 1652
1652 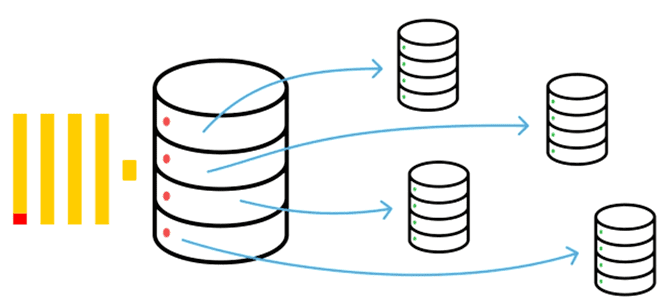
Как повысить производительность ClickHouse с помощью горизонтального масштабирования, разделив данные на шарды: принципы шардирования, стратегии выбора ключа, особенности работы с distributed-таблицами и настройки конфигураций сервера.
Шардирование в ClickHouse
Именно хранилище данных всегда является узким местом любой системы. Поэтому именно его надо расширить для повышения производительности. Это можно сделать с помощью шардирования – горизонтального масштабирования за счет физического разделения данных на разные фрагменты (шарды, shards), которые располагаются на разных машинах. При этом создается большая распределенная distributed-таблица, которая маршрутизирует запросы к таблицам по шардам, обращаться к данным в которых можно также и напрямую.
В колоночной СУБД ClickHouse шардирование позволяет распределить фрагменты данных из одной базы по разным узлам кластера, увеличивая пропускную способность и снижая задержку обработки данных. Шард ClickHouse – это группа копий данных (реплик) для обеспечения отказоустойчивости СУБД, он состоит из одного или нескольких хостов-реплик. Поскольку шарды содержат разные части данных, для получения всех данных, нужно обращаться ко всем шардам. Для обеспечения надежности и повышения доступности данные реплицируются, т.е. дублируются по репликам. Запрос на запись или чтение в шард может быть отправлен на любую его реплику.
Поскольку в Clickhouse, в отличие от Greenplum, нецентрализованная архитектура, SQL-запрос выполняется параллельно, т.е. одновременно на всех сегментах. Например, при вставке с помощью INSERT-запроса данные асинхронно копируются с реплики, на которой он выполнен. А вот запрос на выборку с оператором SELECT отправляет подзапросы на все шарды кластера, независимо от распределения данных. Агрегатные же запросы к шардированным таблицам с оператором GROUP BY в ClickHouse выполняются так: сперва происходит агрегация на отдельных узлах и эти результаты передаются узлу-инициатору запроса для общей сборки. Для этого используется специальный табличный движок Distributed, который не обеспечивает хранение данных, а маршрутизирует запросы на шардированные таблицы с последующей обработкой результатов.
Записывать данные в шарды можно двумя способами:
- через distributed-таблицу по ключу шардирования, основанном на хэш-функции конкретного поля, диапазоне значений или вычисляемом динамически, в зависимости от нагрузки;
- непосредственное обращение к шардированным таблицам, чтобы потом считывать данные через distributed-таблицу.
При вставке данных в distributed-таблицу они сперва записываются в файловую систему, а потом в фоновом режиме отправляются на удалённые серверы с периодичностью, заданной в конфигурациях distributed_background_insert_sleep_time_ms и distributed_background_insert_max_sleep_time_ms. Изначально каждый файл со вставленными данными отправляется отдельно, но это не очень эффективно при массовой записи. Чтобы ускорить этот процесс, можно включить пакетную отправку данных с помощью конфигурации distributed_background_insert_batch. Проверить, что данные отправлены успешно можно, посмотрев список файлов в каталоге таблицы /var/lib/clickhouse/data/database/table/. Количество потоков для выполнения фоновых задач определяется в конфигурации background_distributed_schedule_pool_size.
Рекомендуется выбирать ключ шардирования таким образом, чтобы равномерно распределить данные по всем шардам, обеспечив их взаимную независимость. Ключ шардирования, как и движок Distributed указывается при создании таблицы в DDL-запросе CREATE TABLE, что мы уже рассматривали здесь:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]]) [SETTINGS name=value, ...]
Особенности работы с Distributed-движком
Если нужно каждый раз отправлять запрос на неизвестный набор шардов и реплик, вместо создания Distributed-таблицы можно использовать табличную функцию remote. Она работает аналогично распределенной таблице, однако менее эффективна, поскольку соединения с серверами устанавливаются каждый раз заново при каждом запросе. А при указании сервера по имени надо сперва найти его. При этом не ведётся сквозной подсчёт ошибок при работе с разными репликами. Поэтому рекомендуется создавать distributed-таблицу вместо использования табличной функции remote. Впрочем, remote можно применять для разработки и исследований, а также в случае распределенных запросов к Clickhouse, которые выполняются нечасто и/или набор серверов нестабилен и каждый раз определяется заново.
Несмотря на свое название, движок Distributed может работать не только с кластером из нескольких машин, но и с локальным сервером. Причем кластер является неэластичным: необходимо прописать его конфигурацию в конфигурационный файл каждого сервера, чтобы обновлять весь кластер без перезапуска узла. Этот конфигурационный xml-файл выглядит так:
<remote_servers>
<anna_cluster>
<shard>
<!-- Не обязательно. Вес шарда при записи данных. По умолчанию, 1. -->
<weight>1</weight>
<!-- Не обязательно. Записывать ли данные только на одну, любую из реплик. По умолчанию, false - записывать данные на все реплики. -->
<internal_replication>false</internal_replication>
<replica>
<!-- Не обязательно. Приоритет реплики для балансировки нагрузки. По умолчанию : 1 (меньшее значение - больший приоритет). -->
<priority>1</priority>
<host>example01-01-1</host>
<port>9000</port>
</replica>
<replica>
<host>example01-01-2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<weight>2</weight>
<internal_replication>false</internal_replication>
<replica>
<host>example01-02-1</host>
<port>9000</port>
</replica>
<replica>
<host>example01-02-2</host>
<port>9000</port>
</replica>
</shard>
<shard>
<weight>3</weight>
<internal_replication>false</internal_replication>
<replica>
<host>example01-03-1</host>
<port>9000</port>
</replica>
<replica>
<host>example01-03-2</host>
<port>9000</port>
</replica>
</shard>
</ anna_cluster >
</remote_servers>
В этом примере задан кластер с именем anna_cluster из трех шардов, каждый из которых имеет 2 реплики. Для каждого сервера необходимо указать сокет, т.е. хост (домен или адрес удалённого сервера) и TCP-порт межсерверного взаимодействия, а также опционально учетные данные (user, password), параметры безопасности (secure) и сжатия (compression). При указании домена для хоста при старте сервера необходимо выполнить DNS-запрос, результат которого запоминается и используется на протяжении работы сервера. Если этот DNS-запрос не выполнился, то сервер не запустится. Поэтому при изменении DNS-записи необходима перезагрузка сервера. Также вместо домена можно указать IP-адрес версии 4 или 6. TCP-порт обычно задается равным 9000.
Учетные данные и доступы для соединения с удалённым сервером настраиваются в xml-файле users. По умолчанию там задан пользователь default, который должен иметь доступ для соединения с указанным сервером. Там же задается пароль в открытом виде, по умолчанию отсутствует. Если нужно защитить соединение с помощью криптографического протокола, следует задать параметр secure, который указывает на SSL-шифрование. При это порт используется другой порт, 9440 вместо 9000. Сервер будет слушать TCP-порт <tcp_port_secure>9440</tcp_port_secure> с корректными настройками SSL-сертификатов. Сжатие данных (compression) включено по умолчанию.
Для каждого шарда можно любое количество реплик в конфигурационном файле. Количество кластеров в конфигурации тоже не ограничено.
Освойте администрирование и эксплуатацию ClickHouse для аналитики больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники

