 663
663 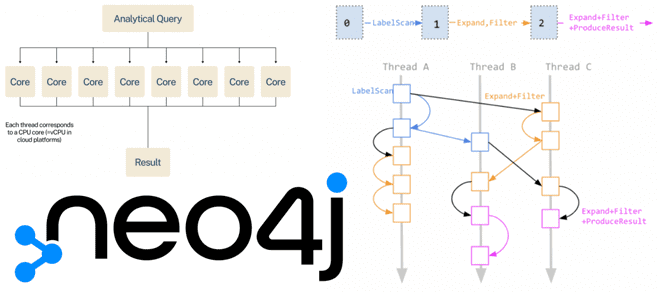
Как разработчики Neo4j улучшают производительность этой графовой СУБД с помощью нового блочного формата хранения данных и параллельной среды выполнения Cypher-запросов.
Блочный формат хранения данных
Наиболее важной новинкой Neo4j в релизе 5.14, вышедшего в конце ноября 2023 года, стал новый формат хранения данных – блочный, который размещает данные на диске в эффективной структуре, повышающей эффективность страничного кэша и предотвращающей фрагментацию данных. Отдельные страницы содержат больше связанных данных, что сокращает количество операций ввода-вывода в секунду для получения данных, необходимых для запроса. Поскольку эти данные располагаются на меньшем количестве страниц, обработка запроса требует меньше памяти. Также компактное хранилище с лучше поместится в непрерывные кэши ЦП. Подробнее об особенностях хранения данных в графовой БД мы писали здесь.
Преимущества нового блочного формата особенно важны для больших графов. Например, он может быть на 40% производительнее, когда весь граф находится в памяти. А если в памяти только 1/3 этого графа, рост производительности доходит до 70 %. Бета-версия нового блочного формата доступна в Neo4j Enterprise Edition версии 5.14, а общедоступная версия ожидается в начале 2024 года.
Параллельная среда выполнения в Neo4j
Однако, хранение данных – не единственный фактор, влияющий на скорость операций с графами в Neo4j. По умолчанию в этой СУБД используется конвейерная среда выполнения, где Cypher-запросы обрабатываются последовательно. Обрабатывающий процесс состоит из нескольких последовательных потоков операционной системы. Каждый поток выполняет какое-то количество операций, нужных для обработки запроса. Запрос последовательно проходит через все звенья потокового конвейера, в котором потоки в каждый момент времени обрабатывают разные запросы. Этот подход хорошо масштабируется, позволяя использовать преимущества многоядерного ЦП. Однако, он подходит не для всех сценариев. Например, если аналитический запрос обрабатывает большую часть графа, производительность конвейерной среды выполнения падает.
Поэтому в Neo4j 5.13 представлена еще новая среда выполнения Cypher-запросов, — параллельная. Чтобы понять, как она работает, вспомним типовую последовательность выполнения Cypher-запросов. Изначально Cypher-запрос представляет собой строку с выражением о шаблоне поиска данных в графе. Эта строка обрабатывается анализатором запросов и преобразуется во внутреннее представление (AST, абстрактное синтаксическое дерево), которое проверяется и очищается. Это AST-дерево принимает планировщик – оптимизатор запросов, который создает план выполнения запроса. Этот план состоит из различных операторов — специализированных модулей выполнения, которые выполняют конкретную задачу преобразования данных. После создания плана запроса среда выполнения запроса выполняет план, созданный планировщиком.
Конвейерная и параллельная среды выполнения имеют одну и ту же архитектуру, когда вместо выполнения запросов по одной строке за раз, как в интервальной среде выполнения, используемой по умолчанию в Neo4j Community Edition, операторы сгруппированы в конвейеры, которые одновременно обрабатывают пакет строк.
Конвейерная и параллельная среды выполнения выполняют строки пакетом. Но конвейерная среда выполнения выполняет только один пакет за раз, тогда как параллельная среда выполнения выполняет несколько пакетов одновременно. Это обусловлено однопоточным характером конвейерной среды выполнения, когда каждый пакет обрабатывается одним потоком, назначенным одному ядру ЦП. Параллельная среда выполнения является многопоточной, позволяя одновременно обрабатывать несколько пакетов доступными процессорами. Поэтому именно параллельное выполнение дает пользователям Neo4j новую возможность использовать все доступные процессоры для ускорения обработки запросов.
Более того, способность параллельной среды выполнения использовать несколько процессоров делают ее идеальной для глобальных запросов, которые не указывают какой-либо конкретный узел в качестве отправной точки и продолжают проходить большую часть графа для выявления сложных закономерностей.
Таким образом, параллельная среда выполнения работает намного быстрее, обрабатывая множество задач конвейера одновременно, т.е. параллельно. Параллелизм достигается по двум направлениям:
- вертикально – задачи разных конвейеров могут выполняться параллельно, т.к. план выполнения запроса разбивается на большее количество меньших конвейеров, которые выполняются одновременно;
- горизонтально – несколько задач одного конвейера могут выполняться параллельно.
Впрочем, параллельное выполнение подходит не только для глобальных запросов, которые нацелены на большую часть графа. Это может повысить и производительность локальных запросов, привязанных к одному или нескольким узлам, если они представляют собой супер-узлы и/или запрос расширяется от локальных узлов до большой части графа.
Поскольку параллельная среда выполнения является модернизацией конвейерной, ее эффективность зависит от количества доступных процессоров: чем их больше, тем быстрее завершится запрос. Однако, недостаточно иметь на сервере много процессоров. Они также должны быть доступны для использования параллельными потоками выполнения. Это означает, что если Cypher-запросы выполняются в базе данных Neo4j с высоким уровнем параллелизма, где процессоры уже заняты другими операциями, преимущества параллельного выполнения не будут заметны. Кроме того, при использовании параллельной среды выполнения одновременно активны несколько потоков, поэтому для запросов может потребоваться больше динамической памяти. Как при этом избежать OOM-ошибки, читайте в нашей новой статье.
В заключение отметим, что конвейерная среда выполнения может повторно использовать возвращенный порядок строк при сканировании, не требуя сортировки. Параллельная среда выполнения пока не поддерживает порядок индексирования. Также параллельная среда выполнения не поддерживает операторы записи и не очень подходит для локальных Cypher-запросов к нескольким узлам графа. Поэтому именно конвейерная среда выполнения идеально подходит для высоких транзакционных рабочих нагрузок, где большое количество запросов одновременно выполняется многими пользователями в одной системе.
Таким образом, для выбора наиболее оптимального варианта следует определиться с превалирующими вариантами использования Neo4j, чтобы оптимально настроить среду выполнения Cypher-запросов. Как это сделать, читайте в нашей новой статье.
Узнайте больше про использование графовых алгоритмов и средств работы с ними для практического применения в реальных проектах аналитики больших данных на специализированных курсах нашего лицензированного учебного центра обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

