмент для аналитики больших данных в экосистеме Hadoop, дата-инженеру полезно знать его основные принципы работы и ключевые отличия от Hive. Также рассмотрим, чем Hive отличается от Pig в качестве средства SQL-on-Hadoop. Что такое Apache Pig Apache Pig – это высокоуровневый процедурный язык для...

В рамках продвижения нашего нового курса по графовой аналитики больших данных, сегодня рассмотрим, как создать граф социальных связей в веб-консоли Neo4j и сделать запросы к нему на Cypher - внутреннем SQL-подобном языке этой NoSQL-СУБД. Как построить граф социальных связей в Neo4j Возьмем в качестве примера набор деловых и личных взаимоотношений...
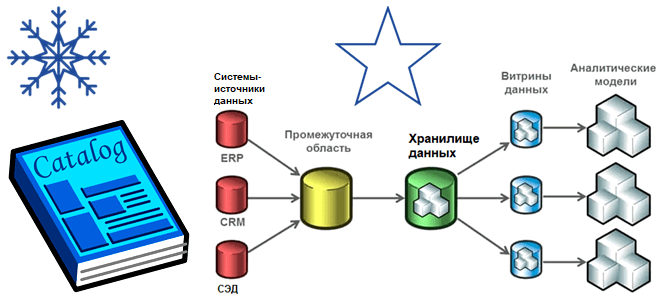
Хотя современная аналитика больших данных чаще базируется на Data Lake, Data Mesh, Delta Lake и DeltaLakeHouse, многие компании до сих пор активно используют классические витрины и хранилища. Разбираем особенности этих архитектур, а также оцениваем их применимость к текущим потребностям бизнеса. Витрины и хранилища данных Витрина данных (Data Mart) предоставляет информацию...
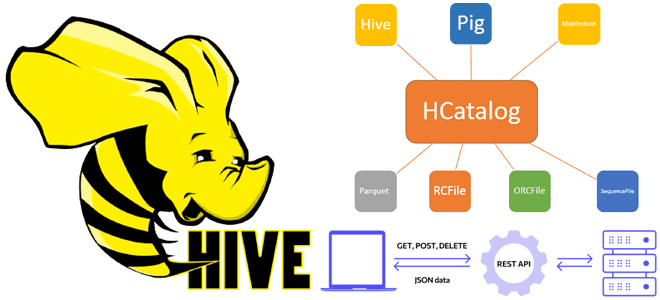
Сегодня рассмотрим, что такое WebHCat в Apache Hive и как этот REST API позволяет взаимодействовать с HCatalog, используя стандартные HTTP-методы. Еще разберем, какие DDL-команды Hive и HiveQL не поддерживает HCatalog, а также что полезного может быть в лог-файлах Templeton. Принципы работы компонента WebHCat как REST-сервиса Apache Hive Будучи NoSQL-хранилищем класса...

В этой статье для обучения ИТ-архитекторов и дата-инженеров сравним 2 подхода к аналитике больших данных, чтобы решить, когда потоковые вычисления, например, средствами ksqlDB в рамках Apache Kafka лучше аналитических баз данных реального времени, таких как Rockset, и наоборот. 2 способа выполнения аналитики больших данных в реальном времени Современный бизнес и...

16 ноября 2022 года вышел 2-ой альфа-релиз Apache Hive 4.0.0. Какие ошибки в нем исправлены и что за новые функции, важные для дата-инженера и администратора кластера Hadoop, появились. А перед этим вспомним основные принципы работы Apache Hive. Принципы работы Apache Hive Apache Hive является популярным инструментом стека SQL-on-Hadoop, позволяя обращаться...
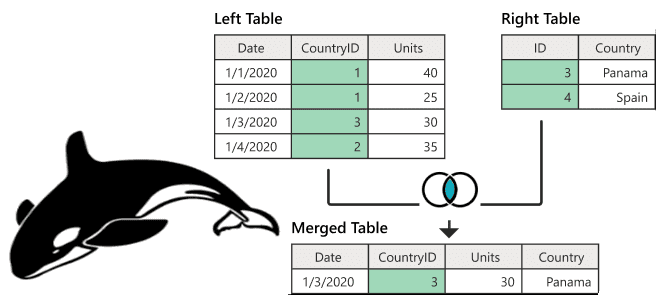
Поиск данных по нескольким таблицам в реляционных базах данных реализуется через SQL-запрос с оператором JOIN. В NoSQL-хранилищах такая возможность может отсутствовать. Разбираем, как соединить таблицы в Apache HBase и причем здесь MapReduce. Варианты реализации JOIN в Apache HBase Будучи популярной NoSQL-базой, которая реализует возможности Google BigTable для Apache Hadoop, HBase...

Сегодня рассмотрим, зачем нужно внешнее хранилище метаданных для Apache Hive, и как запустить его высокодоступный и масштабируемый сервис в Amazon EKS путем контейнеризации приложения. Зачем нужно внешнее хранилище метаданных Apache Hive? Apache Hive используется для доступа к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Это NoSQL-хранилище...

Недавно мы рассматривали, как дата-инженеры Airbnb перевели аналитические нагрузки корпоративного озера данных с Apache Hive на Iceberg и Spark. Продолжая разговор про эти фреймворки реализации Data Lake, сегодня разберем стратегии миграции озера данных с Apache Hive на Iceberg. Зачем уходить с Apache Hive на Iceberg и как это сделать Напомним,...

Какова роль каталогов метаданных в корпоративных Data Lake, почему Hive Metastore не отвечает всем потребностям современной дата-инженерии в гибком управлении данными и в чем преимущества формата открытых таблиц Iceberg над таблицами Hive и Delta Lake. Каталоги метаданных в Data Lake Для организации данных в корпоративных озерах используются каталоги метаданных, которые...

Каждый разработчик и дата-аналитик с закрытыми глазами напишет SQL-запрос с регулярными выражениями для поиска данных по шаблону в реляционной базе. А вот в NoSQL-СУБД такая простая задача реализуется довольно сложно. Как написать регулярное выражение в Apache HBase и запустить его на исполнение в CLI-интерфейсе shell-оболочки этого хранилища данных. Что такое...