Чем слотовая среда выполнения Cypher-запросов в Neo4j отличается от конвейерной, как ее задать и что выбрать для транзакционных и аналитических сценариев работы с графами: наглядные примеры.
Слотовая среда выполнения
В графовой NoSQL-СУБД Neo4j есть три типа среды выполнения Cypher-запросов: слотовая, конвейерная и параллельная. В большинстве случаев среды выполнения по умолчанию (конвейерная среда выполнения в Enterprise Edition) обеспечивают наилучшую производительность запросов. Однако каждая среда выполнения имеет свои преимущества и недостатки, и существуют сценарии, когда принятие решения о том, какую среду выполнения использовать, является важным шагом на пути к максимизации эффективности запросов.
Прежде чем разбираться с каждой из них, стоит вспомнить типовую последовательность выполнения Cypher-запроса. Изначально он представляет собой строку с выражением о шаблоне поиска данных в графе. Эта строка обрабатывается анализатором запросов и преобразуется во внутреннее представление (AST, абстрактное синтаксическое дерево), которое проверяется и очищается. Это AST-дерево принимает планировщик – оптимизатор запросов, который создает план выполнения запроса. План состоит из различных операторов — специализированных модулей выполнения, которые выполняют конкретную задачу преобразования данных. После создания плана запроса среда выполнения запроса выполняет план, созданный планировщиком.
Слотовая среда выполнения является средой выполнения по умолчанию для Neo4j Community Edition. Пользователи Neo4j Enterprise Edition должны добавить в свой запрос выражение CYPHER runtime = slotted, чтобы выполнить его в слотовой среде выполнения.
Физический план, создаваемый слотовой средой выполнения, представляет собой взаимно однозначное отображение логического плана, где каждый логический оператор сопоставляется с соответствующим физическим оператором и где операторы обрабатываются строка за строкой. При использовании слотовой среды выполнения каждая переменная в запросе получает выделенный слот, который используется для доступа к данным, сопоставленным с данной переменной. Слотовая среда выполнения использует традиционную модель выполнения большинства баз данных, известную как итератор или модель «Вулкан». Это процесс, основанный на извлечении, где каждый оператор в дереве «извлекает» строки данных из своего дочернего оператора с помощью функции виртуального вызова. Таким образом, данные поднимаются из нижней части плана выполнения в верхнюю, создавая поток данных, похожий на извержение. Слотовая среда выполнения в Neo4j является интерпретируемой, интерпретируя логический план, отправленный планировщиком по операторам. В целом это удобный и гибкий подход, способный обрабатывать все операторы и запросы. Слотовая среда выполнения концептуально аналогична интерпретируемым языкам программирования в том смысле, что она имеет более короткую фазу планирования, поскольку не требуется генерировать весь код для запроса перед выполнением, в отличие от компилируемых сред. Рассмотрим пример Cypher-запроса к графу банковских транзакций, о котором я писала в прошлой статье, в слотовой среде выполнения. Чтобы вывод был более полным, вместо оператора EXPLAIN, используем PROFILE, который не просто формирует план, но и фактически запускает его на выполнение.
PROFILE CYPHER runtime = slotted MATCH p=()-[t:transaction]->() WHERE t.summa>100 RETURN p;

Как показывают результаты выполнения этого запроса в слотовой среде, было выполнено 243 обращения к базе данных и потребно 64 байта выделенной памяти. Потоковая передача 22 записей начата через 42 мс и завершена через 63 мс.
В большинстве случаев пользователям Neo4j Enterprise Edition не приходится применять слотовую среду выполнения. Но в некоторых сценариях это может пригодиться. Например, когда приложение генерирует короткие запросы, которые не кэшируются, т. е. никогда или очень редко повторяются. Тогда слотовая среда выполнения предпочтительнее из-за более быстрого времени планирования. Но непрерывный вызов виртуальных функций между каждым оператором использует циклы ЦП, что приводит к замедлению выполнения запроса. Кроме того, модель итератора может привести к плохой локальности данных, что может замедлить выполнение запроса, т.к. процесс извлечения отдельных строк от разных операторов затрудняет эффективное использование кэша ЦП.
Конвейерная среда выполнения
Конвейерная среда выполнения используется по умолчанию в Neo4j Enterprise Edition. Чтобы выполнять запросы в конвейерной среде выполнения в Community Edition, надо добавить к запросу CYPHER runtime = pipelined.
План выполнения запроса в конвейерной среде сильно отличается от плана в слотовой, т.к. запросы не выполняются по одной строке за раз. Конвейерная среда выполнения позволяет физическим операторам потреблять и создавать фрагменты – пакеты от 100 до 1000 строк, которые записываются в буферы, содержащие данные и задачи для конвейера. Конвейер, в свою очередь, можно определить как последовательность операторов, которые объединены друг с другом так, что они могут выполняться вместе в одной и той же задаче во время выполнения. Таким образом, логические операторы не сопоставляются с соответствующим физическим оператором при использовании конвейерной среды выполнения. Вместо этого дерево логических операторов преобразуется в граф выполнения, содержащий конвейеры и буферы.
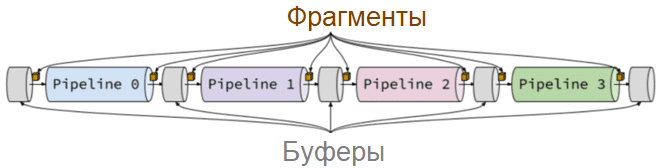
В этом графе выполнения начинается выполнение запроса, конвейер под номером 0 (pipeline 0), который в конечном итоге создаст фрагмент, который будет записан в буфер конвейера 1. Как только появятся данные для обработки pipeline 1, он может начать выполнение и записать данные для обработки следующим конвейером и так далее. Таким образом, данные перемещаются по графу выполнения. Конвейерная среда выполнения — это модель выполнения на основе push-уведомлений, в которой данные передаются от конечного оператора к его родительским операторам. В отличие от pull-моделей, которые использует среда выполнения с интервалами, данные могут храниться в локальных переменных. Это позволяет напрямую использовать регистры ЦП, улучшает использование кэшей ЦП и устраняет дорогостоящие вызовы виртуальных функций, используемые в pull-моделях. Конвейерная среда выполнения идеально подходит для случаев транзакционного использования, когда в системе параллельно выполняется большое количество запросов. Это охватывает большинство сценариев использования и по этой причине является средой выполнения Neo4j по умолчанию.
Конвейерная среда выполнения является комбинированной, т.е. может использовать интерпретируемую или скомпилированную среду выполнения. Справедливости ради стоит отметить, что такая классификация не совсем точна, т.к. большинство реализаций среды выполнения не полностью интерпретируются и не полностью компилируются, а скорее представляют собой смесь двух стилей. Например, когда слотовая среда выполнения запускается в Neo4j Enterprise Edition, код генерируется для выражений, включенных в запрос. Тем не менее, слотовая среда выполнения считается интерпретируемой, поскольку это преобладающий метод реализации.
В конвейерной среде выполнения преимущественно используется вариант компиляции, поэтому она считается компилируемой. В отличие от интерпретируемых сред выполнения, компилируемые имеют фазу генерации кода, за которой следует фаза выполнения. Это обычно приводит к увеличению времени планирования запроса, но к более короткому времени выполнения. Для большинства запросов конвейерная среда выполнения является более эффективной средой выполнения, способной обрабатывать все операторы и запросы.
Чтобы сравнить, чем отличается конвейерная среда от слотовой на практическом примере, запустим ранее представленный пример Cypher-запроса к графу банковских транзакций из прошлой статьи.
PROFILE CYPHER runtime = pipelined MATCH p=()-[t:transaction]->() WHERE t.summa>100 RETURN p;
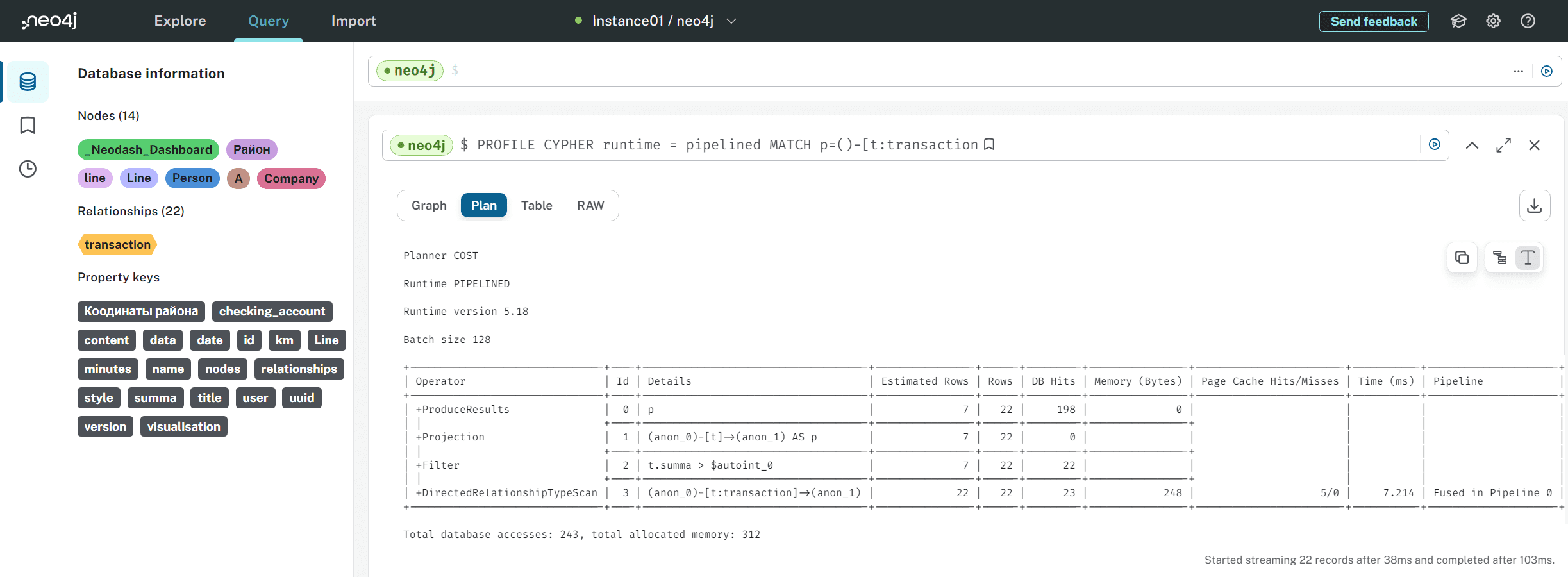
Как и в случае слотовой среды, было выполнено 243 обращения к базе данных, однако, выполнение запроса потребовало 312 байта выделенной памяти, т.е. выполнение простого запроса в конвейерной среде выполнения заняло в 2 раза больше выделенной памяти JVM. Потоковая передача 22 записей началась через 38 мс и завершена через 103 мс.
Таким образом, для простых запросов слотовая среда выполнения работает быстрее и требует меньше ресурсов из-за более быстрого времени планирования. Однако, в случае транзакционного запроса с большим объемом данных конвейерная среда выполнения будет более эффективной.
Также в версии Neo4j 5.13 представлена параллельная среда выполнения, которая устраняет недостатки конвейерной, что рассмотрим в следующий раз. А пока напомню, что научиться использовать графовые СУБД для аналитики больших данных вам помогут специализированные курсы нашего лицензированного учебного центра обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники