Как реализовать гибридную архитектуру данных Lakehouse на новой платформе Chango с движком обработки распределенных запросов Trino без дополнительного развертывания кластера Kafka и разработки Spark-приложений потоковой передачи событий. Что такое Trino: принципы работы распределенного SQL-движка О том, что представляет собой новая гибридная архитектура данных под названием Lakehouse, мы подробно писали здесь,...

Где создать граф знаний и попробовать графовые алгоритмы для решения бизнес-задач: смотрим варианты запуска графовой СУБД на примере Neo4j. 4 варианта запуска Neo4j Neo4j является ярким представителем нереляционных СУБД и относится к категории графовых баз. Она поддерживает специализированные алгоритмы работы с графами, включая поиск путей, выявление сообществ, анализ связей и...
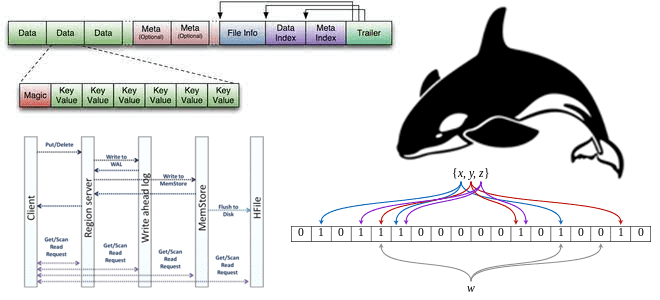
Что такое HFile, как появился этот низкоуровневый файловый формат, каковы его главные принципы работы, как Apache HBase использует его для хранения и быстрой аналитики больших данных, и при чем здесь фильтр Блума. Роль HFile в Apache HBase Apache HBase реализует возможности Google BigTable для Hadoop. Эта NoSQL-СУБД типа «семейство колонок»...

Что такое потоковая аналитика больших данных, какие бывают СУБД потоковой передачи, когда и зачем их использовать, а также что влияет на выбор этих инструментов хранения и аналитической обработки Big Data. Что такое потоковые базы данных и как они работают Мы уже упоминали, что аналитика данных в реальном времени может быть...
Недавно мы писали про резидентную графовую СУБД Memgraph, которая хранит данные в оперативной памяти. Сегодня рассмотрим, как выгрузить граф знаний из Memgraph на диск с помощью библиотеки GQLAlchemy, а также поговорим про персистентность другого популярного NoSQL-хранилища Redis, которое также является резидентным, но относится к семейству key-value. Как сохранить данные из...
Как Lakehouse объединяет пакетную и потоковую обработку, какие проблемы возникают при реализации этой гибридной архитектуры данных и каким образом они решаются с помощью Delta-подхода и Apache Spark Structured Streaming. Краткая история появления дельта-архитектуры от лямбда- и каппа-моделей Мир больших данных постоянно развивается: появляются новые технологии и архитектурные шаблоны. В частности,...

Что общего у Apache HBase с Google Bigtable, чем они отличаются и какую NoSQL-СУБД выбирать для практического использования. Чем похожи NoSQL-хранилища для больших данных Apache HBase часто называют Google BigTable для Hadoop, поскольку она обеспечивает аналогичные возможности и использует многие концепции этой облачной NoSQL-СУБД. В частности, именно Bigtable был выпущен...

В рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях сегодня познакомимся с графовой резидентной СУБД Memgraph и сравним ее с Neo4j, определив достоинства, недостатки и варианты использования в задачах аналитики больших данных. Memgraph vs Neo4j Memgraph — это высокопроизводительная графовая СУБД с открытым исходным кодом, которая хранит и...
Инструменты графовых алгоритмов для аналитики больших данных в PostgreSQL и Greenplum: обзор расширений и возможностей. Знакомимся с Apache AGE и MADlib. Графовая аналитика в PostgreSQL Реляционные СУБД отлично подходят для хранения данных с четкой структурой практически в любой предметной области и предлагают широкие возможности аналитической обработки таких данных. Но иногда реляционная...
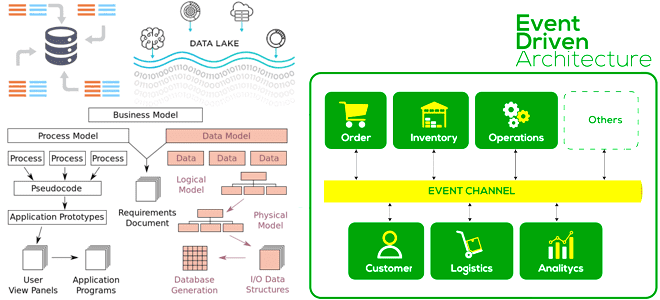
Чем схема, применяемая к данным, при чтении отличается от схемы при записи, почему она вызывает GIGO-проблему в Data Lake, и как применить принципы функциональной дата-инженерии к архитектуре данных, управляемой событиями. Схема при чтении или при записи: главное отличие NoSQL-решений от реляционных СУБД NoSQL-решения и Apache Hadoop реализуют стратегию «схема при...

Сегодня на примере Apache HBase и Redis разберемся со сходствами и отличиями NoSQL-СУБД типа «семейство колонок» и «ключ-значение». Что между ними общего и что выбирать для практического использования в зависимости от сценариев применения. 3 типа NoSQL-хранилищ данных Apache HBase и Redis являются довольно популярными базами данных среди NoSQL-решений. Однако, они...

Как организовать эффективное планирование заданий Apache Spark в микросервисной архитектуре, управляемой событиями, с помощью паттернов Idempotent Consumer и Transactional Outbox. Проблемы оркестрации Spark-заданий shell-скриптами и переход к EDA-архитектуре При большом количестве приложений Apache Spark, которые взаимодействуют друг с другом как самостоятельные микросервисы, растет сложность управления ими. В частности, shell-скрипты позволяют...

Что общего у Neo4j с TigerGraph и чем они отличаются: разбираемся с популярными графовыми СУБД и их возможностями для аналитики больших данных в рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях. Сравнение Neo4j с TigerGraph Подробно об архитектуре, принципах работы, функциональных возможностях и вариантах использования TigerGraph мы писали...

Зачем биотехнологической платформе Polly от Elucidata понадобился API SQL-запросов в облачном сервисе Elasticsearch и как дата-инженеры реализовали его, развернув Delta Lake с AWS Atnena и S3. Что не так с SQL-запросами в облачном Elasticsearch на AWS Ежедневно биотехнологическая платформа Polly от Elucidata обрабатывает гигабайты биомолекулярных данных для биологов по всему...

Метод ближайших соседей активно используется в машинном обучении для решения задач классификации в различных бизнес-приложениях. Познакомимся поближе с этим алгоритмом Machine Learning, а также разберем, почему NoSQL-хранилище Apache HBase отлично подходит для работы с ним. Что такое метод ближайших соседей: ликбез по Machine Learning В проектах Machine Learning и приложениях...

Сегодня в рамках продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях, решим классическую задачу логистики в графовой базе данных Neo4j без использования методов ее специальной библиотеки Graph Data Science, а средствами Cypher-запросов. Постановка задачи: критерии оценки для поиска кратчайшего пути Поиск кратчайшего пути – это классическая задача на графах,...
Как данные хранятся на диске при разной ориентации хранилища в СУБД: чем отличаются колоночные базы от строковых с точки зрения практического использования в дата-инженерии. Сравнительная таблица с примерами и выводами. Как данные хранятся на диске и при чем здесь ориентация СУБД Способы хранения данных в СУБД можно разделить на 2...

Сегодня в рамках обучения администраторов SQL-on-Hadoop рассмотрим, как защитить данные в кластере Apache HBase от несанкционированного доступа. Аутентификация и авторизация пользователей, операторы управления доступом к таблицам, метки видимости и шифрование данных. Механизмы защиты данных в Apache HBase Как и любое хранилище, колоночно-ориентированная мультиверсионная NoSQL-СУБД типа key-value Apache HBase, которая работает...

Продолжая разговор про языки запросов к графовым базам данных, сегодня познакомимся с GSQL, который поддерживается в MPP-СУБД TigerGraph. Как работает эта распределенная NoSQL-база данных и каким образом реализует ACID-требования к транзакциям в операциях с графами. Архитектура и принципы работы графовой MPP-СУБД TigerGraph — это распределенное графоориентированное хранилище данных с массивно-параллельной...
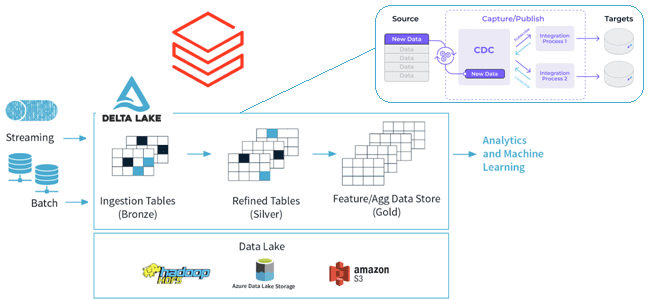
Как реализовать CDC для Delta Lake: разбираемся с функцией Change Data Feed от Databricks, которая позволяет быстро узнать обо всех изменениях строк в дельта-таблицах озера данных. Польза и принципы работы CDF для дата-инженера и архитектора данных. CDC для Delta Lake Идея сбора и обработки не всего объема данных, а только...