
Почему тормозит Cypher-запрос к Neo4j, как его отладить и чем оператор PROFILE отличается от EXPLAIN. Краткий ликбез с примерами выполнения запросов к графовой базе данных для аналитиков и разработчиков.
Как выполняются Cypher-запросы в Neo4j
Любой дата-аналитик и разработчик, работающий с базами данных, знает, что одной из самых частых причин медленного выполнения запроса к БД, является сам запрос, написанный неоптимально. Это означает, что порядок выполнения операторов не самый быстрый, например, из-за подзапросов с соединениями или неподходящей индексации. Для Cypher, который является языком запросов к графовой базе данных Neo4j, на скорость выполнения также влияет характер отслеживаемых отношений между узлами. Например, отследить узел с большим количеством входящих или исходящих связей довольно просто, а вот обратный запрос с отслеживанием отношений в обратном направлении становится очень большим и медленным.
Будучи декларативным языком запросов, Cypher подобно SQL, позволяет аналитику только описать интересующие закономерности, а база данных определит лучший способ найти данные. Базовый механизм запросов будет использовать статистику базы данных и информацию о схеме, чтобы определить наилучшую точку для начала обхода.
Запрос Cypher начинается с декларативного запроса, представленного в виде строки, описывающей шаблон графа, который необходимо сопоставить в базе данных. После анализа строка запроса проходит через оптимизатор (планировщик) запросов, который создает императивный логический план, для определения наиболее эффективного способа выполнения запроса с учетом текущего состояния базы данных. Соответствующая информация о текущем состоянии базы данных включает в себя доступные индексы и ограничения, а также различную статистику, поддерживаемую базой данных. Планировщик Cypher использует эту информацию, чтобы определить, какие шаблоны доступа создадут лучший план выполнения.
На заключительном этапе этот логический план превращается в исполняемый физический план, который фактически выполняет запрос к базе данных. Выполнение этого физического плана является задачей среды выполнения Cypher. Среда выполнения — это последний этап запроса Cypher, на котором планы запросов, полученные от планировщика, выполняются максимально быстро и эффективно.
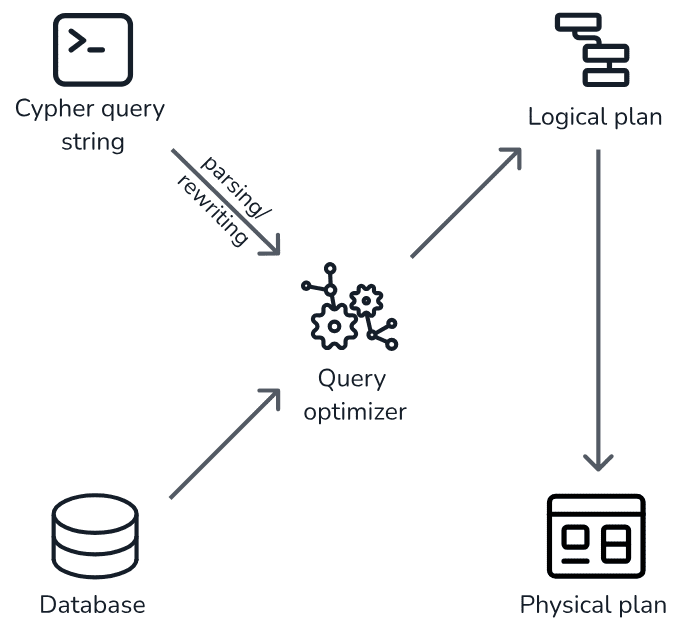
Планировщик Cypher создает логические планы, описывающие, как будет выполняться конкретный запрос. Этот план выполнения представляет собой двоичное дерево операторов, каждый из которых представляет собой специализированный модуль выполнения, отвечающий за определенный тип преобразования данных перед их передачей следующему оператору. Таким образом, планы выполнения, создаваемые планировщиком, определяют, какие операторы будут использоваться и в каком порядке для достижения цели, заявленной в исходном запросе.
Чтобы просмотреть план запроса, надо добавить к нему оператор EXPLAIN. Это не запустит запрос, а только покажет дерево операторов, используемых для поиска желаемого результата. Сделаем это на примере из недавней статьи про визуализацию анализа финансовых транзакций в Neo4j с помощью построения дэшбордов в NeoDash.
Операторы EXPLAIN и PROFILE
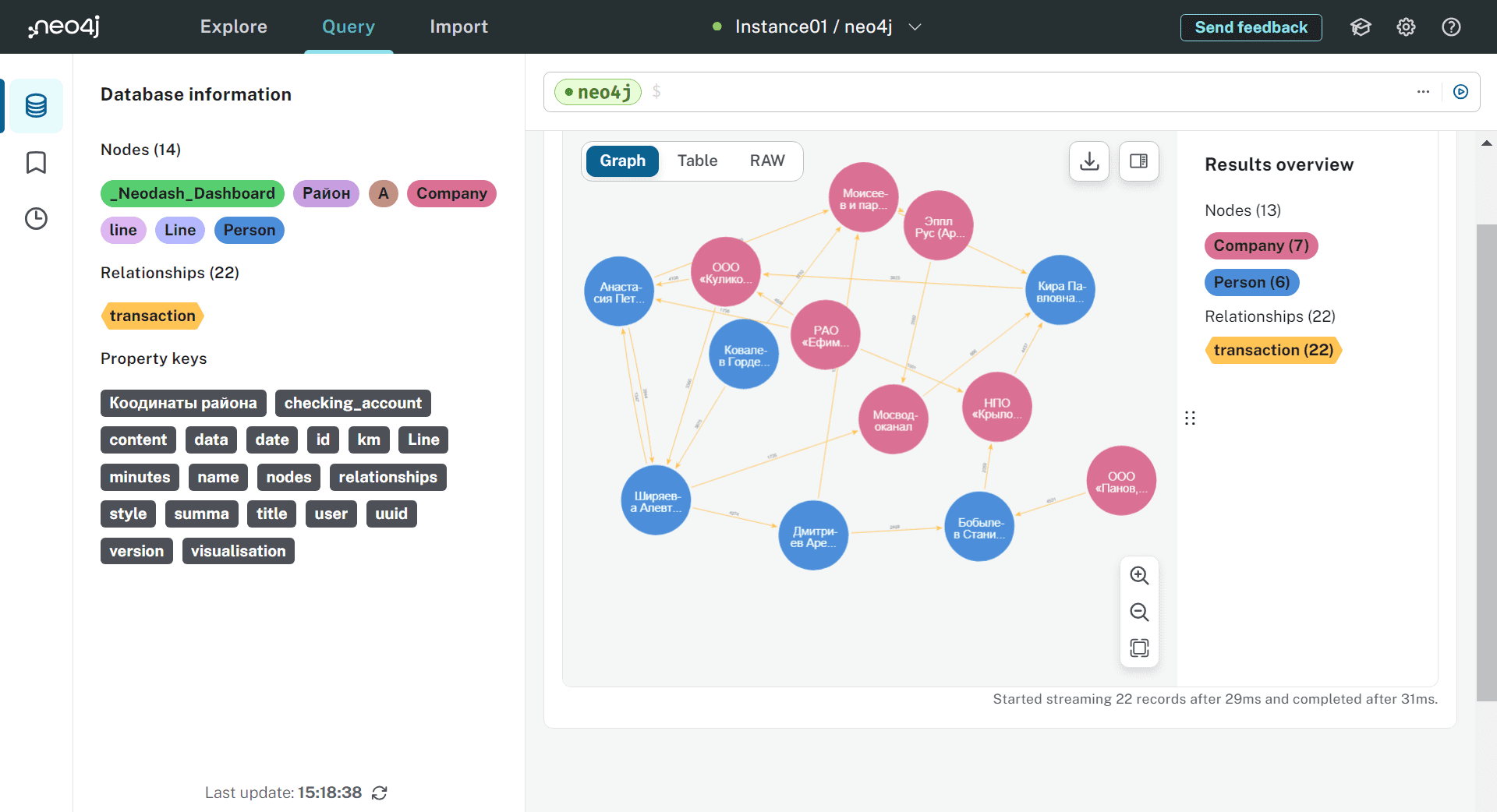
В качестве примера возьмем граф банковских транзакций между юрлицами (узлы с меткой Company) и физлицами, промаркированными метками Person. Каждый узел имеет название (в случае юрлиц) и имя (для физлица), а также номер расчетного счета. Связь между узлами означает совершенный денежный перевод, т.е. транзакцию на конкретную сумму и в определенную дату. Это два свойства связи. Для того, чтобы отобразить весь граф, достаточно следующего Cypher-запроса:
MATCH p=()-[:transaction]->() RETURN p;
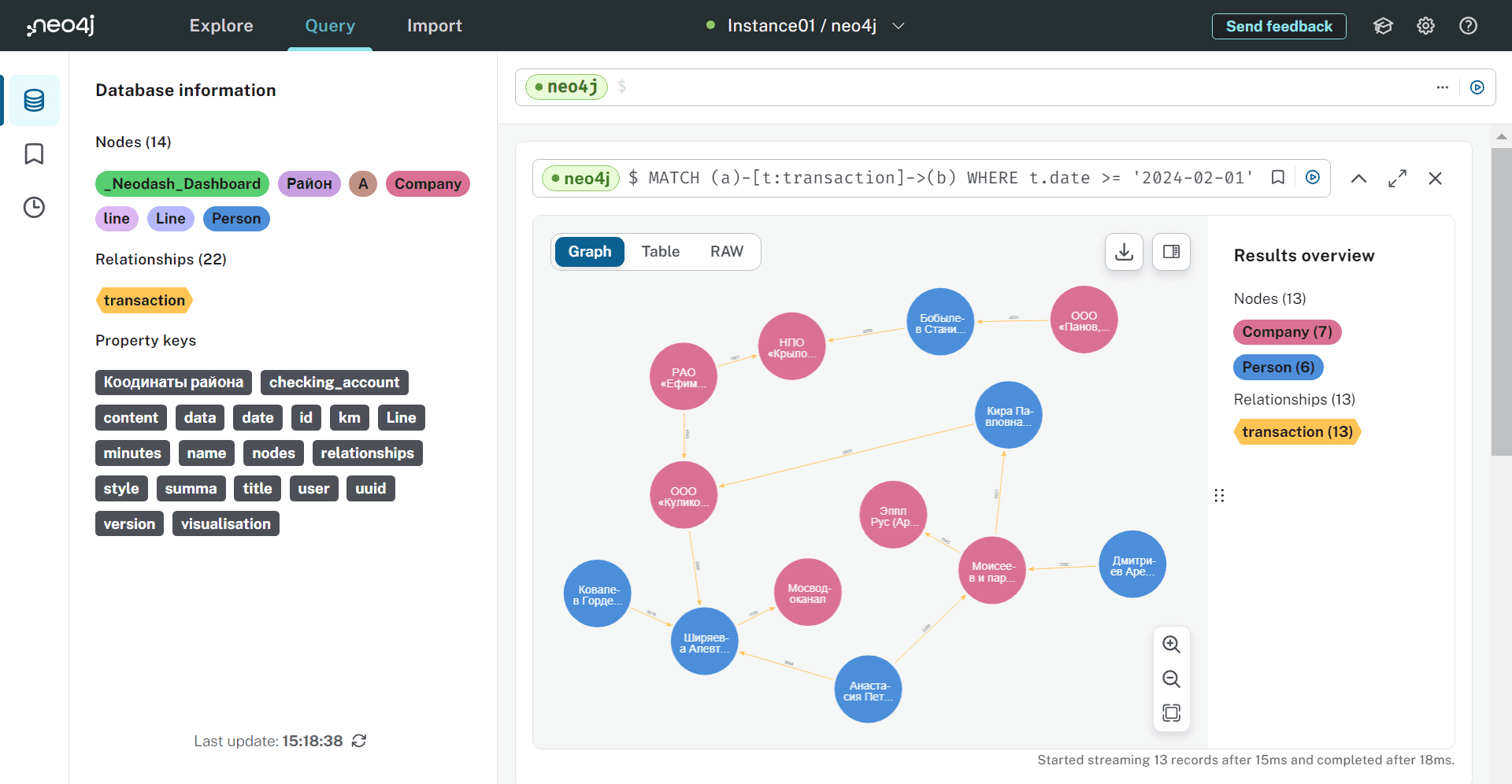
Усложним задачу, добавив в запрос фильтрацию. Например, показать все транзакции, совершенные с февраля 2024 года по настоящее время:
MATCH (a)-[t:transaction]->(b) WHERE t.date >= '2024-02-01' RETURN a, t, b
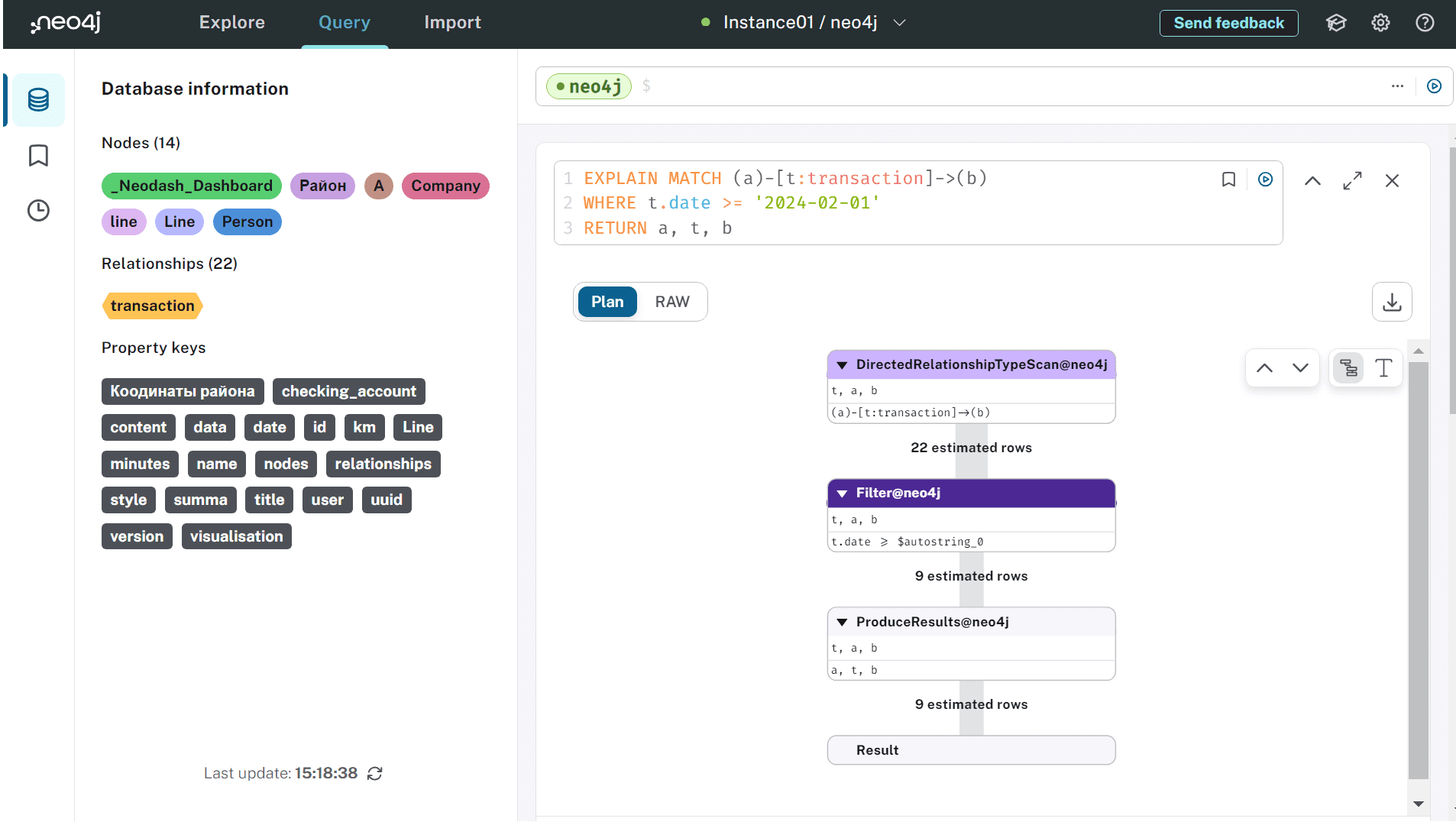
Теперь, чтобы посмотреть план выполнения запроса, добавим к нему оператор EXPLAIN:
EXPLAIN MATCH (a)-[t:transaction]->(b) WHERE t.date >= '2024-02-01' RETURN a, t, b
Результат показан в виде дерева операторов запроса.
Переключившись на RAW, можно найти план выполнения запроса в текстовом виде, представленный в разделе Summary как JSON-документ:
"plan": {
"operatorType": "ProduceResults@neo4j",
"identifiers": [
"t",
"a",
"b"
],
"arguments": {
"planner-impl": "IDP",
"Details": "a, t, b",
"planner-version": "5.18",
"string-representation": "Planner COST\n\nRuntime SLOTTED\n\nRuntime version 5.18\n\n+-------------------------------+----+--------------------------+----------------+\n| Operator | Id | Details | Estimated Rows |\n+-------------------------------+----+--------------------------+----------------+\n| +ProduceResults | 0 | a, t, b | 9 |\n| | +----+--------------------------+----------------+\n| +Filter | 1 | t.date >= $autostring_0 | 9 |\n| | +----+--------------------------+----------------+\n| +DirectedRelationshipTypeScan | 2 | (a)-[t:transaction]->(b) | 22 |\n+-------------------------------+----+--------------------------+----------------+\n\nTotal database accesses: ?\n",
"runtime-version": "5.18",
"runtime": "SLOTTED",
"Id": {
"low": 0,
"high": 0
},
"runtime-impl": "SLOTTED",
"EstimatedRows": 8.8,
"planner": "COST"
},
"children": [
{
"operatorType": "Filter@neo4j",
"identifiers": [
"t",
"a",
"b"
],
"arguments": {
"Details": "t.date >= $autostring_0",
"Id": {
"low": 1,
"high": 0
},
"EstimatedRows": 8.8
},
"children": [
{
"operatorType": "DirectedRelationshipTypeScan@neo4j",
"identifiers": [
"t",
"a",
"b"
],
"arguments": {
"Details": "(a)-[t:transaction]->(b)",
"Id": {
"low": 2,
"high": 0
},
"EstimatedRows": 22
},
"children": []
}
]
}
]
}
Планы выполнения запроса читаются снизу вверх. Это значит, что нужно начать с нижнего оператора и двигаться вверх, пока последний корневой оператор ProduceResults не сгенерирует читаемые для пользователя результаты. В моем примере сперва выполняется оператор DirectedRelationshipTypeScan, который извлекает все связи, а также их начальные и конечные узлы определенного типа из индекса типа отношений. Аргументы каждого оператора описывают детали его выполнения:
- id – уникальный идентификатор, присвоенный каждому оператору. Нет никаких гарантий относительно порядка идентификаторов, хотя они обычно начинаются с 0 у корневого оператора и увеличиваются до тех пор, пока не будет достигнут листовой оператор в начале дерева операторов.
- Details описывает, какую задачу выполняет каждый оператор;
- Estimated Rows показывает количество строк, которые, как ожидается, будут созданы каждым оператором. Эта оценка представляет собой приблизительное число, основанное на доступной статистической информации, и планировщик использует ее для выбора подходящего плана выполнения.
Статистическая информация, поддерживаемая Neo4j, включает в себя следующее: количество узлов, имеющих определенную метку, количество связей по типу, избирательность по индексу и количество связей по типу, заканчивающихся или начинающихся с узла с определенной меткой. Стоит отметить, что оценка запроса является отложенным вычислением (Lazy), поскольку большинство дочерних операторов передают свои выходные строки родительским сразу после их создания. Это означает, что дочерний оператор может не быть полностью исчерпан до того, как родительский начнет использовать входные строки, созданные дочерним элементом. Однако некоторым операторам, например, для агрегирования и сортировки, необходимо агрегировать все свои строки, прежде чем выдать выходные данные. Эти операторы называются нетерпеливыми (Eager). Таким операторам необходимо завершить выполнение полностью, прежде чем какие-либо строки будут отправлены их родителям в качестве входных данных, и иногда они необходимы для обеспечения правильной семантики Cypher.
Также представленный план выполнения запроса показывает, что средой выполнения является SLOTTED, т.е. с интервалами, что установлено по умолчанию для Neo4j Community Edition. Физический план, создаваемый средами выполнения с интервалами, представляет собой взаимно однозначное отображение логического плана, где каждый логический оператор сопоставляется с соответствующим физическим оператором, и операторы обрабатываются строка за строкой. При использовании SLOTTED-среды выполнения со слотами каждая переменная в запросе получает выделенный слот, который используется для доступа к данным, сопоставленным с данной переменной. Этот подход использует традиционную модель выполнения большинства баз данных, когда каждый оператор в дереве запроса извлекает строки данных из своего дочернего оператора с помощью функции виртуального вызова. Таким образом, данные перемещаются снизу вверх по плану выполнения, создавая поток данных.
Слотовая среда выполнения является интерпретируемой, то есть она интерпретирует логический план, отправленный планировщиком оператор за оператором. В целом это удобный и гибкий подход, способный обрабатывать все операторы и запросы, поскольку подобно интерпретируемым языкам программирования есть фаза планирования довольно коротка, поскольку не нужно генерировать весь код для запроса перед выполнением, в отличие от скомпилированных сред выполнения. Это полезно в работе с приложениями, которые генерируют короткие и некэшируемые запросы. Однако, непрерывный вызов виртуальных функций между каждым оператором использует циклы ЦП, что приводит к замедлению выполнения запроса. Кроме того, модель итератора может привести к плохой локальности данных, что может привести к замедлению выполнения запроса. Это связано с тем, что процесс извлечения отдельных строк от разных операторов затрудняет эффективное использование кэша ЦП. Подробнее о том, чем слотовая среда выполнения отличается от конвейерной и как ее сменить. читайте в новой статье.
Чтобы определить корневой оператор в плане запроса, базовый механизм запросов Cypher будет использовать статистику базы данных и информацию о схеме, чтобы определить, оптимальную точку начала обхода. Такие начальные узлы можно идентифицировать с помощью индексов (NodeIndexSeek), ограничений (NodeUniqueIndexSeek) или меток (NodeByLabelScan). Начиная с этих узлов, отношения будут расширяться по типам и направлениям, указанным в предложении MATCH, перед фильтрацией по свойствам отношения или меткам и свойствам узла.
Чтобы получить больше информации о плане выполнения запроса, заменим оператор EXPLAIN на PROFILE:
PROFILE MATCH (a)-[t:transaction]->(b) WHERE t.date >= '2024-02-01' RETURN a, t, b
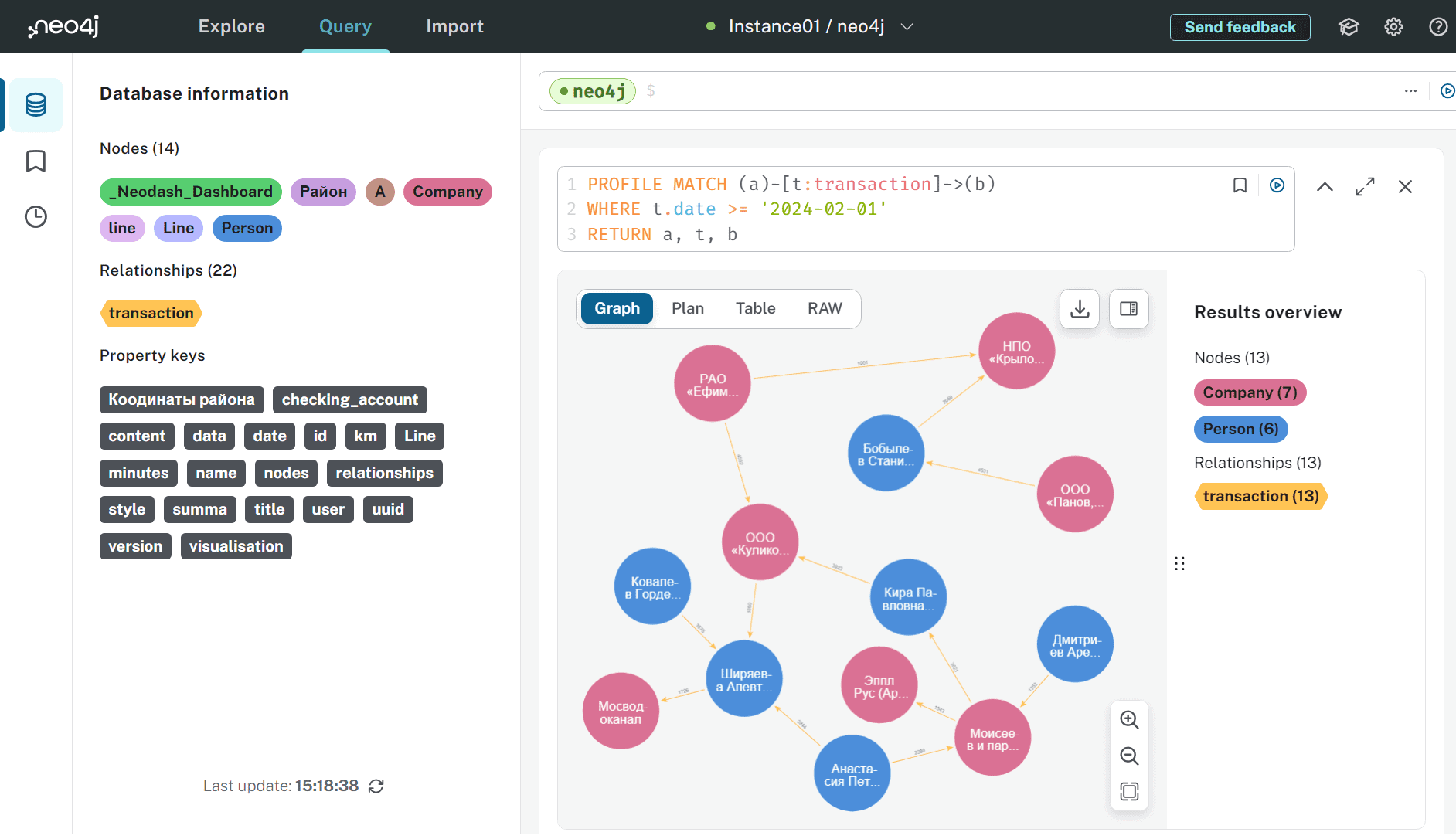
Результат показывает не только план выполнения запроса, но и сам граф, поскольку оператор PROFILE выполняет запрос и дает точные результаты. Сгенерированный план запроса намного подробнее, чем в случае EXPLAIN.
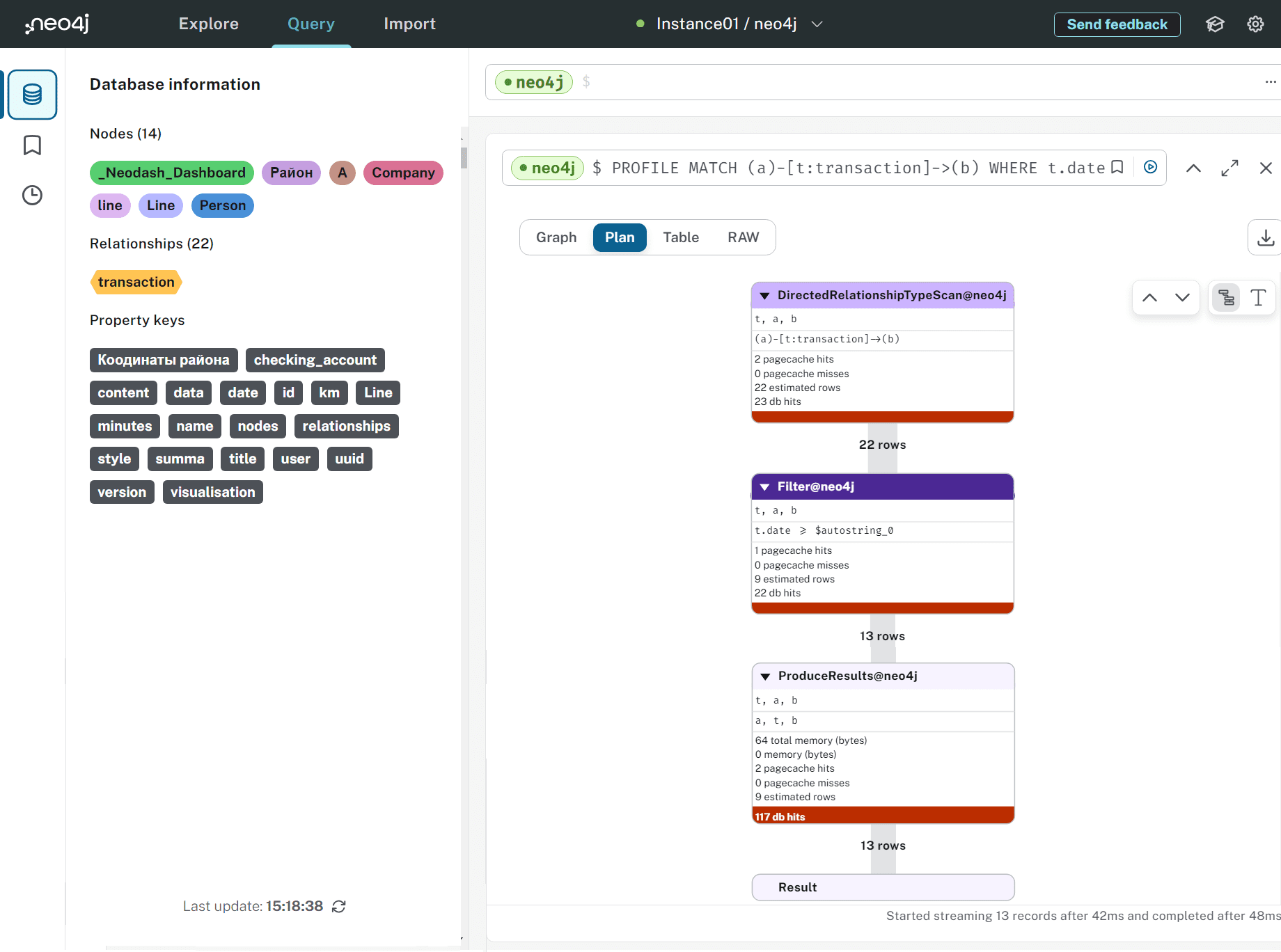
Сам план запроса в виде JSON-документа помимо плана также включает результаты планирования:
"plan": {
"operatorType": "ProduceResults@neo4j",
"identifiers": [
"t",
"a",
"b"
],
"arguments": {
"GlobalMemory": {
"low": 64,
"high": 0
},
"planner-impl": "IDP",
"Memory": {
"low": 0,
"high": 0
},
"string-representation": "Planner COST\n\nRuntime SLOTTED\n\nRuntime version 5.18\n\n+-------------------------------+----+--------------------------+----------------+------+---------+----------------+------------------------+\n| Operator | Id | Details | Estimated Rows | Rows | DB Hits | Memory (Bytes) | Page Cache Hits/Misses |\n+-------------------------------+----+--------------------------+----------------+------+---------+----------------+------------------------+\n| +ProduceResults | 0 | a, t, b | 9 | 13 | 117 | 0 | 2/0 |\n| | +----+--------------------------+----------------+------+---------+----------------+------------------------+\n| +Filter | 1 | t.date >= $autostring_0 | 9 | 13 | 22 | | 1/0 |\n| | +----+--------------------------+----------------+------+---------+----------------+------------------------+\n| +DirectedRelationshipTypeScan | 2 | (a)-[t:transaction]->(b) | 22 | 22 | 23 | | 2/0 |\n+-------------------------------+----+--------------------------+----------------+------+---------+----------------+------------------------+\n\nTotal database accesses: 162, total allocated memory: 64\n",
"runtime": "SLOTTED",
"runtime-impl": "SLOTTED",
"DbHits": {
"low": 117,
"high": 0
},
"Details": "a, t, b",
"planner-version": "5.18",
"runtime-version": "5.18",
"Id": {
"low": 0,
"high": 0
},
"EstimatedRows": 8.8,
"planner": "COST",
"PageCacheMisses": {
"low": 0,
"high": 0
},
"Rows": {
"low": 13,
"high": 0
},
"PageCacheHits": {
"low": 2,
"high": 0
}
},
"children": [
{
"operatorType": "Filter@neo4j",
"identifiers": [
"t",
"a",
"b"
],
"arguments": {
"Details": "t.date >= $autostring_0",
"Id": {
"low": 1,
"high": 0
},
"PageCacheMisses": {
"low": 0,
"high": 0
},
"EstimatedRows": 8.8,
"DbHits": {
"low": 22,
"high": 0
},
"Rows": {
"low": 13,
"high": 0
},
"PageCacheHits": {
"low": 1,
"high": 0
}
},
"children": [
{
"operatorType": "DirectedRelationshipTypeScan@neo4j",
"identifiers": [
"t",
"a",
"b"
],
"arguments": {
"Details": "(a)-[t:transaction]->(b)",
"Id": {
"low": 2,
"high": 0
},
"PageCacheMisses": {
"low": 0,
"high": 0
},
"EstimatedRows": 22,
"DbHits": {
"low": 23,
"high": 0
},
"Rows": {
"low": 22,
"high": 0
},
"PageCacheHits": {
"low": 2,
"high": 0
}
},
"children": []
}
]
}
]
},
"profile": {
"operatorType": "ProduceResults@neo4j",
"identifiers": [
"t",
"a",
"b"
],
"arguments": {
"GlobalMemory": {
"low": 64,
"high": 0
},
"planner-impl": "IDP",
"Memory": {
"low": 0,
"high": 0
},
"string-representation": "Planner COST\n\nRuntime SLOTTED\n\nRuntime version 5.18\n\n+-------------------------------+----+--------------------------+----------------+------+---------+----------------+------------------------+\n| Operator | Id | Details | Estimated Rows | Rows | DB Hits | Memory (Bytes) | Page Cache Hits/Misses |\n+-------------------------------+----+--------------------------+----------------+------+---------+----------------+------------------------+\n| +ProduceResults | 0 | a, t, b | 9 | 13 | 117 | 0 | 2/0 |\n| | +----+--------------------------+----------------+------+---------+----------------+------------------------+\n| +Filter | 1 | t.date >= $autostring_0 | 9 | 13 | 22 | | 1/0 |\n| | +----+--------------------------+----------------+------+---------+----------------+------------------------+\n| +DirectedRelationshipTypeScan | 2 | (a)-[t:transaction]->(b) | 22 | 22 | 23 | | 2/0 |\n+-------------------------------+----+--------------------------+----------------+------+---------+----------------+------------------------+\n\nTotal database accesses: 162, total allocated memory: 64\n",
"runtime": "SLOTTED",
"runtime-impl": "SLOTTED",
"DbHits": {
"low": 117,
"high": 0
},
"Details": "a, t, b",
"planner-version": "5.18",
"runtime-version": "5.18",
"Id": {
"low": 0,
"high": 0
},
"EstimatedRows": 8.8,
"planner": "COST",
"PageCacheMisses": {
"low": 0,
"high": 0
},
"Rows": {
"low": 13,
"high": 0
},
"PageCacheHits": {
"low": 2,
"high": 0
}
},
"dbHits": 117,
"rows": 13,
"pageCacheMisses": 0,
"pageCacheHits": 2,
"pageCacheHitRatio": 1,
"time": 0,
"children": [
{
"operatorType": "Filter@neo4j",
"identifiers": [
"t",
"a",
"b"
],
"arguments": {
"Details": "t.date >= $autostring_0",
"Id": {
"low": 1,
"high": 0
},
"PageCacheMisses": {
"low": 0,
"high": 0
},
"EstimatedRows": 8.8,
"DbHits": {
"low": 22,
"high": 0
},
"Rows": {
"low": 13,
"high": 0
},
"PageCacheHits": {
"low": 1,
"high": 0
}
},
"dbHits": 22,
"rows": 13,
"pageCacheMisses": 0,
"pageCacheHits": 1,
"pageCacheHitRatio": 1,
"time": 0,
"children": [
{
"operatorType": "DirectedRelationshipTypeScan@neo4j",
"identifiers": [
"t",
"a",
"b"
],
"arguments": {
"Details": "(a)-[t:transaction]->(b)",
"Id": {
"low": 2,
"high": 0
},
"PageCacheMisses": {
"low": 0,
"high": 0
},
"EstimatedRows": 22,
"DbHits": {
"low": 23,
"high": 0
},
"Rows": {
"low": 22,
"high": 0
},
"PageCacheHits": {
"low": 2,
"high": 0
}
},
"dbHits": 23,
"rows": 22,
"pageCacheMisses": 0,
"pageCacheHits": 2,
"pageCacheHitRatio": 1,
"time": 0,
"children": []
}
]
}
]
}
Поскольку оператор PROFILE запускает выполнение запроса, также можно посмотреть результаты в табличном виде.
