 650
650 
Содержание
Тонкости параллельной среды выполнения Cypher-запросов в NoSQL-СУБД Neo4j и критерии выбора runtime для аналитических и транзакционных сценариев работы с графами.
Слотовая и конвейерная среды выполнения
Вообще в графовой NoSQL-СУБД Neo4j есть три типа среды выполнения Cypher-запросов: слотовая, конвейерная и параллельная. По умолчанию в версии в Community Edition используется слотовая, а в Enterprise Edition – конвейерная. Их главное отличие в том, что в слотовой среде физический план запроса – это взаимно однозначное отображение логического плана, т.е. каждый логический оператор сопоставляется с соответствующим физическим, и операторы обрабатываются строка за строкой. Каждая переменная в запросе получает выделенный слот, который используется для доступа к данным, сопоставленным с данной переменной. В конвейерной среде выполнения запросы не выполняются по одной строке за раз, а данные перемещаются по графу выполнения запроса из конвейеров и буферов. В этот граф выполнения преобразуется дерево логических операторов.
Как показал небольшой эксперимент в прошлой статье, для простых аналитических запросов слотовая среда выполнения работает быстрее и требует меньше ресурсов из-за более быстрого времени планирования. Однако, в случае транзакционного запроса с большим объемом данных конвейерная среда выполнения будет более эффективной.
В конвейерной среде Cypher-запросы выполняются последовательно процессом из нескольких последовательных потоков операционной системы. Каждый поток выполняет какое-то количество операций, нужных для обработки запроса. Запрос последовательно проходит через все звенья потокового конвейера, потоки в котором в каждый момент времени обрабатывают разные запросы. Такой подход хорошо масштабируется, позволяя использовать преимущества процессора с несколькими ядрами. Но если запрос обрабатывает не локальную часть графа, а почти весь граф, производительность конвейерной среды выполнения падает. Поэтому в Neo4j 5.13 появилась параллельная среда выполнения Cypher-запросов, особенности и сценарии применения которой мы рассмотрим далее.
Параллельная среда выполнения Cypher-запросов
Как очевидно из названия, параллельная среда выполнения выполняет запросы параллельно, в отличие от слотовой и конвейерной, где запросы выполняются в одном потоке, назначенном одному ядру ЦП. Запуск выполнения на отдельных ядрах ЦП особенно важен при анализе больших графов. Параллельная среда выполнения является многопоточной и позволяет запросам потенциально использовать все доступные ядра на сервере, на котором работает Neo4j. Чтобы указать, что запрос должен использовать параллельную среду выполнения, надо добавить к нему выражение CYPHER runtime = parallel. Это возможно только в Enterprise-редакции. Для демонстрации этого я запустила Cypher-запроса к графу банковских транзакций. Чтобы вывод был более полным, вместо оператора EXPLAIN, использую PROFILE, который не просто формирует план, но и фактически запускает его на выполнение.
PROFILE CYPHER runtime = parallel MATCH p=()-[t:transaction]->() WHERE t.summa>100 RETURN p;
Как уже было отмечено, параллельная среда выполнения доступна только в Enterprise-редакции Neo4j. Поэтому в моем экземпляре Neo4j, развернутом на бесплатном тарифе в облачной платформе AuraDB, при попытке использовать параллельную среду выполнения, выдается ошибка.
Главное различие между физическими планами, созданными конвейерной и параллельной средами выполнения, состоит в количестве конвейеров. При выполнении запроса в параллельной среде эффективнее выполнять параллельно много задач, а при однопоточном выполнении в конвейерной среде лучше объединить несколько конвейеров вместе. Еще одно важное отличие состоит в том, что в параллельной среде выполнения используются партиционированные операторы, которые сначала разделяют полученные данные, а затем работают с каждым разделом параллельно.
Параллельная среда выполнения имеет ту же архитектуру, что и конвейерная, преобразуя логический план в граф выполнения операторов. Но в параллельной среде каждая задача может выполняться в отдельном потоке. Как и в конвейерной, запросы, выполняемые в параллельной среде, начинаются с создания первого конвейера, который в конечном итоге создает фрагмент во входном буфере последующего конвейера. В конвейерной среде одновременно может выполняться только один конвейер, тогда как параллельная среда выполнения позволяет конвейерам одновременно создавать фрагменты. Поэтому по мере завершения каждой задачи будет доступно все больше входных фрагментов, т.е. для выполнения запроса можно использовать больше рабочих процессов (worker’ов).
В Neo4j задача выполняет один конвейер для одного входного фрагмента и создает один выходной фрагмент. Если какое-либо условие препятствует завершению задачи, ее можно перепланировать как продолжение, чтобы возобновить ее позже. Планировщик отвечает за решение, какую единицу работы обрабатывать следующей. Планирование децентрализовано, и у каждого работника есть собственный экземпляр планировщика.
Например, следующий граф выполнения Cypher-запроса показывает, что выполнение начинается с pipeline 0, который состоит из оператора PartitionedNodeByLabelScan и может выполняться одновременно во всех доступных потоках, работающих с различными фрагментами данных. Как только pipeline 0 создаст хотя бы один полный фрагмент данных, любой поток может начать выполнение pipeline 1, а другие потоки могут продолжать выполнение pipeline 0. Как только из конвейера поступят данные, планировщик может перейти к следующему конвейеру, одновременно выполняя предыдущие. В этом случае pipeline 5 заканчивается агрегированием, выполняемым оператором EagerAggregation, и последний pipeline 6 не может запуститься до тех пор, пока все предыдущие конвейеры не будут полностью завершены для всех предыдущих фрагментов данных.
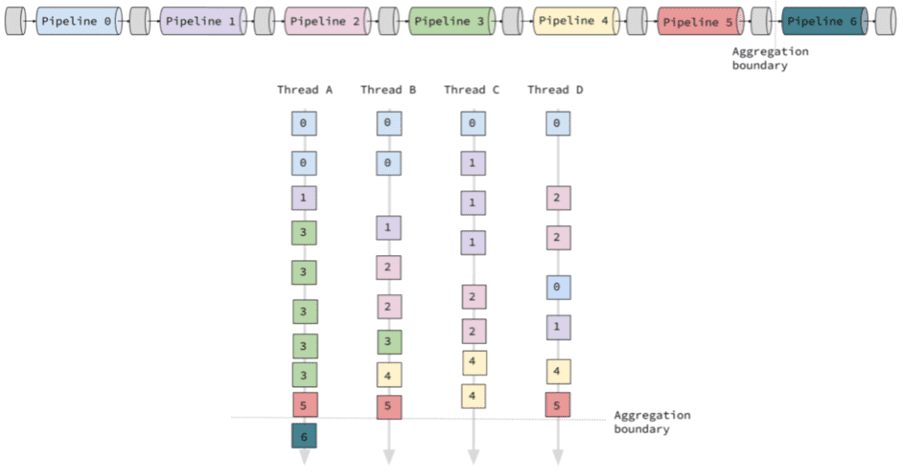
Разобравшись с принципами работы параллельной среды выполнения, далее рассмотрим варианты ее использования.
Какую среду выполнения выбрать в Neo4j?
Хотя точное время выполнения запроса зависит от его структуры, модели данных, загрузки системы и количества доступных ядер, в большинстве случаев длительные запросы (более 500 миллисекунд) будут выполняться значительно быстрее в параллельной среде выполнения, если доступно несколько ядер ЦП. Поэтому параллельная среда выполнения отлично подходит для аналитических запросов с глобальными графами, когда запросы не привязаны к конкретному начальному узлу, и охватывают большой участок графа. Если запросы начинаются с определенного узла, им подходит параллельная среда выполнения при соблюдении одного из следующих условий:
- начальный узел является суперузелом, т.е. кластером однотипных вершин;
- запрос переходит от этого узла к большой части графа.