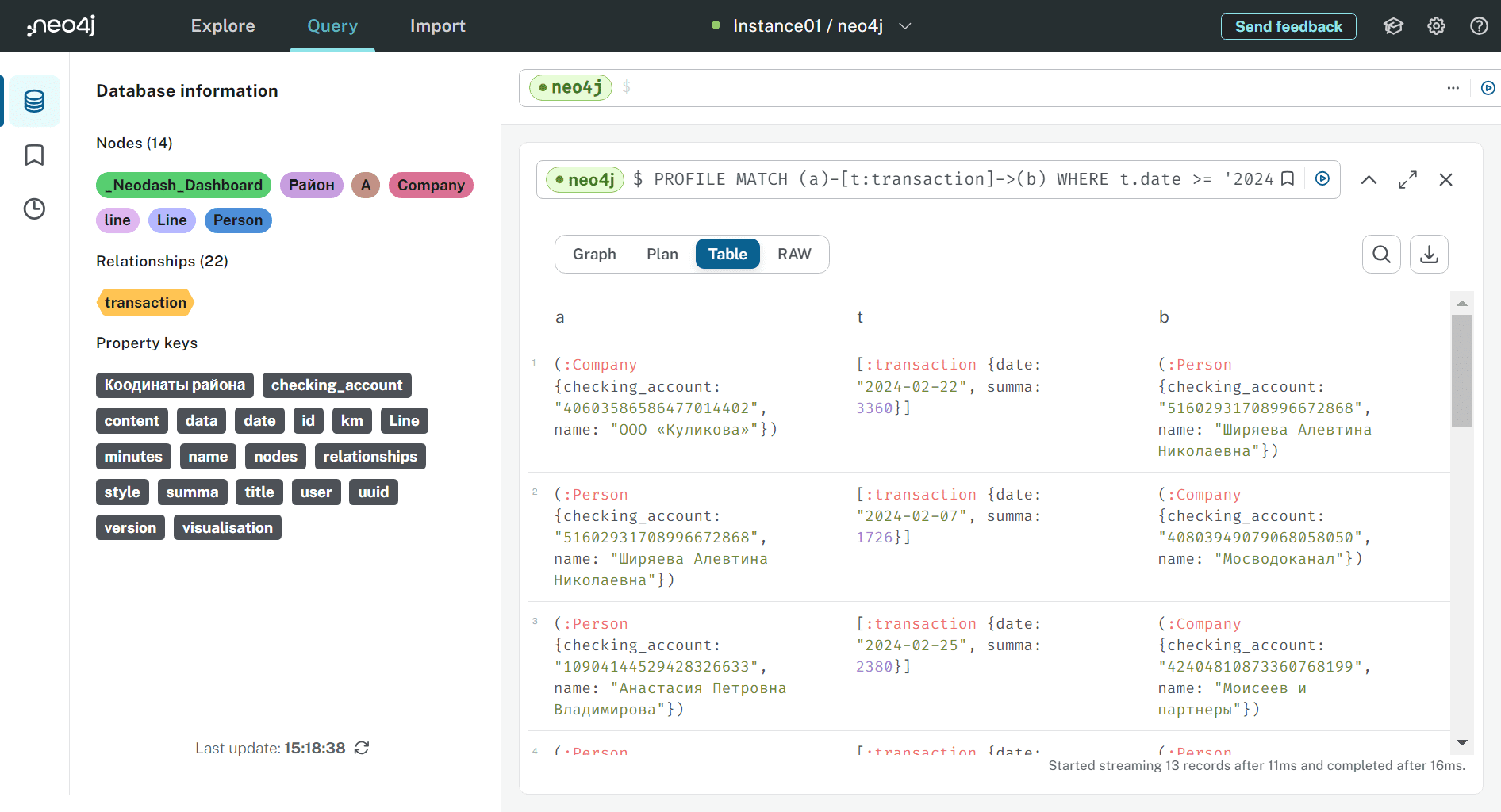
Таким образом, операторы EXPLAIN и PROFILE, позволяющие увидеть план выполнения запроса будут полезны при отладке и оптимизации, например, чтобы переформулировать запрос с условием WITH, заставив планировщик выбрать конкретный индекс.
Узнайте больше про графовые СУБД и тонкости работы с ними для аналитики больших данных на специализированных курсах нашего лицензированного учебного центра обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