Таким образом, сценарии использования параллельной среды выполнения более специфичны, чем универсальной конвейерной. В частности, параллельная среда выполнения поддерживает только аналитические запросы, т.е. на чтение. Она также не поддерживает функции процедур, которые не считаются потокобезопасными, т.е. они небезопасны для запуска из нескольких потоков. Более того, не все запросы будут выполняться быстрее при использовании параллельной среды выполнения. Например, локальный запрос к графу, который начинается с конкретного узла и продолжается сопоставлением только небольшой части графа будет даже работать медленнее в параллельной среде выполнения из-за планирования и дополнительного учета в нескольких потоках. Обычно параллельное выполнение невыгодно для запросов, выполнение которых занимает менее полсекунды.
Параллельная среда выполнения также может работать хуже, чем конвейерная, для запросов с подзапросами, где оператор сортировки ORDER BY используется для упорядочивания индексируемого свойства. Это связано с тем, что параллельная среда выполнения не может использовать индексы свойств для упорядочивания и поэтому должна повторно сортировать агрегированные результаты по выбранным свойствам, прежде чем возвращать их.
Наконец, хотя отдельные запросы могут выполняться быстрее при параллельном выполнении, общая пропускная способность базы данных может снизиться в результате выполнения множества одновременных запросов. Соответственно, параллельная среда выполнения не подходит для запросов транзакционной обработки с высокой пропускной способностью. Однако он идеально подходит для аналитических случаев использования, когда база данных выполняет относительно мало, но требует запросов на чтение.
Таким образом, для анализа графов с помощью Cypher-запросов параллельную среду выполнения в Neo4j следует рассматривать, если выполняются следующие условия:
- глобальные аналитические запросы предполагают обработку большой части графа;
- важна высокая скорость запросов;
- сервер имеет много процессоров и достаточно памяти;
- база данных имеет низкую параллельную рабочую нагрузку.
Разумеется, каждая среда выполнения имеет свои преимущества и недостатки, которые следует учитывать при выборе оптимального варианта. Для этого сравним все 3 среды выполнения по следующим критериям:
- модель исполнения запросов, т.е. передачи данных от одного оператора к другому (pull или push). В push-модели данные могут храниться в локальных переменных оператора и передаются от конечного оператора к его родительским операторам. Это позволяет напрямую использовать регистры ЦП, улучшает использование кэшей ЦП и устраняет дорогостоящие вызовы виртуальных функций, используемые в pull-моделях. В pull-модели каждый оператор в дереве запроса извлекает строки данных из своего дочернего оператора с помощью функции виртуального вызова, перемещая данные снизу вверх по плану выполнения, создавая поток.
- принцип выполнения физических операторов (построчно или пакетом);
- количество потоков ЦП (однопоточное или многопоточное исполнение);
- тип выполнения (компилируемая или интерпретируемая среда);
- сценарии использования в зависимости по типам запросов (аналитические на чтение или транзакционные на запись).
| Критерий сравнения | Среда выполнения | ||
| Слотовая | Конвейерная | Параллельная | |
| Модель исполнения | pull | push | push |
| Принцип выполнения физических операторов | построчно | пакет | пакет |
| Количество потоков ЦП | Однопоточный | Однопоточный | Многопоточный |
| Тип выполнения | Интерпретируемая | Компилируемая или интерпретируемая | Компилируемая или интерпретируемая |
| Сценарий использования | Аналитические на чтение и транзакционные запросы на запись | Аналитические на чтение и транзакционные запросы на запись | Только аналитические запросы на чтение |
В заключение стоит отметить, что далеко не каждый раз дата-аналитик и разработчик решает вопрос о выборе среды выполнения в Neo4j, однако если Cypher-запрос выполняется слишком медленно, возможно, стоит сменить runtime. Узнайте больше про тонкости использования графовых СУБД для аналитики больших данных на специализированных курсах нашего лицензированного учебного центра обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
[elementor-template id=»13619″]
Источники

